Runge-Kutta-Verfahren
Die nach Carl Runge und Martin Wilhelm Kutta benannten  -stufigen
Runge-Kutta-Verfahren sind Einschrittverfahren
zur näherungsweisen Lösung von Anfangswertproblemen
in der numerischen
Mathematik. Wenn von dem
Runge-Kutta-Verfahren gesprochen wird, ist in der Regel das klassische
Runge-Kutta-Verfahren gemeint; dieses bildet jedoch nur einen Spezialfall
dieser Familie von Verfahren.
-stufigen
Runge-Kutta-Verfahren sind Einschrittverfahren
zur näherungsweisen Lösung von Anfangswertproblemen
in der numerischen
Mathematik. Wenn von dem
Runge-Kutta-Verfahren gesprochen wird, ist in der Regel das klassische
Runge-Kutta-Verfahren gemeint; dieses bildet jedoch nur einen Spezialfall
dieser Familie von Verfahren.
Allgemeine Formulierung
Gegeben sei ein Anfangswertproblem:

mit exakter Lösung  .
Die exakte Lösung kann im Allgemeinen nicht oder nicht effizient angegeben
werden, weshalb man sich mit einer Näherung
.
Die exakte Lösung kann im Allgemeinen nicht oder nicht effizient angegeben
werden, weshalb man sich mit einer Näherung  an diskreten Stellen
an diskreten Stellen  begnügt. Es gibt verschiedene Methoden zur Berechnung dieser Näherung, zum
Beispiel Einschrittverfahren, wie diese Runge-Kutta-Verfahren, oder Mehrschrittverfahren.
begnügt. Es gibt verschiedene Methoden zur Berechnung dieser Näherung, zum
Beispiel Einschrittverfahren, wie diese Runge-Kutta-Verfahren, oder Mehrschrittverfahren.
Die -stufigen
Runge-Kutta-Verfahren sind Einschrittverfahren, die durch Ausdrücke der
folgenden Art gegeben sind:

Dabei bezeichnet  die Schrittweite zwischen den aufeinanderfolgenden Stützstellen
und
die Schrittweite zwischen den aufeinanderfolgenden Stützstellen
und  .
Die
Koeffizienten
.
Die
Koeffizienten  definieren das jeweilige Verfahren und können als Gewichte der Quadraturformel für das
Integral
definieren das jeweilige Verfahren und können als Gewichte der Quadraturformel für das
Integral  interpretiert werden. Die Größen
interpretiert werden. Die Größen  bezeichnet man als Zwischenschritte, sie entsprechen Auswertungen der rechten
Seite
bezeichnet man als Zwischenschritte, sie entsprechen Auswertungen der rechten
Seite  an bestimmten Knoten:
an bestimmten Knoten:

Die  und
und  sind weitere für das Verfahren charakteristische Koeffizienten und können als
Knoten und Gewichte der Quadraturformeln zur Berechnung der
verstanden werden.
sind weitere für das Verfahren charakteristische Koeffizienten und können als
Knoten und Gewichte der Quadraturformeln zur Berechnung der
verstanden werden.
Ein allgemeines Runge-Kutta-Verfahren ist implizit, es müssen also zur
Bestimmung der
lineare beziehungsweise nichtlineare Gleichungssysteme gelöst werden. Gilt aber
 für alle
für alle  ,
ist das Verfahren explizit.
,
ist das Verfahren explizit.
Die Steuerung
der Schrittweite
ist von besonderem Interesse. Man kann sich leicht vorstellen, dass die Funktion
in Bereichen, in denen nur geringe Änderungen zwischen  und
vorliegen, mit weniger Rechenschritten auskommt als in solchen, in denen
schnelle Änderungen vorliegen.
und
vorliegen, mit weniger Rechenschritten auskommt als in solchen, in denen
schnelle Änderungen vorliegen.
Beispiel
Ein Beispiel ist das dreistufige Runge-Kutta-Verfahren:  mit den Zwischenstufen
mit den Zwischenstufen



Butcher-Tableau
Man kann die charakteristischen Koeffizienten ,
übersichtlich im Runge-Kutta-Tableau (auch Butcher-Schema,
-Tableau oder engl. Butcher array genannt) anordnen. Hierbei ist die
Matrix A bei einem expliziten Verfahren eine strikte untere Dreiecksmatrix (Nilpotente
Dreiecksmatrix).


