Chi-Quadrat-Test
Mit Chi-Quadrat-Test ( -Test)
bezeichnet man in der mathematischen
Statistik eine Gruppe von Hypothesentests
mit -verteilter
Testprüfgröße.
-Test)
bezeichnet man in der mathematischen
Statistik eine Gruppe von Hypothesentests
mit -verteilter
Testprüfgröße.
Man unterscheidet vor allem die folgenden Tests:
- Verteilungstest (auch Anpassungstest genannt): Hier wird geprüft, ob vorliegende Daten auf eine bestimmte Weise verteilt sind.
- Unabhängigkeitstest: Hier wird geprüft, ob zwei Merkmale stochastisch unabhängig sind.
- Homogenitätstest: Hier wird geprüft, ob zwei oder mehr Stichproben derselben Verteilung bzw. einer homogenen Grundgesamtheit entstammen.
Der Chi-Quadrat-Test und seine Teststatistik wurden erstmals 1900 von Karl Pearson beschrieben.
Verteilungstest
Man betrachtet ein statistisches Merkmal  ,
dessen Wahrscheinlichkeiten in der Grundgesamtheit unbekannt sind. Es wird
bezüglich der Wahrscheinlichkeiten von
eine vorläufig allgemein formulierte Nullhypothese
,
dessen Wahrscheinlichkeiten in der Grundgesamtheit unbekannt sind. Es wird
bezüglich der Wahrscheinlichkeiten von
eine vorläufig allgemein formulierte Nullhypothese
 :
Das Merkmal
besitzt die Wahrscheinlichkeitsverteilung
:
Das Merkmal
besitzt die Wahrscheinlichkeitsverteilung

aufgestellt.
Vorgehensweise
Es liegen  unabhängige Beobachtungen
unabhängige Beobachtungen  des Merkmals
vor, die in
des Merkmals
vor, die in  verschiedene Kategorien fallen. Treten bei einem Merkmal sehr viele Ausprägungen
auf, fasst man sie zweckmäßigerweise in
Klassen zusammen und fasst die Klassen als Kategorien auf. Die Zahl der
Beobachtungen in der
verschiedene Kategorien fallen. Treten bei einem Merkmal sehr viele Ausprägungen
auf, fasst man sie zweckmäßigerweise in
Klassen zusammen und fasst die Klassen als Kategorien auf. Die Zahl der
Beobachtungen in der  -ten
Kategorie ist die beobachtete Häufigkeit
-ten
Kategorie ist die beobachtete Häufigkeit
 .
.
Man überlegt sich nun, wie viele Beobachtungen im Mittel in einer Kategorie
liegen müssten, wenn
tatsächlich die hypothetische Verteilung besäße. Dazu berechnet man zunächst die
Wahrscheinlichkeit
 ,
dass eine Ausprägung von
in die Kategorie
fällt. Die unter
,
dass eine Ausprägung von
in die Kategorie
fällt. Die unter  zu erwartende absolute Häufigkeit ist:
zu erwartende absolute Häufigkeit ist:

Wenn die in der vorliegenden Stichprobe beobachteten Häufigkeiten
„zu stark“ von den erwarteten Häufigkeiten abweichen, wird die Nullhypothese
abgelehnt. Die Prüfgröße für den Test

