Einschrittverfahren
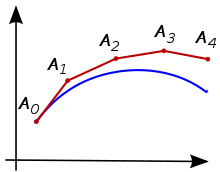
 aus nacheinander Punkte
aus nacheinander Punkte  ,
,
 usw. bestimmt werden
usw. bestimmt werdenEinschrittverfahren sind in der numerischen Mathematik neben den Mehrschrittverfahren eine große Gruppe von Rechenverfahren zur Lösung von Anfangswertproblemen. Diese Aufgabenstellung, bei der eine gewöhnliche Differentialgleichung zusammen mit einer Startbedingung gegeben ist, spielt in allen Natur- und Ingenieurwissenschaften eine zentrale Rolle und gewinnt beispielsweise auch in den Wirtschafts- und Sozialwissenschaften immer mehr an Bedeutung. Anfangswertprobleme werden verwendet, um dynamische Vorgänge zu analysieren, zu simulieren oder vorherzusagen.
Die namensgebende Grundidee der Einschrittverfahren ist, dass sie ausgehend von dem gegebenen Anfangspunkt Schritt für Schritt entlang der gesuchten Lösung Näherungspunkte berechnen. Dabei verwenden sie jeweils nur die zuletzt bestimmte Näherung für den nächsten Schritt, im Gegensatz zu den Mehrschrittverfahren, die auch weiter zurückliegende Punkte in die Rechnung miteinbeziehen. Die Einschrittverfahren lassen sich grob in zwei Gruppen einteilen: in die expliziten Verfahren, die die neue Näherung direkt aus der alten berechnen, und in die impliziten Verfahren, bei denen dazu eine Gleichung gelöst werden muss. Letztere eignen sich auch für sogenannte steife Anfangswertprobleme.
Das einfachste und älteste Einschrittverfahren, das explizite Euler-Verfahren, wurde 1768 von Leonhard Euler veröffentlicht. Nachdem 1883 eine Gruppe von Mehrschrittverfahren vorgestellt worden war, entwickelten um 1900 Carl Runge, Karl Heun und Wilhelm Kutta deutliche Verbesserungen des eulerschen Verfahrens. Aus diesen ging die große Gruppe der Runge-Kutta-Verfahren hervor, die die wichtigste Klasse von Einschrittverfahren bildet. Weitere Entwicklungen des 20. Jahrhunderts sind beispielsweise die Idee der Extrapolation, vor allem aber Überlegungen zur Schrittweitensteuerung, also zur Wahl geeigneter Längen der einzelnen Schritte eines Verfahrens. Diese Konzepte bilden die Grundlage, um schwierige Anfangswertprobleme, wie sie in modernen Anwendungen auftreten, effizient und mit der benötigten Genauigkeit durch Computerprogramme lösen zu können.
Einführung
Gewöhnliche Differentialgleichungen
Die Entwicklung der Differential- und Integralrechnung durch den englischen Physiker und Mathematiker Isaac Newton und unabhängig davon durch den deutschen Universalgelehrten Gottfried Wilhelm Leibniz im letzten Drittel des 17. Jahrhunderts war ein wesentlicher Impuls für die Mathematisierung der Wissenschaft in der frühen Neuzeit. Diese Methoden bildeten den Startpunkt des mathematischen Teilgebiets der Analysis und sind in allen Natur- und Ingenieurwissenschaften von zentraler Bedeutung. Während Leibniz von dem geometrischen Problem, Tangenten an gegebene Kurven zu bestimmen, zur Differentialrechnung geführt wurde, ging Newton von der Fragestellung aus, wie sich Änderungen einer physikalischen Größe zu einem bestimmten Zeitpunkt bestimmen lassen.
Zum Beispiel ergibt sich bei der Bewegung eines Körpers dessen
Durchschnittsgeschwindigkeit einfach als die zurückgelegte Strecke dividiert
durch die dafür benötigte Zeit. Um jedoch die Momentangeschwindigkeit
 des Körpers zu einem bestimmten Zeitpunkt
des Körpers zu einem bestimmten Zeitpunkt  mathematisch zu formulieren, ist ein Grenzübergang notwendig: Man betrachtet
kurze Zeitspannen der Länge
mathematisch zu formulieren, ist ein Grenzübergang notwendig: Man betrachtet
kurze Zeitspannen der Länge  ,
die dabei zurückgelegten Wegstrecken
,
die dabei zurückgelegten Wegstrecken  und die zugehörigen Durchschnittsgeschwindigkeiten
und die zugehörigen Durchschnittsgeschwindigkeiten  .
Wenn man nun die Zeitspanne
gegen null konvergieren lässt und wenn sich dabei die
Durchschnittsgeschwindigkeiten ebenfalls einem festen Wert annähern,
dann wird dieser Wert die (Momentan-)Geschwindigkeit
zu dem gegebenen Zeitpunkt
genannt. Bezeichnet
.
Wenn man nun die Zeitspanne
gegen null konvergieren lässt und wenn sich dabei die
Durchschnittsgeschwindigkeiten ebenfalls einem festen Wert annähern,
dann wird dieser Wert die (Momentan-)Geschwindigkeit
zu dem gegebenen Zeitpunkt
genannt. Bezeichnet  die Position des Körpers zur Zeit ,
dann schreibt man
die Position des Körpers zur Zeit ,
dann schreibt man  und nennt
und nennt  die Ableitung
von
die Ableitung
von  .
.
Der entscheidende Schritt in die Richtung der Differentialgleichungsmodelle
ist nun die umgekehrte Fragestellung: Im Beispiel des bewegten Körpers sei also
zu jedem Zeitpunkt
die Geschwindigkeit
bekannt und daraus soll seine Position
bestimmt werden. Es ist anschaulich klar, dass zusätzlich die Anfangsposition
des Körpers zu einem Zeitpunkt  bekannt sein muss, um dieses Problem eindeutig lösen zu können. Es ist also eine
Funktion
mit
bekannt sein muss, um dieses Problem eindeutig lösen zu können. Es ist also eine
Funktion
mit  gesucht, die die Anfangsbedingung
gesucht, die die Anfangsbedingung  mit gegebenen Werten
und
mit gegebenen Werten
und  erfüllt.
erfüllt.
Im Beispiel der Bestimmung der Position
eines Körpers aus seiner Geschwindigkeit ist die Ableitung der gesuchten
Funktion explizit gegeben. Meist liegt jedoch der wichtige allgemeine Fall
gewöhnlicher Differentialgleichungen für eine gesuchte Größe  vor: Aufgrund der Naturgesetze oder der Modellannahmen ist ein
Funktionszusammenhang bekannt, der angibt, wie die Ableitung
vor: Aufgrund der Naturgesetze oder der Modellannahmen ist ein
Funktionszusammenhang bekannt, der angibt, wie die Ableitung  der zu bestimmenden Funktion aus
und aus dem (unbekannten) Wert
der zu bestimmenden Funktion aus
und aus dem (unbekannten) Wert  berechnet werden kann. Zusätzlich muss wieder eine Anfangsbedingung
gegeben sein, die beispielsweise aus einer Messung der gesuchten Größe zu einem
fest gewählten Zeitpunkt erhalten werden kann. Zusammengefasst liegt also der
folgende allgemeine Aufgabentyp vor: Man finde die Funktion ,
die die Gleichungen
berechnet werden kann. Zusätzlich muss wieder eine Anfangsbedingung
gegeben sein, die beispielsweise aus einer Messung der gesuchten Größe zu einem
fest gewählten Zeitpunkt erhalten werden kann. Zusammengefasst liegt also der
folgende allgemeine Aufgabentyp vor: Man finde die Funktion ,
die die Gleichungen