Konsistenzordnung und Konvergenzordnung
Eine wichtige Eigenschaft zum Vergleich von Verfahren ist die Konsistenzordnung,
die auf dem Begriff des lokalen
Diskretisierungsfehlers  beruht. Dabei ist
die numerische Lösung nach einem Schritt und
beruht. Dabei ist
die numerische Lösung nach einem Schritt und  die exakte Lösung. Ein Einschrittverfahren heißt konsistent von der Ordnung
die exakte Lösung. Ein Einschrittverfahren heißt konsistent von der Ordnung
 (hat Konsistenzordnung ),
falls für den lokalen Diskretisierungsfehler gilt:
(hat Konsistenzordnung ),
falls für den lokalen Diskretisierungsfehler gilt:
 (Zur Notation siehe Landau-Symbole).
(Zur Notation siehe Landau-Symbole).
Die Konsistenzordnung kann durch Taylorentwicklung von
 oder der exakten und numerischen Lösung bestimmt werden. Allgemein gilt:
oder der exakten und numerischen Lösung bestimmt werden. Allgemein gilt:
- Konsistenzordnung
und Stabilität
 Konvergenzordnung
Konvergenzordnung
Bei Einschrittverfahren wie den Runge-Kutta-Verfahren gilt sogar, sofern
und die Verfahrensvorschrift Lipschitz-stetig sind:
- Konsistenzordnung
Konvergenzordnung
Aus der Konsistenzbedingung (z. B. soll das Verfahren Ordnung 4 haben) ergeben sich Konsistenzgleichungen (engl. conditions) für die Koeffizienten des Runge-Kutta-Verfahrens. Die Gleichungen und ihre Anzahl können mit Hilfe von Taylorentwicklung oder der Theorie der Butcher-Bäume ermittelt werden. Mit zunehmender Ordnung wächst die Zahl der zu lösenden nicht-linearen Konsistenzgleichungen schnell an. Das Aufstellen der Konsistenzgleichungen ist bereits nicht einfach, kann jedoch mit Hilfe der Butcher-Bäume von Computeralgebrasystemen erledigt werden. Das Lösen ist allerdings noch schwieriger und bedarf Erfahrung und Fingerspitzengefühl, um „gute“ Koeffizienten zu erhalten.
Ein explizites -stufiges
Runge-Kutta-Verfahren hat höchstens Konvergenzordnung ,
ein implizites dagegen bis zu  .
.
Um die Genauigkeit eines Ergebnisses zu verbessern, gibt es zwei Möglichkeiten:
- Man kann die Schrittweite verkleinern, das heißt, man erhöht die Anzahl der Diskretisierungspunkte.
- Man kann Verfahren höherer Konvergenzordnung wählen.
Welche Strategie die bessere ist, hängt von der konkreten Problemstellung ab,
die Erhöhung der Konvergenzordnung ist allerdings nur bis zu einer bestimmten
Grenze sinnvoll, da wegen der Butcher-Schranken
die Stufenzahl
schneller wächst als die Ordnung .
Für  existiert beispielsweise kein explizites -stufiges
RKV der Konvergenzordnung
existiert beispielsweise kein explizites -stufiges
RKV der Konvergenzordnung  .
.
Implizite Runge-Kutta-Verfahren
Explizite Verfahren haben den Vorteil, dass die Stufen durch sukzessives
Einsetzen berechenbar sind, beim impliziten Verfahren muss dagegen je nach Form
der rechten Seite  ein lineares oder nichtlineares Gleichungssystem mit
ein lineares oder nichtlineares Gleichungssystem mit  Unbekannten gelöst werden, was pro Zeitschritt einen wesentlich höheren Aufwand
darstellt. Der Grund, warum implizite Verfahren überhaupt in Betracht gezogen
werden, ist, dass explizite Runge-Kutta-Verfahren stets ein beschränktes Stabilitätsgebiet
haben, während implizite Runge-Kutta-Verfahren für praktisch beliebig hohe
Ordnungen A-stabil
sein können und damit Einschränkungen an den Zeitschritt nur aufgrund von
Genauigkeitsüberlegungen und nicht aufgrund von Stabilitätsbeschränkungen
notwendig sind. Dies ist insbesondere bei steifen
Anfangswertproblemen und differentiell-algebraischen
Gleichungen interessant.
Unbekannten gelöst werden, was pro Zeitschritt einen wesentlich höheren Aufwand
darstellt. Der Grund, warum implizite Verfahren überhaupt in Betracht gezogen
werden, ist, dass explizite Runge-Kutta-Verfahren stets ein beschränktes Stabilitätsgebiet
haben, während implizite Runge-Kutta-Verfahren für praktisch beliebig hohe
Ordnungen A-stabil
sein können und damit Einschränkungen an den Zeitschritt nur aufgrund von
Genauigkeitsüberlegungen und nicht aufgrund von Stabilitätsbeschränkungen
notwendig sind. Dies ist insbesondere bei steifen
Anfangswertproblemen und differentiell-algebraischen
Gleichungen interessant.
Die maximale Ordnung eines -stufigen
Runge-Kutta-Verfahrens ist .
Diese wird ausschließlich durch die Gauß-Legendre-Verfahren erzielt, bei denen
die Quadraturformeln zur Konstruktion des Runge-Kutta-Verfahren den Gauß-Legendre-Formeln
entsprechen. Ordnung  wird etwa mittels Radau-Formeln erzielt, die Runge-Kutta-Verfahren heißen dann
Radau-Verfahren, während Ordnung
wird etwa mittels Radau-Formeln erzielt, die Runge-Kutta-Verfahren heißen dann
Radau-Verfahren, während Ordnung  über Lobatto-Formeln erzielt wird, die Verfahren heißen dann Lobatto-Verfahren.
über Lobatto-Formeln erzielt wird, die Verfahren heißen dann Lobatto-Verfahren.
Um die Lösung eines Gleichungssystems mit
Unbekannten zu umgehen, werden häufig Diagonal Implizite Runge-Kutta-Verfahren
(kurz DIRK) genutzt. Dabei hat die Matrix  im Butcher-Array Dreieckform, alle Einträge rechts oberhalb der Diagonalen sind
also Null. Dies entkoppelt das große Gleichungssystem in eine Sequenz von
Gleichungssystemen. Ist darüber hinaus der Koeffizient auf der Diagonalen
konstant, spricht man von einem SDIRK-Verfahren (für engl: singly
diagonal). Sind die Koeffizienten in der letzten Zeile von
identisch mit denen des Vektors
im Butcher-Array Dreieckform, alle Einträge rechts oberhalb der Diagonalen sind
also Null. Dies entkoppelt das große Gleichungssystem in eine Sequenz von
Gleichungssystemen. Ist darüber hinaus der Koeffizient auf der Diagonalen
konstant, spricht man von einem SDIRK-Verfahren (für engl: singly
diagonal). Sind die Koeffizienten in der letzten Zeile von
identisch mit denen des Vektors  ,
so wird etwas Aufwand gespart, insbesondere sind die Verfahren dann aber auch L-stabil.
Diese Vereinfachung geschieht auf Kosten der maximalen Ordnung: -stufige
DIRK-Verfahren haben maximal Ordnung
,
so wird etwas Aufwand gespart, insbesondere sind die Verfahren dann aber auch L-stabil.
Diese Vereinfachung geschieht auf Kosten der maximalen Ordnung: -stufige
DIRK-Verfahren haben maximal Ordnung  ,
wobei dieses Maximum nicht für beliebige Stufen erreicht werden kann. Die in der
Praxis verwandten Verfahren haben in der Regel Ordnung
oder weniger.
,
wobei dieses Maximum nicht für beliebige Stufen erreicht werden kann. Die in der
Praxis verwandten Verfahren haben in der Regel Ordnung
oder weniger.
Als Alternative zu DIRK-Verfahren haben sich noch die linear impliziten Verfahren etabliert, insbesondere die Rosenbrock-Wanner-Verfahren, bei denen die nichtlinearen Gleichungen durch lineare angenähert werden.
Zeitschrittweitensteuerung: Eingebettete Verfahren
Um die Effizienz der Verfahren zu erhöhen, ist es sinnvoll, den Zeitschritt
einer Fehlertoleranz anzupassen. Runge-Kutta-Verfahren bieten hierzu über
eingebettete Verfahren eine relativ einfache Möglichkeit. Diese bestehen aus
einem zweiten Satz an Koeffizienten  für ein zweites Verfahren:
für ein zweites Verfahren:

wobei die Koeffizienten so gewählt werden, dass sich ein schlechteres Verfahren, konkret ein Verfahren von niedrigerer Ordnung ergibt als das ursprüngliche. Dann ist die Differenz

eine Schätzung des lokalen Fehlers des ursprünglichen Verfahrens von der
Ordnung wie das eingebettete Verfahren. Zur Berechnung sind keine neuen
Funktionsauswertungen notwendig, sondern nur Linearkombinationen der bereits
berechneten .
Die Bestimmung einer neuen Zeitschrittweite aus dem Fehlerschätzer kann über
verschiedene Schrittweitensteuerungen
erfolgen.
Im expliziten Fall sind die bekanntesten eingebetteten Verfahren die Runge-Kutta-Fehlberg- sowie die Dormand-Prince-Formeln (DOPRI).
Geschichte
Die ersten Runge-Kutta-Verfahren wurden um 1900 von Karl Heun, Martin Wilhelm Kutta, und Carl Runge entwickelt. In den 1960ern entwickelte John C. Butcher mit den vereinfachenden Bedingungen und dem Butcher-Tableau Werkzeuge, um Verfahren höherer Ordnung zu entwickeln. Ernst Hairer fand 1978 ein Verfahren 8. Ordnung mit zehn Stufen.
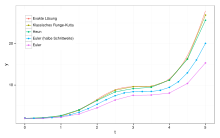
Beispiele
Das explizite Euler-Verfahren (Ordnung 1):

Das implizite Euler-Verfahren (Ordnung 1):

Das Heun-Verfahren (Ordnung 2):

Das Runge-Kutta-Verfahren der Ordnung 2:

Das implizite Trapez-Verfahren der Ordnung 2:

Das Runge-Kutta-Verfahren der Ordnung 3:

Das Heun-Verfahren 3. Ordnung:

Das klassische Runge-Kutta-Verfahren (Ordnung 4):



© biancahoegel.de
Datum der letzten Änderung: Jena, den: 19.06. 2020