misst die Größe der Abweichung.
Die Prüfgröße
ist bei ausreichend großen
annähernd chi-Quadrat-verteilt
mit  Freiheitsgraden.
Wenn die Nullhypothese wahr ist, sollte der Unterschied zwischen der
beobachteten und der theoretisch erwarteten Häufigkeit klein sein. Also wird
bei einem hohen Prüfgrößenwert abgelehnt. Der Ablehnungsbereich für
liegt rechts.
Freiheitsgraden.
Wenn die Nullhypothese wahr ist, sollte der Unterschied zwischen der
beobachteten und der theoretisch erwarteten Häufigkeit klein sein. Also wird
bei einem hohen Prüfgrößenwert abgelehnt. Der Ablehnungsbereich für
liegt rechts.
Bei einem Signifikanzniveau
 wird
abgelehnt, wenn
wird
abgelehnt, wenn  gilt, wenn also der aus der Stichprobe erhaltene Wert der Prüfgröße größer als
das
gilt, wenn also der aus der Stichprobe erhaltene Wert der Prüfgröße größer als
das  -Quantil
der -Verteilung
mit
Freiheitsgraden ist.
-Quantil
der -Verteilung
mit
Freiheitsgraden ist.
Es existieren Tabellen der -Quantile
(kritische
Werte) in Abhängigkeit von der Anzahl der Freiheitsgrade
und vom gewünschten
Signifikanzniveau (siehe
unten).
Soll das Signifikanzniveau,
das zu einem bestimmten -Wert
gehört, bestimmt werden, so muss in der Regel aus der Tabelle ein Zwischenwert
berechnet werden. Dazu verwendet man logarithmische
Interpolation.
Besonderheiten
Schätzung von Verteilungsparametern
Im Allgemeinen gibt man bei der Verteilungshypothese die Parameter der
Verteilung an. Kann man diese nicht angeben, müssen sie aus der Stichprobe
geschätzt werden. Hier geht bei der -Verteilung
pro geschätztem Parameter ein Freiheitsgrad verloren. Sie hat also  Freiheitsgrade mit
Freiheitsgrade mit  als Zahl der geschätzten Parameter. Für die Normalverteilung wäre
als Zahl der geschätzten Parameter. Für die Normalverteilung wäre  ,
wenn der Erwartungswert
,
wenn der Erwartungswert  und die Varianz
und die Varianz  abgeschätzt werden.
abgeschätzt werden.
Mindestgröße der erwarteten Häufigkeiten
Damit die Prüfgröße als annähernd -verteilt
betrachtet werden kann, muss jede erwartete Häufigkeit eine gewisse Mindestgröße
betragen. Verschiedene Lehrwerke setzen diese bei 1 oder 5 an. Ist die erwartete
Häufigkeit zu klein, können gegebenenfalls mehrere Klassen zusammengefasst
werden, um die Mindestgröße zu erreichen.
Beispiel zu Verteilungstest
Es liegen von ca. 200 börsennotierten Unternehmen die Umsätze vor. Das folgende Histogramm zeigt ihre Verteilung.
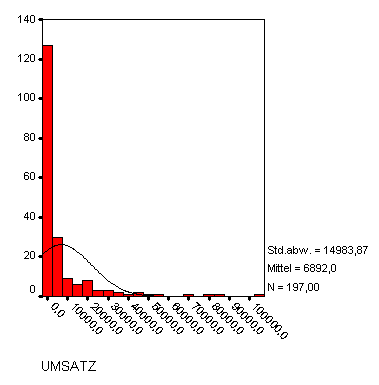
Es sei
der Umsatz eines Unternehmens [Mio. €].
Es soll nun die Hypothese getestet werden, dass
normalverteilt
ist.
Da die Daten in vielen verschiedenen Ausprägungen vorliegen, wurden sie in Klassen eingeteilt. Es ergab sich die Tabelle:
| Klasse | Intervall | Beobachtete Häufigkeit | |
| j | über | bis | nj |
| 1 | … | 0 | 0 |
| 2 | 0 | 5000 | 148 |
| 3 | 5000 | 10000 | 17 |
| 4 | 10000 | 15000 | 5 |
| 5 | 15000 | 20000 | 8 |
| 6 | 20000 | 25000 | 4 |
| 7 | 25000 | 30000 | 3 |
| 8 | 30000 | 35000 | 3 |
| 9 | 35000 | ... | 9 |
| Summe | 197 | ||
Da keine Parameter vorgegeben werden, werden sie aus der Stichprobe ermittelt. Es sind geschätzt

und

Es wird getestet:
- :
ist normalverteilt mit dem Erwartungswert
 und der Standardabweichung
und der Standardabweichung  .
.
Um die unter
erwarteten Häufigkeiten zu bestimmen, werden zunächst die Wahrscheinlichkeiten
berechnet, dass
in die vorgegebenen Klassen fällt. Man errechnet dann

Darin ist  eine standardnormalverteilte Zufallsvariable und
eine standardnormalverteilte Zufallsvariable und  ihre Verteilungsfunktion. Analog errechnet man:
ihre Verteilungsfunktion. Analog errechnet man:

- …

Daraus ergeben sich die erwarteten Häufigkeiten


- …
Es müssten also beispielsweise ca. 25 Unternehmen im Mittel einen Umsatz zwischen 0 € und 5000 € haben, wenn das Merkmal Umsatz tatsächlich normalverteilt ist.
Die erwarteten Häufigkeiten sind zusammen mit den beobachteten Häufigkeiten in der folgenden Tabelle aufgeführt.
| Klasse | Intervall | Beobachtete Häufigkeit | Wahrscheinlichkeit | Erwartete Häufigkeit | |
| j | über | bis | nj | p0j | n0j |
| 1 | … | 0 | 0 | 0,3228 | 63,59 |
| 2 | 0 | 5000 | 148 | 0,1270 | 25,02 |
| 3 | 5000 | 10000 | 17 | 0,1324 | 26,08 |
| 4 | 10000 | 15000 | 5 | 0,1236 | 24,35 |
| 5 | 15000 | 20000 | 8 | 0,1034 | 20,36 |
| 6 | 20000 | 25000 | 4 | 0,0774 | 15,25 |
| 7 | 25000 | 30000 | 3 | 0,0519 | 10,23 |
| 8 | 30000 | 35000 | 3 | 0,0312 | 6,14 |
| 9 | 35000 | … | 9 | 0,0303 | 5,98 |
| Summe | 197 | 1,0000 | 197,00 | ||
Die Prüfgröße wird jetzt folgendermaßen ermittelt:

Bei einem Signifikanzniveau  liegt der kritische Wert der Testprüfgröße
bei
liegt der kritische Wert der Testprüfgröße
bei  .
Da
.
Da  ,
wird die Nullhypothese abgelehnt. Man kann davon ausgehen, dass das Merkmal
Umsatz in der Grundgesamtheit nicht normalverteilt ist.
,
wird die Nullhypothese abgelehnt. Man kann davon ausgehen, dass das Merkmal
Umsatz in der Grundgesamtheit nicht normalverteilt ist.
Ergänzung
Die obigen Daten wurden in der Folge logarithmiert. Aufgrund des Ergebnisses des Tests des Datensatzes der logarithmierten Daten auf Normalverteilung konnte auf einem Signifikanzniveau von 0,05 die Nullhypothese der Normalverteilung der Daten nicht verworfen werden. Unter der Voraussetzung, dass die logarithmierten Umsatzdaten tatsächlich einer Normalverteilung entstammen, sind die ursprünglichen Umsatzdaten logarithmisch normalverteilt.
Das folgende Histogramm zeigt die Verteilung der logarithmierten Daten.
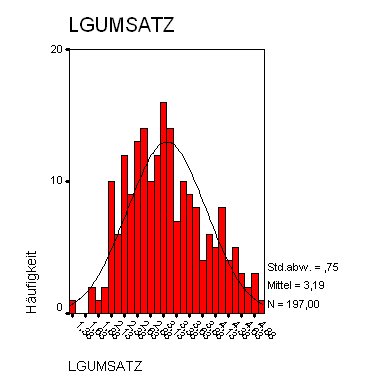
Unabhängigkeitstest
Der Unabhängigkeitstest ist ein Signifikanztest auf stochastische Unabhängigkeit in der Kontingenztafel.
Man betrachtet zwei statistische Merkmale
und  ,
die beliebig skaliert
sein können. Man interessiert sich dafür, ob die Merkmale stochastisch
unabhängig sind. Es wird die Nullhypothese
,
die beliebig skaliert
sein können. Man interessiert sich dafür, ob die Merkmale stochastisch
unabhängig sind. Es wird die Nullhypothese
- :
Die Merkmale
und
sind stochastisch unabhängig.
aufgestellt.
Vorgehensweise
Die Beobachtungen von
liegen in
Kategorien
 vor, die des Merkmals
in
vor, die des Merkmals
in  Kategorien
Kategorien 
 .
Treten bei einem Merkmal sehr viele Ausprägungen auf, fasst man sie
zweckmäßigerweise zu Klassen
zusammen und fasst die Klassenzugehörigkeit als -te
Kategorie auf. Es gibt insgesamt
paarweise Beobachtungen von
und ,
die sich auf
.
Treten bei einem Merkmal sehr viele Ausprägungen auf, fasst man sie
zweckmäßigerweise zu Klassen
zusammen und fasst die Klassenzugehörigkeit als -te
Kategorie auf. Es gibt insgesamt
paarweise Beobachtungen von
und ,
die sich auf  Kategorien verteilen.
Kategorien verteilen.
Konzeptionell ist der Test so aufzufassen:
Man betrachte zwei diskrete Zufallsvariablen
und ,
deren gemeinsame Wahrscheinlichkeiten in einer Wahrscheinlichkeitstabelle
dargestellt werden können.
Man zählt nun, wie oft die -te
Ausprägung von
zusammen mit der -ten
Ausprägung von
auftritt. Die beobachteten gemeinsamen absoluten Häufigkeiten  können in einer zweidimensionalen Häufigkeitstabelle mit
Zeilen und
Spalten eingetragen werden.
können in einer zweidimensionalen Häufigkeitstabelle mit
Zeilen und
Spalten eingetragen werden.
| Merkmal
|
Summe Σ | ||||||
| Merkmal
|
1 | 2 | … | k | … | r | nj. |
| 1 | n11 | n12 | ... | n1k | ... | n1r | n1. |
| 2 | n21 | n22 | … | n2k | … | n2r | n2. |
| … | … | … | … | … | … | … | … |
| j | nj1 | … | … | njk | … | … | nj. |
| … | … | … | … | … | … | … | … |
| m | nm1 | nm2 | … | nmk | … | nmr | nm. |
| Summe Σ | n.1 | n.2 | … | n.k | … | n.r | n |
Die Zeilen- bzw. Spaltensummen ergeben die absoluten Randhäufigkeiten  bzw.
bzw.  als
als
 und
und 
Entsprechend sind die gemeinsamen relativen Häufigkeiten  und die relativen Randhäufigkeiten
und die relativen Randhäufigkeiten  und
und  .
.
Wahrscheinlichkeitstheoretisch gilt: Sind zwei Ereignisse  und
und  stochastisch unabhängig, ist die Wahrscheinlichkeit für ihr gemeinsames
Auftreten gleich dem Produkt der Einzelwahrscheinlichkeiten:
stochastisch unabhängig, ist die Wahrscheinlichkeit für ihr gemeinsames
Auftreten gleich dem Produkt der Einzelwahrscheinlichkeiten:

Man überlegt sich nun, dass analog zu oben bei stochastischer Unabhängigkeit
von
und
auch gelten müsste

mit
multipliziert entsprechend
 oder auch
oder auch

Sind diese Differenzen für sämtliche  klein, kann man vermuten, dass
und
tatsächlich stochastisch unabhängig sind.
klein, kann man vermuten, dass
und
tatsächlich stochastisch unabhängig sind.
Setzt man für die erwartete Häufigkeit bei Vorliegen von Unabhängigkeit

resultiert aus der obigen Überlegung die Prüfgröße für den Unabhängigkeitstest

Die Prüfgröße
ist bei ausreichend großen erwarteten Häufigkeiten  annähernd -verteilt
mit
annähernd -verteilt
mit  Freiheitsgraden.
Freiheitsgraden.
Wenn die Prüfgröße klein ist, wird vermutet, dass die Hypothese wahr ist.
Also wird
bei einem hohen Prüfgrößenwert abgelehnt, der Ablehnungsbereich für
liegt rechts.
Bei einem Signifikanzniveau
wird
abgelehnt, wenn  ,
dem -Quantil
der -Verteilung
mit
Freiheitsgraden ist.
,
dem -Quantil
der -Verteilung
mit
Freiheitsgraden ist.
Besonderheiten
Damit die Prüfgröße als annähernd -verteilt
betrachtet werden kann, muss jede erwartete Häufigkeit
eine gewisse Mindestgröße haben. Verschiedene Lehrwerke setzen diese bei 1 oder
5 an. Ist die erwartete Häufigkeit zu klein, können gegebenenfalls mehrere
Klassen zusammengefasst werden, um die Mindestgröße zu erreichen.
Alternativ kann die Stichprobenverteilung der Teststatistik auf Basis der gegebenen Randverteilungen und der Annahme der Unabhängigkeit der Merkmale per Bootstrap untersucht werden.
Beispiel zum Unabhängigkeitstest
Im Rahmen des Qualitätsmanagements wurden die Kunden einer Bank befragt, unter anderem nach ihrer Zufriedenheit mit der Geschäftsabwicklung und nach der Gesamtzufriedenheit. Der Grad der Zufriedenheit richtete sich nach dem Schulnotensystem.
Aus den Daten ergibt sich die folgende Kreuztabelle der Gesamtzufriedenheit von Bankkunden versus ihrer Zufriedenheit mit der Geschäftsabwicklung. Man sieht, dass einige erwartete Häufigkeiten zu klein waren.
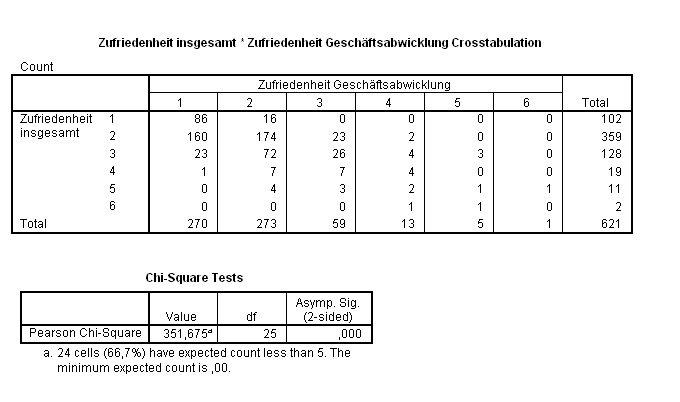
Eine Reduzierung der Kategorien auf jeweils drei durch Zusammenfassung der Noten 3–6 auf eine neue Gesamtnote 3 ergab methodisch korrekte Ergebnisse.
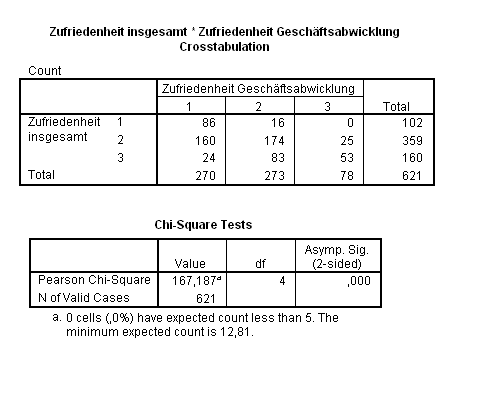
Die folgende Tabelle enthält die erwarteten Häufigkeiten ,
die sich so berechnen:

| Merkmal
| ||||
| Merkmal
|
1 | 2 | 3 | Σ |
| 1 | 44,35 | 44,84 | 12,81 | 102 |
| 2 | 156,09 | 157,82 | 45,09 | 359 |
| 3 | 69,57 | 70,34 | 20,10 | 160 |
| Σ | 270 | 273 | 78 | 621 |
Die Prüfgröße wird dann folgendermaßen ermittelt:

Bei einem
liegt der kritische Wert der Testprüfgröße bei  .
Da
.
Da  ist, wird die Hypothese signifikant abgelehnt, man vermutet also, dass die
Zufriedenheit mit der Geschäftsabwicklung und die Gesamtzufriedenheit assoziiert
sind.
ist, wird die Hypothese signifikant abgelehnt, man vermutet also, dass die
Zufriedenheit mit der Geschäftsabwicklung und die Gesamtzufriedenheit assoziiert
sind.
Homogenitätstest
Mit dem Chi-Quadrat-Homogenitätstest kann anhand der zugehörigen Stichprobenverteilungen
geprüft werden, ob  (unabhängige) Zufallsstichproben
diskreter Merkmale
(unabhängige) Zufallsstichproben
diskreter Merkmale  mit den Stichprobenumfängen
mit den Stichprobenumfängen
 aus identisch verteilten (also homogenen) Grundgesamtheiten
stammen. Damit ist er eine Hilfe bei der Entscheidung darüber, ob mehrere
Stichproben derselben Grundgesamtheit bzw. Verteilung entstammen bzw. bei der
Entscheidung, ob ein Merkmal in verschiedenen Grundgesamtheiten (z.B.
Männer und Frauen) auf die gleiche Art verteilt ist. Der Test ist wie die
anderen Chi-Quadrat-Tests auf jedem Skalenniveau
anwendbar.
aus identisch verteilten (also homogenen) Grundgesamtheiten
stammen. Damit ist er eine Hilfe bei der Entscheidung darüber, ob mehrere
Stichproben derselben Grundgesamtheit bzw. Verteilung entstammen bzw. bei der
Entscheidung, ob ein Merkmal in verschiedenen Grundgesamtheiten (z.B.
Männer und Frauen) auf die gleiche Art verteilt ist. Der Test ist wie die
anderen Chi-Quadrat-Tests auf jedem Skalenniveau
anwendbar.
Die Hypothesen lauten:
 Die unabhängigen Merkmale >
sind identisch verteilt.
Die unabhängigen Merkmale >
sind identisch verteilt. Mindestens zwei der Merkmale IMG class="text"
style="width: 11.82ex; height: 2.5ex; vertical-align: -0.67ex;"
alt="X_{1},\dotsc ,X_{m}" src="/svg/05cf5775bfc56b626404ef3e7016eae712eb8e6b.svg">
sind unterschiedlich verteilt.
Mindestens zwei der Merkmale IMG class="text"
style="width: 11.82ex; height: 2.5ex; vertical-align: -0.67ex;"
alt="X_{1},\dotsc ,X_{m}" src="/svg/05cf5775bfc56b626404ef3e7016eae712eb8e6b.svg">
sind unterschiedlich verteilt.
Wenn mit  die Verteilungsfunktion von
die Verteilungsfunktion von  angedeutet wird, können die Hypothesen auch wie folgt formuliert werden:
angedeutet wird, können die Hypothesen auch wie folgt formuliert werden:

 für mindestens ein
für mindestens ein 
Vorgehensweise
Die untersuchte Zufallsvariable (das Merkmal), z.B. Antwort auf „die Sonntagsfrage“, sei -fach
gestuft, d.h. es gibt
Merkmalskategorien (das Merkmal besitzt
Ausprägungen), z.B. SPD, CDU, B90/Grüne, FDP, Die Linke und Andere
(d.h.  ).
Die Stichproben
).
Die Stichproben  können z.B. die Umfrageergebnisse verschiedener
Meinungsforschungsinstitute sein. Von Interesse könnte dann sein, zu prüfen, ob
sich die Umfrageergebnisse signifikant unterscheiden.
können z.B. die Umfrageergebnisse verschiedener
Meinungsforschungsinstitute sein. Von Interesse könnte dann sein, zu prüfen, ob
sich die Umfrageergebnisse signifikant unterscheiden.
Die beobachteten Häufigkeiten je Stichprobe (Umfrage) und Merkmalskategorie
(genannte Partei)  werden in eine entsprechende
werden in eine entsprechende  -Kreuztabelle
eingetragen (hier 3×3):
-Kreuztabelle
eingetragen (hier 3×3):
Merkmalskategorie 
| ||||
|---|---|---|---|---|
Stichprobe 
|
Kategorie 1 | Kategorie 2 | Kategorie 3 | Summe |