erfüllt, wobei  eine gegebene Funktion ist.
eine gegebene Funktion ist.

Ein einfaches Beispiel ist eine Größe ,
die exponentiell
wächst. Das bedeutet, dass die momentane Änderung, also die Ableitung
proportional
zu
selbst ist. Es gilt also  mit einer Wachstumsrate
mit einer Wachstumsrate  und beispielsweise einer Anfangsbedingung
und beispielsweise einer Anfangsbedingung  .
Die gesuchte Lösung
lässt sich in diesem Fall bereits mit elementarer Differentialrechnung finden
und mithilfe der Exponentialfunktion
angeben: Es gilt
.
Die gesuchte Lösung
lässt sich in diesem Fall bereits mit elementarer Differentialrechnung finden
und mithilfe der Exponentialfunktion
angeben: Es gilt  .
.
Die gesuchte Funktion
in einer Differentialgleichung kann vektorwertig
sein, das heißt, für jedes
kann  ein Vektor mit
ein Vektor mit
 Komponenten sein. Man spricht dann auch von einem -dimensionalen
Differentialgleichungssystem. Im Anschauungsfall eines bewegten Körpers ist dann
seine Position im -dimensionalen
euklidischen
Raum und
seine Geschwindigkeit
zur Zeit .
Durch die Differentialgleichung ist also in jedem Zeit- und Raumpunkt die
Geschwindigkeit der gesuchten Bahnkurve
mit Richtung und Betrag vorgegeben. Daraus soll die Bahn selbst berechnet
werden.
Komponenten sein. Man spricht dann auch von einem -dimensionalen
Differentialgleichungssystem. Im Anschauungsfall eines bewegten Körpers ist dann
seine Position im -dimensionalen
euklidischen
Raum und
seine Geschwindigkeit
zur Zeit .
Durch die Differentialgleichung ist also in jedem Zeit- und Raumpunkt die
Geschwindigkeit der gesuchten Bahnkurve
mit Richtung und Betrag vorgegeben. Daraus soll die Bahn selbst berechnet
werden.
Grundidee der Einschrittverfahren
Bei der oben als Beispiel betrachteten einfachen Differentialgleichung des
exponentiellen Wachstums ließ sich die Lösungsfunktion direkt angeben. Das ist
bei komplizierteren Problemen im Allgemeinen nicht mehr möglich. Man kann dann
zwar unter gewissen Zusatzvoraussetzungen an die Funktion
zeigen, dass eine eindeutig bestimmte Lösung des Anfangswertproblems existiert;
diese kann aber dann nicht mehr durch Lösungsverfahren der Analysis (wie
beispielsweise Trennung
der Variablen, einen Exponentialansatz
oder Variation
der Konstanten) explizit berechnet werden. In diesem Fall können numerische
Verfahren verwendet werden, um Näherungen für die gesuchte Lösung zu bestimmen.
Die Verfahren zur numerischen Lösung von Anfangswertproblemen gewöhnlicher
Differentialgleichung lassen sich grob in zwei große Gruppen einteilen: die
Einschritt- und die Mehrschrittverfahren. Beiden Gruppen ist gemeinsam, dass sie
schrittweise Näherungen  für die gesuchten Funktionswerte
für die gesuchten Funktionswerte  an Stellen
an Stellen  berechnen. Die definierende Eigenschaft der Einschrittverfahren ist dabei, dass
zur Bestimmung der folgenden Näherung
berechnen. Die definierende Eigenschaft der Einschrittverfahren ist dabei, dass
zur Bestimmung der folgenden Näherung  nur die „aktuelle“ Näherung
nur die „aktuelle“ Näherung  verwendet wird. Bei Mehrschrittverfahren gehen im Gegensatz dazu zusätzlich
bereits zuvor berechnete Näherungen mit ein; ein Dreischrittverfahren würde also
beispielsweise außer
auch noch
verwendet wird. Bei Mehrschrittverfahren gehen im Gegensatz dazu zusätzlich
bereits zuvor berechnete Näherungen mit ein; ein Dreischrittverfahren würde also
beispielsweise außer
auch noch  und
und  zur Bestimmung der neuen Näherung
verwenden.
zur Bestimmung der neuen Näherung
verwenden.
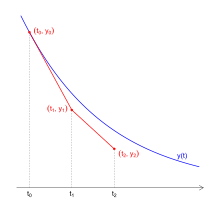
Das einfachste und grundlegendste Einschrittverfahren ist das explizite
Euler-Verfahren, das der Schweizer Mathematiker und Physiker Leonhard Euler 1768 in
seinem Lehrbuch Institutiones Calculi Integralis vorstellte.
Die Idee dieser Methode ist es, die gesuchte Lösung durch eine stückweise
lineare Funktion anzunähern, bei der in jedem Schritt von der Stelle  zur Stelle
zur Stelle  die Steigung des Geradenstücks durch
die Steigung des Geradenstücks durch  gegeben ist. Genauer betrachtet: Durch die Problemstellung ist bereits ein Wert
der gesuchten Funktion gegeben, nämlich
gegeben ist. Genauer betrachtet: Durch die Problemstellung ist bereits ein Wert
der gesuchten Funktion gegeben, nämlich  .
Aber auch die Ableitung an dieser Stelle ist bekannt, denn es gilt
.
Aber auch die Ableitung an dieser Stelle ist bekannt, denn es gilt  .
Damit kann die Tangente an den Graphen der Lösungsfunktion bestimmt und als
Näherung verwendet werden. An der Stelle
.
Damit kann die Tangente an den Graphen der Lösungsfunktion bestimmt und als
Näherung verwendet werden. An der Stelle  ergibt sich mit der Schrittweite
ergibt sich mit der Schrittweite 
 .
.
Dieses Vorgehen kann nun in den folgenden Schritten fortgesetzt werden. Insgesamt ergibt sich damit für das explizite Euler-Verfahren die Rechenvorschrift

mit den Schrittweiten  .
.
Das explizite Euler-Verfahren ist der Ausgangspunkt für zahlreiche
Verallgemeinerungen, bei denen die Steigung ,
durch Steigungen ersetzt wird, die das Verhalten der Lösung zwischen den Stellen
und
genauer annähern. Eine zusätzliche Idee für Einschrittverfahren bringt das
implizite Eulerverfahren, das  als Steigung verwendet. Diese Wahl erscheint auf den ersten Blick wenig
geeignet, da ja
unbekannt ist. Als Verfahrensschritt erhält man aber nun die Gleichung
als Steigung verwendet. Diese Wahl erscheint auf den ersten Blick wenig
geeignet, da ja
unbekannt ist. Als Verfahrensschritt erhält man aber nun die Gleichung

aus der
(gegebenenfalls durch ein numerisches Verfahren) berechnet werden kann. Wählt
man beispielsweise als Steigung das arithmetische
Mittel aus den Steigungen des expliziten und des impliziten
Euler-Verfahrens, so erhält man das implizite Trapez-Verfahren.
Aus diesem lässt sich wiederum ein explizites Verfahren gewinnen, wenn man zum
Beispiel das unbekannte
auf der rechten Seite der Gleichung durch die Näherung des expliziten
Euler-Verfahrens nähert, das sogenannte Heun-Verfahren.
All diesen Verfahren und allen weiteren Verallgemeinerungen ist die Grundidee
der Einschrittverfahren gemeinsam: der Schritt

mit einer Steigung  ,
die von ,
und
,
die von ,
und  sowie (bei impliziten Verfahren) von
abhängen kann.
sowie (bei impliziten Verfahren) von
abhängen kann.
Definition
Mit den Überlegungen aus dem Einführungsabschnitt dieses Artikels kann der
Begriff des Einschrittverfahrens wie folgt definiert werden: Gesucht sei die
Lösung
des Anfangswertproblems
 ,
,
 .
.
Dabei werde vorausgesetzt, dass die Lösung

auf einem gegebenen Intervall ![{\displaystyle I=[t_{0},T]}](/svg/e2831dbc758b56a055d906e2728089c3041398e4.svg) existiert und eindeutig bestimmt ist. Sind
existiert und eindeutig bestimmt ist. Sind

Zwischenstellen im Intervall  und
die zugehörigen Schrittweiten, dann heißt das durch
und
die zugehörigen Schrittweiten, dann heißt das durch
 ,
,

gegebene Verfahren Einschrittverfahren mit Verfahrensfunktion
.
Wenn
nicht von
abhängt, dann nennt man es explizites Einschrittverfahren. Anderenfalls
muss in jedem Schritt  eine Gleichung für
gelöst werden, und das Verfahren wird implizit genannt.
eine Gleichung für
gelöst werden, und das Verfahren wird implizit genannt.
Konsistenz und Konvergenz
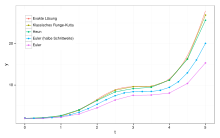
Konvergenzordnung
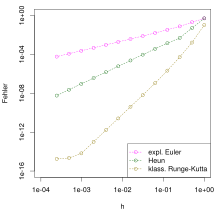
 für drei Einschrittverfahren. In doppelt-logarithmischer
Auftragung erscheint der Zusammenhang jeweils ungefähr linear, die
Steigungen entsprechen dabei den Konvergenzordnungen 1, 2 und
4.
für drei Einschrittverfahren. In doppelt-logarithmischer
Auftragung erscheint der Zusammenhang jeweils ungefähr linear, die
Steigungen entsprechen dabei den Konvergenzordnungen 1, 2 und
4.Für ein praxistaugliches Einschrittverfahren sollen die berechneten
gute Näherungen für die Werte  der exakten Lösung
an der Stelle
sein. Da im Allgemeinen die Größen -dimensionale
Vektoren sind, misst man die Güte dieser Näherung mit einer Vektornorm als
der exakten Lösung
an der Stelle
sein. Da im Allgemeinen die Größen -dimensionale
Vektoren sind, misst man die Güte dieser Näherung mit einer Vektornorm als  ,
dem Fehler an der Stelle .
Es ist wünschenswert, dass diese Fehler für alle
schnell gegen null konvergieren, falls man die Schrittweiten gegen null
konvergieren lässt. Um auch den Fall nicht konstanter Schrittweiten zu erfassen,
definiert man dazu genauer
als das Maximum der verwendeten Schrittweiten und betrachtet das Verhalten des
maximalen Fehlers an allen Stellen
im Vergleich zu Potenzen von .
Man sagt, das Einschrittverfahren zur Lösung des gegebenen Anfangswertproblems
habe die Konvergenzordnung
,
dem Fehler an der Stelle .
Es ist wünschenswert, dass diese Fehler für alle
schnell gegen null konvergieren, falls man die Schrittweiten gegen null
konvergieren lässt. Um auch den Fall nicht konstanter Schrittweiten zu erfassen,
definiert man dazu genauer
als das Maximum der verwendeten Schrittweiten und betrachtet das Verhalten des
maximalen Fehlers an allen Stellen
im Vergleich zu Potenzen von .
Man sagt, das Einschrittverfahren zur Lösung des gegebenen Anfangswertproblems
habe die Konvergenzordnung  ,
wenn die Abschätzung
,
wenn die Abschätzung