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
| Summe | 
|

|

|

|
Untersucht werden nun die Abweichungen zwischen den beobachteten
(empirischen) Häufigkeits- bzw. Wahrscheinlichkeitsverteilungen der Stichproben
über die Kategorien des Merkmals. Die beobachteten Zellhäufigkeiten
werden mit den Häufigkeiten verglichen, die bei Gültigkeit der Nullhypothese zu
erwarten wären.
Aus den Randverteilungen werden die unter Gültigkeit der Nullhypothese einer homogenen Grundgesamtheit erwarteten Zellhäufigkeiten bestimmt:

bezeichnet die erwartete Anzahl von Beobachtungen (absolute Häufigkeit) von
Stichprobe  in Kategorie .
in Kategorie .
Anhand der so errechneten Größen wird folgende approximativ chi-Quadrat-verteilte Prüfgröße berechnet:

Um zu einer Testentscheidung zu gelangen, wird der erhaltene Wert der
Prüfgröße mit dem zugehörigen kritischen Wert verglichen, d.h. mit dem von
der Anzahl der Freiheitsgrade
und dem Signifikanzniveau
 abhängigen Quantil
der Chi-Quadrat-Verteilung
(alternativ kann der p-Wert
bestimmt werden). Sind die Abweichungen zwischen mindestens zwei
Stichprobenverteilungen signifikant, wird die Nullhypothese verworfen,
d.h. die Nullhypothese der Homogenität wird abgelehnt, falls
abhängigen Quantil
der Chi-Quadrat-Verteilung
(alternativ kann der p-Wert
bestimmt werden). Sind die Abweichungen zwischen mindestens zwei
Stichprobenverteilungen signifikant, wird die Nullhypothese verworfen,
d.h. die Nullhypothese der Homogenität wird abgelehnt, falls
 .
.
Der Ablehnungsbereich für
liegt rechts vom kritischen Wert.
Anwendungsbedingungen
Damit die Prüfgröße als näherungsweise (approximativ)  -verteilt
betrachtet werden kann, müssen folgende Approximationsbedingungen gelten:
-verteilt
betrachtet werden kann, müssen folgende Approximationsbedingungen gelten:
- „großer“ Stichprobenumfang (
 )
)  für alle
für alle 
- min. 80 % der