für alle hinreichend kleinen
mit einer von
unabhängigen Konstante  gilt.
gilt.
Die Konvergenzordnung ist die wichtigste Kenngröße für den Vergleich
verschiedener Einschrittverfahren.
Ein Verfahren mit höherer Konvergenzordnung  liefert im Allgemeinen bei vorgegebener Schrittweite einen kleineren
Gesamtfehler bzw. umgekehrt sind weniger Schritte nötig, um eine vorgegebene
Genauigkeit zu erreichen. Bei einem Verfahren mit
liefert im Allgemeinen bei vorgegebener Schrittweite einen kleineren
Gesamtfehler bzw. umgekehrt sind weniger Schritte nötig, um eine vorgegebene
Genauigkeit zu erreichen. Bei einem Verfahren mit  ist zu erwarten, dass sich bei einer Halbierung der Schrittweite auch der Fehler
nur ungefähr halbiert. Bei einem Verfahren der Konvergenzordnung
ist zu erwarten, dass sich bei einer Halbierung der Schrittweite auch der Fehler
nur ungefähr halbiert. Bei einem Verfahren der Konvergenzordnung  kann man hingegen davon ausgehen, dass sich dabei der Fehler ungefähr um den
Faktor
kann man hingegen davon ausgehen, dass sich dabei der Fehler ungefähr um den
Faktor  verringert.
verringert.
Globaler und lokaler Fehler
Die in der Definition der Konvergenzordnung betrachteten Fehler
setzen sich auf eine zunächst kompliziert erscheinende Weise aus zwei
Einzelkomponenten zusammen: Natürlich hängen sie zum einen von dem Fehler ab,
den das Verfahren in einem einzelnen Schritt macht, indem es die unbekannte
Steigung der gesuchten Funktion durch die Verfahrensfunktion annähert. Zum
anderen ist aber zusätzlich zu berücksichtigen, dass bereits der Startpunkt
 eines Schrittes im Allgemeinen nicht mit dem exakten Startpunkt
eines Schrittes im Allgemeinen nicht mit dem exakten Startpunkt  übereinstimmt; der Fehler nach diesem Schritt hängt also auch von allen
Fehlern ab, die bereits in den vorangegangenen Schritten gemacht wurden.
Aufgrund der einheitlichen Definition der Einschrittverfahren, die sich nur in
der Wahl der Verfahrensfunktion
unterscheiden, lässt sich aber beweisen, dass man (unter gewissen technischen
Voraussetzungen an )
direkt von der Fehlerordnung in einem einzelnen Schritt, der sogenannten
Konsistenzordnung, auf die Konvergenzordnung schließen kann.
übereinstimmt; der Fehler nach diesem Schritt hängt also auch von allen
Fehlern ab, die bereits in den vorangegangenen Schritten gemacht wurden.
Aufgrund der einheitlichen Definition der Einschrittverfahren, die sich nur in
der Wahl der Verfahrensfunktion
unterscheiden, lässt sich aber beweisen, dass man (unter gewissen technischen
Voraussetzungen an )
direkt von der Fehlerordnung in einem einzelnen Schritt, der sogenannten
Konsistenzordnung, auf die Konvergenzordnung schließen kann.
Der Begriff der Konsistenz ist ein allgemeines und zentrales Konzept der modernen numerischen Mathematik. Während man bei der Konvergenz eines Verfahrens untersucht, wie gut die numerischen Näherungen zur exakten Lösung passen, stellt man sich bei der Konsistenz vereinfacht gesprochen die „umgekehrte“ Frage: Wie gut erfüllt die exakte Lösung die Verfahrensvorschrift? In dieser allgemeinen Theorie gilt, dass ein Verfahren genau dann konvergent ist, wenn es konsistent und stabil ist. Um die Notation zu vereinfachen, soll in der folgenden Überlegung angenommen werden, dass ein explizites Einschrittverfahren

mit konstanter Schrittweite
vorliegt. Mit der wahren Lösung  definiert man den lokalen Abschneidefehler (auch lokaler
Verfahrensfehler genannt)
definiert man den lokalen Abschneidefehler (auch lokaler
Verfahrensfehler genannt)  als
als
 .
.
Man nimmt also an, dass die exakte Lösung bekannt ist, startet einen
Verfahrensschritt an der Stelle  und bildet die Differenz zu exakten Lösung an der Stelle
und bildet die Differenz zu exakten Lösung an der Stelle  .
Damit definiert man: Ein Einschrittverfahren hat die Konsistenzordnung
,
wenn die Abschätzung
.
Damit definiert man: Ein Einschrittverfahren hat die Konsistenzordnung
,
wenn die Abschätzung

für alle hinreichend kleinen
mit einer von
unabhängigen Konstante
gilt.
Der auffällige Unterschied zwischen den Definitionen der Konsistenzordnung
und der Konvergenzordnung ist die Potenz  anstelle von
anstelle von  .
Das lässt sich anschaulich so deuten, dass beim Übergang vom lokalen zum
globalen Fehler eine Potenz der Schrittweite „verloren geht“. Es gilt nämlich
der folgende, für die Theorie der Einschrittverfahren zentrale Satz:
.
Das lässt sich anschaulich so deuten, dass beim Übergang vom lokalen zum
globalen Fehler eine Potenz der Schrittweite „verloren geht“. Es gilt nämlich
der folgende, für die Theorie der Einschrittverfahren zentrale Satz:
- Ist die Verfahrensfunktion
Lipschitz-stetig
und hat das zugehörige Einschrittverfahren die Konsistenzordnung ,
dann hat es auch die Konvergenzordnung .
Die Lipschitz-Stetigkeit der Verfahrensfunktion als Zusatzvoraussetzung für
die Stabilität ist im Allgemeinen immer dann erfüllt, wenn die Funktion
aus der Differentialgleichung selbst Lipschitz-stetig ist. Diese Forderung muss
für die meisten Anwendungen sowieso vorausgesetzt werden, um die eindeutige
Lösbarkeit des Anfangswertproblems zu garantieren. Nach dem Satz genügt es also,
die Konsistenzordnung eines Einschrittverfahrens zu bestimmen. Das lässt sich
prinzipiell durch Taylor-Entwicklung
von  nach Potenzen von
erreichen. In der Praxis werden die entstehenden Formeln für höhere Ordnungen
sehr kompliziert und unübersichtlich, sodass zusätzliche Konzepte und Notationen
benötigt werden.
nach Potenzen von
erreichen. In der Praxis werden die entstehenden Formeln für höhere Ordnungen
sehr kompliziert und unübersichtlich, sodass zusätzliche Konzepte und Notationen
benötigt werden.
Steifheit und A-Stabilität
Die Konvergenzordnung eines Verfahrens ist eine asymptotische Aussage, die das Verhalten der Näherungen beschreibt, wenn die Schrittweite gegen null konvergiert. Sie sagt jedoch nichts darüber aus, ob das Verfahren für eine gegebene feste Schrittweite auch tatsächlich eine brauchbare Näherung berechnet. Dass dies bei bestimmten Typen von Anfangswertproblemen tatsächlich ein großes Problem darstellen kann, beschrieben zuerst Charles Francis Curtiss und Joseph O. Hirschfelder 1952. Sie hatten beobachtet, dass bei manchen Differentialgleichungssystemen der chemischen Reaktionskinetik die Lösungen nicht mit expliziten numerischen Verfahren berechnet werden können, und nannten solche Anfangswertprobleme „steif“. Es existieren zahlreiche mathematische Kriterien, um für ein gegebenes Problem festzustellen, wie steif es ist. Anschaulich handelt es sich bei steifen Anfangswertproblemen meist um Differentialgleichungssysteme, bei denen einige Komponenten sehr schnell konstant werden, während andere Komponenten sich nur langsam ändern. Ein solches Verhalten tritt typischerweise bei der Modellierung chemischer Reaktionen auf. Die für die praktische Anwendung nützlichste Definition von Steifheit ist dabei jedoch: Ein Anfangswertproblem ist steif, wenn man bei seiner Lösung mit expliziten Einschrittverfahren die Schrittweite „zu klein“ wählen müsste, um eine brauchbare Lösung zu erhalten. Solche Probleme können also nur mit impliziten Verfahren gelöst werden.
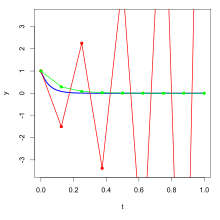
Dieser Effekt lässt sich genauer darstellen, wenn man untersucht, wie die einzelnen Verfahren mit exponentiellem Zerfall zurechtkommen. Dazu betrachtet man nach dem schwedischen Mathematiker Germund Dahlquist die Testgleichung

mit der für  exponentiell abfallenden Lösung
exponentiell abfallenden Lösung  .
Die nebenstehende Grafik zeigt – exemplarisch für das explizite und das
implizite Euler-Verfahren – das typische Verhalten dieser beiden
Verfahrensgruppen bei diesem so einfach erscheinenden Anfangswertproblem:
Verwendet man bei einem expliziten Verfahren eine zu große Schrittweite, dann
ergeben sich stark oszillierende Werte, die sich im Laufe der Rechnung
aufschaukeln und sich immer weiter von der exakten Lösung entfernen. Implizite
Verfahren berechnen hingegen typischerweise die Lösung für beliebige
Schrittweiten qualitativ richtig, nämlich als exponentiell fallende Folge von
Näherungswerten.
.
Die nebenstehende Grafik zeigt – exemplarisch für das explizite und das
implizite Euler-Verfahren – das typische Verhalten dieser beiden
Verfahrensgruppen bei diesem so einfach erscheinenden Anfangswertproblem:
Verwendet man bei einem expliziten Verfahren eine zu große Schrittweite, dann
ergeben sich stark oszillierende Werte, die sich im Laufe der Rechnung
aufschaukeln und sich immer weiter von der exakten Lösung entfernen. Implizite
Verfahren berechnen hingegen typischerweise die Lösung für beliebige
Schrittweiten qualitativ richtig, nämlich als exponentiell fallende Folge von
Näherungswerten.
Etwas allgemeiner betrachtet man die obige Testgleichung auch für komplexe Werte von .
In diesem Fall sind die Lösungen Schwingungen,
deren Amplitude genau dann
beschränkt bleibt, wenn  gilt, also der Realteil
von
kleiner oder gleich 0 ist. Damit lässt sich eine wünschenswerte Eigenschaft von
Einschrittverfahren formulieren, die für steife Anfangswertprobleme eingesetzt
werden sollen: die sogenannte A-Stabilität. Ein Verfahren heißt A-stabil, wenn
es für beliebige Schrittweiten
gilt, also der Realteil
von
kleiner oder gleich 0 ist. Damit lässt sich eine wünschenswerte Eigenschaft von
Einschrittverfahren formulieren, die für steife Anfangswertprobleme eingesetzt
werden sollen: die sogenannte A-Stabilität. Ein Verfahren heißt A-stabil, wenn
es für beliebige Schrittweiten  angewendet auf die Testgleichung für alle
mit
eine Folge von Näherungen
berechnet, die (wie die wahre Lösung) beschränkt bleibt. Das implizite
Euler-Verfahren und das implizite Trapez-Verfahren sind die einfachsten
Beispiele A-stabiler Einschrittverfahren. Andererseits lässt sich zeigen, dass
ein explizites Verfahren niemals A-stabil sein kann.
angewendet auf die Testgleichung für alle
mit
eine Folge von Näherungen
berechnet, die (wie die wahre Lösung) beschränkt bleibt. Das implizite
Euler-Verfahren und das implizite Trapez-Verfahren sind die einfachsten
Beispiele A-stabiler Einschrittverfahren. Andererseits lässt sich zeigen, dass
ein explizites Verfahren niemals A-stabil sein kann.
Spezielle Verfahren und Verfahrensklassen
Einfache Verfahren der Ordnung 1 und 2
Wie der französische Mathematiker Augustin-Louis Cauchy um 1820 bewies, besitzt das Euler-Verfahren die
Konvergenzordnung 1.
Wenn man die Steigungen
des expliziten
Euler-Verfahrens und
des impliziten
Euler-Verfahrens, wie sie an den beiden Endpunkten eines Schritts vorliegen,
mittelt, kann man hoffen, eine bessere Näherung über das ganze Intervall zu
erhalten. Tatsächlich lässt sich beweisen, dass das so erhaltene implizite
Trapez-Verfahren