- Rinne (2003) und Voß (2000) fordern zusätzlich Zellhäufigkeiten

Sind einige erwartete Häufigkeiten zu klein, müssen mehrere Klassen bzw. Merkmalskategorien zusammengefasst werden, um die Approximationsbedingungen einzuhalten.
Besitzt die untersuchte Zufallsvariable sehr viele (mögliche) Ausprägungen,
z.B. weil die Variable metrisch stetig ist, fasst man diese
zweckmäßigerweise in
Klassen
(=Kategorien) zusammen, um die nun klassierte Zufallsvariable mit dem
Chi-Quadrat-Test untersuchen zu können. Hierbei ist jedoch zu beachten, dass die
Art und Weise der Klassierung der Beobachtungen das Testergebnis beeinflussen
kann.
Vergleich zu Unabhängigkeits- und Verteilungstest
Der Homogenitätstest kann auch als Unabhängigkeitstest interpretiert werden, wenn man die Stichproben als Ausprägungen eines zweiten Merkmals ansieht. Auch kann er als eine Form des Verteilungstests angesehen werden, bei der nicht eine empirische und eine theoretische Verteilung, sondern mehrere empirische Verteilungen verglichen werden. Unabhängigkeitstest und Verteilungstest sind jedoch Einstichprobenprobleme, während der Homogenitätstest ein Mehrstichprobenproblem darstellt. Beim Unabhängigkeitstest wird eine einzige Stichprobe bzgl. zweier Merkmale erhoben, beim Verteilungstest eine Stichprobe bzgl. einem Merkmal. Beim Homogenitätstest werden mehrere Stichproben bzgl. eines Merkmals erhoben.
Vierfeldertest
Der Chi-Quadrat-Vierfeldertest ist ein statistischer Test. Er dient dazu, zu prüfen, ob zwei dichotome Merkmale stochastisch unabhängig voneinander sind bzw. ob die Verteilung eines dichotomen Merkmals in zwei Gruppen identisch ist.
Vorgehensweise
Der Vierfeldertest beruht auf einer (2×2)-Kontingenztafel, die die (bivariate) Häufigkeitsverteilung zweier Merkmale visualisiert:
| Merkmal X | |||
|---|---|---|---|
| Merkmal Y | Ausprägung 1 | Ausprägung 2 | Zeilensumme |
| Ausprägung 1 | a | b | a+b |
| Ausprägung 2 | c | d | c+d |
| Spaltensumme | a+c | b+d | n = a+b+c+d |
Laut einer Faustformel muss der Erwartungswert aller vier Felder mindestens 5 betragen. Der Erwartungswert wird dabei berechnet aus Zeilensumme*Spaltensumme/Gesamtzahl. Bei einem Erwartungswert kleiner 5 empfehlen Statistiker den Exakten Fisher-Test.
Teststatistik
Um die Nullhypothese zu prüfen, dass beide Merkmale stochastisch unabhängig sind, wird zunächst folgende Prüfgröße für einen zweiseitigen Test berechnet:
 .
.
Die Prüfgröße ist näherungsweise chi-Quadrat-verteilt mit einem Freiheitsgrad. Sie sollte nur dann verwendet werden, wenn in jeder der beiden Stichproben mindestens sechs Merkmalsträger (Beobachtungen) enthalten sind.
Testentscheidung
Ist der auf Grund der Stichprobe erhaltene Prüfwert kleiner als der zum gewählten Signifikanzniveau gehörende kritische Wert (d.h. das entsprechende Quantil der Chi-Quadrat-Verteilung), dann konnte der Test nicht nachweisen, dass ein signifikanter Unterschied besteht. Errechnet sich dagegen ein Prüfwert, der größer oder gleich dem kritischen Wert ist, so besteht zwischen den Stichproben ein signifikanter Unterschied.
Die Wahrscheinlichkeit, dass der berechnete (oder ein noch größerer) Prüfwert nur zufällig auf Grund der Stichprobenziehung erhalten wurde (p-Wert), lässt sich wie folgt näherungsweise berechnen:

Die Näherung dieser (Faust-)Formel an den tatsächlichen p-Wert ist gut, wenn die Prüfgröße zwischen 2,0 und 8,0 liegt.
Beispiele und Anwendungen
Bei der Frage, ob eine medizinische Maßnahme wirksam ist oder nicht, ist der Vierfeldertest sehr hilfreich, da er sich auf das Hauptentscheidungskriterium konzentriert.
Beispiel 1
Man befragt jeweils 50 (zufällig ausgewählte) Frauen und Männer, ob sie rauchen oder nicht.
Man erhält das Ergebnis:
- Frauen: 25 Raucher, 25 Nichtraucher
- Männer: 30 Raucher, 20 Nichtraucher
Führt man auf Basis dieser Erhebung einen Vierfeldertest durch, dann ergibt sich anhand der oben dargestellten Formel ein Prüfwert von ca. 1. Da dieser Wert kleiner ist als der kritische Wert 3,841, kann die Nullhypothese, dass das Rauchverhalten vom Geschlecht unabhängig ist, nicht verworfen werden. Der Anteil der Raucher bzw. Nichtraucher unterscheidet sich zwischen den Geschlechtern nicht signifikant.
Beispiel 2
Man befragt jeweils 500 (zufällig ausgewählte) Frauen und Männer, ob sie rauchen oder nicht.
Folgende Daten werden erhalten:
- Frauen: 250 Nichtraucher, 250 Raucher
- Männer: 300 Nichtraucher, 200 Raucher
Hier ergibt sich anhand des Vierfeldertests ein Prüfwert von  ,
welcher größer als 3,841 ist. Da
,
welcher größer als 3,841 ist. Da  ,
kann die Nullhypothese, dass die Merkmale „Rauchverhalten“ und „Geschlecht“
stochastisch unabhängig voneinander sind, auf einem Signifikanzniveau von 0,05
abgelehnt werden.
,
kann die Nullhypothese, dass die Merkmale „Rauchverhalten“ und „Geschlecht“
stochastisch unabhängig voneinander sind, auf einem Signifikanzniveau von 0,05
abgelehnt werden.
Tabelle der Quantile der Chi-Quadrat-Verteilung
Die Tabelle zeigt die wichtigsten Quantile der Chi-Quadrat-Verteilung.
In der linken Spalte sind die Freiheitsgrade  und in der oberen Zeile die -Niveaus
eingetragen. Ablesebeispiel: Das Quantil der Chi-Quadrat-Verteilung bei 2
Freiheitsgraden und einem -Niveau
von 1 % beträgt 9,21.
und in der oberen Zeile die -Niveaus
eingetragen. Ablesebeispiel: Das Quantil der Chi-Quadrat-Verteilung bei 2
Freiheitsgraden und einem -Niveau
von 1 % beträgt 9,21.
-
1−α
0,900 0,950 0,975 0,990 0,995 0,999 1 2,71 3,84 5,02 6,63 7,88 10,83 2 4,61 5,99 7,38 9,21 10,60 13,82 3 6,25 7,81 9,35 11,34 12,84 16,27 4 7,78 9,49 11,14 13,28 14,86 18,47 5 9,24 11,07 12,83 15,09 16,75 20,52 6 10,64 12,59 14,45 16,81 18,55 22,46 7 12,02 14,07 16,01 18,48 20,28 24,32 8 13,36 15,51 17,53 20,09 21,95 26,12 9 14,68 16,92 19,02 21,67 23,59 27,88 10 15,99 18,31 20,48 23,21 25,19 29,59 11 17,28 19,68 21,92 24,72 26,76 31,26 12 18,55 21,03 23,34 26,22 28,30 32,91 13 19,81 22,36 24,74 27,69 29,82 34,53 14 21,06 23,68 26,12 29,14 31,32 36,12 15 22,31 25,00 27,49 30,58 32,80 37,70 16 23,54 26,30 28,85 32,00 34,27 39,25 17 24,77 27,59 30,19 33,41 35,72 40,79 18 25,99 28,87 31,53 34,81 37,16 42,31 19 27,20 30,14 32,85 36,19 38,58 43,82 20 28,41 31,41 34,17 37,57 40,00 45,31 21 29,62 32,67 35,48 38,93 41,40 46,80 22 30,81 33,92 36,78 40,29 42,80 48,27 23 32,01 35,17 38,08 41,64 44,18 49,73 24 33,20 36,42 39,36 42,98 45,56 51,18 25 34,38 37,65 40,65 44,31 46,93 52,62 26 35,56 38,89 41,92 45,64 48,29 54,05 27 36,74 40,11 43,19 46,96 49,64 55,48 28 37,92 41,34 44,46 48,28 50,99 56,89 29 39,09 42,56 45,72 49,59 52,34 58,30 30 40,26 43,77 46,98 50,89 53,67 59,70 40 51,81 55,76 59,34 63,69 66,77 73,40 50 63,17 67,50 71,42 76,15 79,49 86,66 60 74,40 79,08 83,30 88,38 91,95 99,61 70 85,53 90,53 95,02 100,43 104,21 112,32 80 96,58 101,88 106,63 112,33 116,32 124,84 90 107,57 113,15 118,14 124,12 128,30 137,21 100 118,50 124,34 129,56 135,81 140,17 149,45 200 226,02 233,99 241,06 249,45 255,26 267,54 300 331,79 341,40 349,87 359,91 366,84 381,43 400 436,65 447,63 457,31 468,72 476,61 493,13 500 540,93 553,13 563,85 576,49 585,21 603,45
Alternativen zum Chi-Quadrat-Test
Der Chi-Quadrat-Test ist immer noch weit verbreitet, obwohl heute bessere
Alternativen zur Verfügung stehen. Gerade bei kleinen Werten pro Zelle
(Faustregel:  )
ist die Prüfstatistik problematisch, während bei großen Stichproben der
Chi-Quadrat-Test nach wie vor zuverlässig ist.
)
ist die Prüfstatistik problematisch, während bei großen Stichproben der
Chi-Quadrat-Test nach wie vor zuverlässig ist.
Der ursprüngliche Vorteil des Chi-Quadrat-Tests lag darin, dass die
Prüfstatistik besonders für kleinere Tabellen auch von Hand berechnet werden
kann, denn der schwierigste Rechenschritt ist die Quadrierung, während der
genauere G-Test als schwierigsten
Rechenschritt eine Logarithmierung erfordert. Die Prüfstatistik  ist annähernd Chi-Quadrat-verteilt und ist auch dann robust, wenn die
Kontingenztafel seltene Ereignisse enthält.
ist annähernd Chi-Quadrat-verteilt und ist auch dann robust, wenn die
Kontingenztafel seltene Ereignisse enthält.
In der Computerlinguistik hat sich der G-Test durchsetzen können, da dort die Häufigkeitsanalyse selten vorkommender Wörter und Textbausteine ein typisches Problem darstellt.
Da heutige Computer genug Rechenleistung bieten, lassen sich beide Tests durch den Exakten Test nach Fisher ersetzen.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 29.09. 2023