die Konvergenzordnung 2 hat. Dieses Verfahren weist sehr gute
Stabilitätseigenschaften auf, ist allerdings implizit, sodass in jedem Schritt
eine Gleichung für
gelöst werden muss. Nähert man diese Größe auf der rechten Seite der Gleichung
durch das explizite Euler-Verfahren an, so entsteht das explizite Verfahren von
Heun
 ,
,
das ebenfalls die Konvergenzordnung 2 besitzt. Ein weiteres einfaches
explizites Verfahren der Ordnung 2, das verbesserte
Euler-Verfahren, erhält man durch folgende Überlegung: Eine „mittlere“
Steigung im Verfahrensschritt wäre die Steigung der Lösung
in der Mitte des Schritts, also an der Stelle  .
Da die Lösung aber unbekannt ist, nähert man sie durch einen expliziten
Euler-Schritt mit halber Schrittweite an. Es ergibt sich die
Verfahrensvorschrift
.
Da die Lösung aber unbekannt ist, nähert man sie durch einen expliziten
Euler-Schritt mit halber Schrittweite an. Es ergibt sich die
Verfahrensvorschrift
 .
.
Diese Einschrittverfahren der Ordnung 2 wurden als Verbesserungen des Euler-Verfahrens alle 1895 von dem deutschen Mathematiker Carl Runge veröffentlicht.
Runge-Kutta-Verfahren
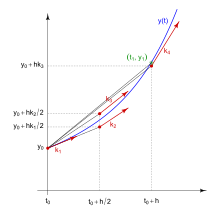
Die erwähnten Ideen für einfache Einschrittverfahren führen bei weiterer
Verallgemeinerung zur wichtigen Klasse der Runge-Kutta-Verfahren. Zum Beispiel
lässt sich das Verfahren von Heun übersichtlicher so präsentieren: Zuerst wird
eine Hilfssteigung  berechnet, nämlich die Steigung des expliziten Euler-Verfahrens. Damit wird eine
weitere Hilfssteigung bestimmt, hier
berechnet, nämlich die Steigung des expliziten Euler-Verfahrens. Damit wird eine
weitere Hilfssteigung bestimmt, hier  .
Die tatsächlich verwendete Verfahrenssteigung
ergibt sich anschließend als ein gewichtetes Mittel der Hilfssteigungen, im
Verfahren von Heun also
.
Die tatsächlich verwendete Verfahrenssteigung
ergibt sich anschließend als ein gewichtetes Mittel der Hilfssteigungen, im
Verfahren von Heun also  .
Dieses Vorgehen lässt sich auf mehr als zwei Hilfssteigungen verallgemeinern.
Ein
.
Dieses Vorgehen lässt sich auf mehr als zwei Hilfssteigungen verallgemeinern.
Ein  -stufiges
Runge-Kutta-Verfahren berechnet zunächst Hilfssteigungen
-stufiges
Runge-Kutta-Verfahren berechnet zunächst Hilfssteigungen  durch Auswertung von
an geeigneten Stellen und anschließend
als gewichtetes Mittel. Bei einem expliziten Runge-Kutta-Verfahren werden die
Hilfssteigungen
durch Auswertung von
an geeigneten Stellen und anschließend
als gewichtetes Mittel. Bei einem expliziten Runge-Kutta-Verfahren werden die
Hilfssteigungen  der Reihe nach direkt berechnet, bei einem impliziten ergeben sie sich als
Lösungen eines Gleichungssystems. Als typisches Beispiel sei das explizite klassische
Runge-Kutta-Verfahren der Ordnung 4 angeführt, das mitunter einfach als
das Runge-Kutta-Verfahren bezeichnet wird: Dabei werden zunächst die vier
Hilfssteigungen
der Reihe nach direkt berechnet, bei einem impliziten ergeben sie sich als
Lösungen eines Gleichungssystems. Als typisches Beispiel sei das explizite klassische
Runge-Kutta-Verfahren der Ordnung 4 angeführt, das mitunter einfach als
das Runge-Kutta-Verfahren bezeichnet wird: Dabei werden zunächst die vier
Hilfssteigungen

berechnet und dann als Verfahrenssteigung das gewichtete Mittel

verwendet. Dieses bekannte Verfahren veröffentlichte der deutsche Mathematiker Wilhelm Kutta im Jahr 1901, nachdem ein Jahr zuvor Karl Heun ein dreistufiges Einschrittverfahren der Ordnung 3 gefunden hatte.
Die Konstruktion von expliziten Verfahren noch höherer Ordnung mit möglichst
kleiner Stufenzahl ist ein mathematisch recht anspruchsvolles Problem. Wie John C. Butcher 1965
zeigen konnte, gibt es zum Beispiel für die Ordnung 5 nur minimal
sechsstufige Verfahren; ein explizites Runge-Kutta-Verfahren der Ordnung 8
benötigt mindestens 11 Stufen. 1978 fand der österreichische Mathematiker
Ernst Hairer ein Verfahren der Ordnung 10 mit 17 Stufen. Die
Koeffizienten für ein solches Verfahren müssen 1205 Bestimmungsgleichungen
erfüllen.
Bei impliziten Runge-Kutta-Verfahren ist die Situation einfacher und
übersichtlicher: Für jede Stufenzahl
existiert ein Verfahren der Ordnung  ;
das ist zugleich die maximal erreichbare Ordnung.
;
das ist zugleich die maximal erreichbare Ordnung.
Extrapolationsverfahren
Die Idee der Extrapolation
ist nicht auf die Lösung von Anfangswertproblemen mit Einschrittverfahren
beschränkt, sondern lässt sich sinngemäß auf alle numerischen Verfahren
anwenden, die das zu lösende Problem mit einer Schrittweite
diskretisieren. Ein bekanntes Beispiel eines Extrapolationsverfahrens ist etwa
die Romberg-Integration
zur numerischen Berechnung von Integralen. Sei daher ganz allgemein
ein Wert, der numerisch bestimmt werden soll, im Fall dieses Artikels etwa der
Wert der Lösungsfunktion eines Anfangswertproblems an einer gegebenen Stelle.
Ein numerisches Verfahren, beispielsweise ein Einschrittverfahren, berechnet
dafür einen Näherungswert  ,
der von der Wahl der Schrittweite
abhängt. Dabei sei angenommen, dass das Verfahren konvergent ist, also, dass
gegen
konvergiert, wenn
gegen null konvergiert. Diese Konvergenz ist jedoch nur eine rein theoretische
Aussage, da bei der realen Anwendung des Verfahrens zwar Näherungswerte
,
der von der Wahl der Schrittweite
abhängt. Dabei sei angenommen, dass das Verfahren konvergent ist, also, dass
gegen
konvergiert, wenn
gegen null konvergiert. Diese Konvergenz ist jedoch nur eine rein theoretische
Aussage, da bei der realen Anwendung des Verfahrens zwar Näherungswerte  für endlich viele verschiedene Schrittweiten
für endlich viele verschiedene Schrittweiten  berechnet werden können, man aber selbstverständlich nicht die Schrittweite
„gegen null konvergieren“ lassen kann. Die berechneten Näherungen für
verschiedene Schrittweiten lassen sich jedoch als Information über die
(unbekannte) Funktion
berechnet werden können, man aber selbstverständlich nicht die Schrittweite
„gegen null konvergieren“ lassen kann. Die berechneten Näherungen für
verschiedene Schrittweiten lassen sich jedoch als Information über die
(unbekannte) Funktion  auffassen: Bei den Extrapolationsverfahren wird dabei
durch ein Interpolationspolynom
angenähert, also durch ein Polynom
auffassen: Bei den Extrapolationsverfahren wird dabei
durch ein Interpolationspolynom
angenähert, also durch ein Polynom  mit
mit

für  .
Der Wert
.
Der Wert  des Polynoms an der Stelle
des Polynoms an der Stelle  wird dann als berechenbare Näherung für den nicht berechenbaren Grenzwert von
für
gegen null verwendet.
Einen frühen erfolgreichen Extrapolationsalgorithmus für Anfangswertprobleme
veröffentlichten Roland Bulirsch und Josef Stoer im Jahr 1966.
wird dann als berechenbare Näherung für den nicht berechenbaren Grenzwert von
für
gegen null verwendet.
Einen frühen erfolgreichen Extrapolationsalgorithmus für Anfangswertprobleme
veröffentlichten Roland Bulirsch und Josef Stoer im Jahr 1966.
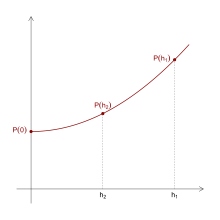 bei einem Verfahren der Ordnung
bei einem Verfahren der Ordnung 
Ein konkretes Beispiel im Falle eines Einschrittverfahrens der Ordnung
kann das allgemeine Vorgehen der Extrapolation verständlich machen. Bei einem
solchen Verfahren lässt sich die berechnete Näherung für kleine Schrittweiten
gut durch ein Polynom der Form

mit zunächst unbekannten Parametern  und
und  annähern. Berechnet man nun mit dem Verfahren für eine Schrittweite
annähern. Berechnet man nun mit dem Verfahren für eine Schrittweite  und für die halbe Schrittweite
und für die halbe Schrittweite  zwei Näherungen
zwei Näherungen  und
und  ,
erhält man aus den Interpolationsbedingungen
,
erhält man aus den Interpolationsbedingungen  und
und  zwei lineare Gleichungen für die Unbekannten
und .
Der auf
extrapolierte Wert
zwei lineare Gleichungen für die Unbekannten
und .
Der auf
extrapolierte Wert

stellt dann im Allgemeinen eine deutlich bessere Näherung dar als die beiden
zunächst berechneten Werte. Es lässt sich zeigen, dass die Ordnung des so
erhaltenen Einschrittverfahrens mindestens  ist, also um mindestens 1 größer als beim ursprünglichen Verfahren ist.
ist, also um mindestens 1 größer als beim ursprünglichen Verfahren ist.
Verfahren mit Schrittweitensteuerung
Ein Vorteil der Einschrittverfahren ist, dass in jedem Schritt
unabhängig von den anderen Schritten eine beliebige Schrittweite
verwendet werden kann. In der Praxis stellt sich dabei offensichtlich die Frage,
wie
gewählt werden soll. In realen Anwendungen wird stets eine Fehlertoleranz
gegeben sein, mit der die Lösung eines Anfangswertproblems berechnet werden
soll; zum Beispiel wäre es sinnlos, eine numerische Näherung zu bestimmen, die
wesentlich „genauer“ ist als die mit Messabweichungen
behafteten Daten für Startwerte und Parameter des gegebenen Problems. Das Ziel
wird also sein, die Schrittweiten so zu wählen, dass einerseits die vorgegebenen
Fehlertoleranzen eingehalten werden, andererseits aber auch möglichst wenige
Schritte zu verwenden, um den Rechenaufwand klein zu halten. Dies wird sich im
Allgemeinen nur dann erreichen lassen, wenn die Schrittweiten an den Verlauf der
Lösung angepasst werden: kleine Schritte, wo sich die Lösung stark ändert, große
Schritte, wo sie nahezu konstant verläuft.
Bei gut
konditionierten Anfangswertproblemen lässt sich zeigen, dass der globale
Verfahrensfehler ungefähr gleich der Summe der lokalen Abschneidefehler  in den einzelnen Schritten ist. Daher sollte als Schrittweite ein möglichst
großes
gewählt werden, für das
in den einzelnen Schritten ist. Daher sollte als Schrittweite ein möglichst
großes
gewählt werden, für das  unter einer gewählten Toleranzschwelle liegt. Das Problem dabei ist, dass
nicht direkt berechnet werden kann, da es ja von der unbekannten exakten Lösung
des Anfangswertproblems an der Stelle
abhängt. Die Grundidee der Schrittweitensteuerung ist es daher,
mit einem Verfahren anzunähern, das genauer ist als das zugrundeliegende
Basisverfahren.
unter einer gewählten Toleranzschwelle liegt. Das Problem dabei ist, dass
nicht direkt berechnet werden kann, da es ja von der unbekannten exakten Lösung
des Anfangswertproblems an der Stelle
abhängt. Die Grundidee der Schrittweitensteuerung ist es daher,
mit einem Verfahren anzunähern, das genauer ist als das zugrundeliegende
Basisverfahren.
Zwei grundlegende Ideen zur Schrittweitensteuerung sind die
Schrittweitenhalbierung und die eingebetteten Verfahren. Bei der
Schrittweitenhalbierung wird zusätzlich zum eigentlichen Verfahrensschritt als
Vergleichswert das Ergebnis für zwei Schritte mit der halben Schrittweite
berechnet. Aus beiden Werten wird dann durch Extrapolation eine genauere
Näherung für
bestimmt und damit der lokale Fehler
geschätzt. Ist dieser zu groß, wird dieser Schritt verworfen und mit einer
kleineren Schrittweite wiederholt. Ist er deutlich kleiner als die vorgegebene
Toleranz, kann im nächsten Schritt die Schrittweite vergrößert werden.
Der zusätzliche Rechenaufwand für dieses Schrittweitenhalbierungsverfahren ist
relativ groß; deshalb verwenden moderne Implementierungen meist sogenannte
eingebettete Verfahren zur Schrittweitensteuerung. Die Grundidee ist dabei, in
jedem Schritt zwei Näherungen für
mit zwei Einschrittverfahren zu berechnen, die verschiedene Konvergenzordnungen
haben, und damit den lokalen Fehler zu schätzen. Um den Rechenaufwand zu
optimieren, sollten die beiden Verfahren möglichst viele Rechenschritte
gemeinsam haben: Sie sollten „ineinander eingebettet“ sein. Eingebettete
Runge-Kutta-Verfahren verwenden beispielsweise die gleichen Hilfssteigungen und
unterscheiden sich nur darin, wie sie diese mitteln. Bekannte eingebettete
Verfahren sind unter anderem die Runge-Kutta-Fehlberg-Verfahren
(Erwin Fehlberg, 1969)
und die Dormand-Prince-Verfahren
(J. R. Dormand und P. J. Prince, 1980).
Praxisbeispiel: Lösen von Anfangswertproblemen mit numerischer Software
Für die in diesem Artikel überblicksartig dargestellten mathematischen Konzepte wurden zahlreiche Software-Implementierungen entwickelt, die dem Anwender die Möglichkeit geben, praktische Probleme auf einfache Weise numerisch zu lösen. Als konkretes Beispiel dazu soll nun eine Lösung der Lotka-Volterra-Gleichungen mit der verbreiteten numerischen Software Matlab berechnet werden. Die Lotka-Volterra-Gleichungen sind ein einfaches Modell aus der Biologie, das die Wechselwirkungen von Räuber- und Beutepopulationen beschreibt. Gegeben sei dazu das Differentialgleichungssystem

mit den Parametern  und der Anfangsbedingung
und der Anfangsbedingung  ,
,
 .
Hierbei entsprechen
.
Hierbei entsprechen  und
und  der zeitlichen Entwicklung der Beute- bzw. der Räuberpopulation. Die Lösung soll
auf dem Zeitintervall
der zeitlichen Entwicklung der Beute- bzw. der Räuberpopulation. Die Lösung soll
auf dem Zeitintervall ![{\displaystyle [0,20]}](/svg/83fa6e3e4170f0b2c00d850bc56487657407968e.svg) berechnet werden.
berechnet werden.
Für die Berechnung mithilfe von Matlab wird zunächst für die gegebenen
Parameterwerte die Funktion
auf der rechten Seite der Differentialgleichung  definiert:
definiert:
a = 1; b = 2; c = 1; d = 1;
f = @(t,y) [a*y(1) - b*y(1)*y(2); c*y(1)*y(2) - d*y(2)];
Außerdem werden das Zeitintervall und die Anfangswerte benötigt:
t_int = [0, 20]; y0 = [3; 1];
Anschließend kann die Lösung berechnet werden:
[t, y] = ode45(f, t_int, y0);
Die Matlab-Funktion ode45 implementiert ein Einschrittverfahren,
das zwei eingebettete explizite Runge-Kutta-Verfahren mit den
Konvergenzordnungen 4 und 5 zur Schrittweitensteuerung verwendet.
Die Lösung kann nun gezeichnet werden,
als blaue Kurve und
als rote; die berechneten Punkte werden durch kleine Kreise markiert:
figure(1)
plot(t, y(:,1), 'b-o', t, y(:,2), 'r-o')
Das Ergebnis ist unten im linken Bild dargestellt. Das rechte Bild zeigt die vom Verfahren verwendeten Schrittweiten und wurde erzeugt mit
figure(2)
plot(t(1:end-1), diff(t))
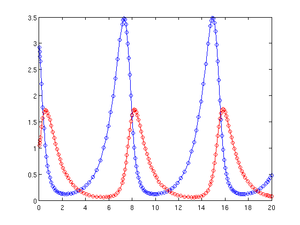
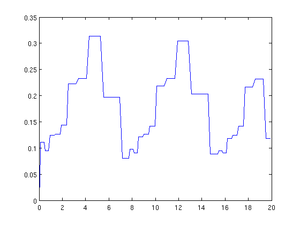
Dieses Beispiel kann ohne Änderungen auch mit der freien numerischen Software GNU Octave ausgeführt werden. Mit dem dort implementierten Verfahren ergibt sich allerdings eine etwas andere Schrittweitenfolge.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 24.05. 2026