Schätzfunktion
Eine Schätzfunktion, auch Schätzstatistik oder kurz Schätzer, dient in der mathematischen Statistik dazu, aufgrund von vorhandenen empirischen Daten einer Stichprobe einen Schätzwert zu ermitteln und dadurch Informationen über unbekannte Parameter einer Grundgesamtheit zu erhalten. Schätzfunktionen sind die Basis zur Berechnung von Punktschätzungen und zur Bestimmung von Konfidenzintervallen mittels Bereichsschätzern und werden als Teststatistiken in Hypothesentests verwendet. Sie sind spezielle Stichprobenfunktionen und können durch Schätzverfahren, z.B. die Kleinste-Quadrate-Schätzung, die Maximum-Likelihood-Schätzung oder die Momentenmethode, bestimmt werden.
Im Rahmen der Entscheidungstheorie können Schätzfunktionen auch als Entscheidungsfunktionen bei Entscheidungen unter Unsicherheit betrachtet werden.
Formale Definition
Es sei
 ,
,
eine reellwertige Statistik
basierend auf einer Zufallsstichprobe  aus einer Verteilung mit Wahrscheinlichkeitsdichtefunktion
aus einer Verteilung mit Wahrscheinlichkeitsdichtefunktion
 ,
wobei
,
wobei  ein unbekannter skalarer Parameter ist. Wenn die Zufallsvariable
ein unbekannter skalarer Parameter ist. Wenn die Zufallsvariable  berechnet wird, um statistische Inferenz bzgl.
durchzuführen, spricht man von einem Schätzer. Falls die Stichprobengröße
berechnet wird, um statistische Inferenz bzgl.
durchzuführen, spricht man von einem Schätzer. Falls die Stichprobengröße
 nicht relevant ist, schreibt man auch
nicht relevant ist, schreibt man auch  statt .
Der konkrete Wert
statt .
Der konkrete Wert  ,
den ein Schätzer für eine Realisierung
,
den ein Schätzer für eine Realisierung
 der Zufallsstichprobe
annimmt, wird als Schätzung bezeichnet.
der Zufallsstichprobe
annimmt, wird als Schätzung bezeichnet.
Grundkonzepte: Stichprobenvariablen und -funktionen
In der Regel befindet sich der Experimentierende in der Situation, dass er anhand endlich vieler Beobachtungen (einer Stichprobe) Aussagen über die zugrunde liegende Verteilung oder deren Parameter in der Grundgesamtheit treffen möchte.
Nur in seltenen Fällen lässt sich die Grundgesamtheit vollständig erheben (Total- oder Vollerhebung), sodass sie dann exakt die gewünschten Informationen liefert. Ein Beispiel für eine Vollerhebung ist die Arbeitslosenstatistik der amtlichen Statistik.
In den meisten Fällen kann jedoch die Grundgesamtheit nicht vollständig
erhoben werden, z.B. weil sie zu groß ist. Interessiert man sich etwa für
die mittlere Größe der 18-Jährigen in der EU, müsste man alle 18-Jährigen
messen, was praktisch undurchführbar ist. Stattdessen wird nur eine Stichprobe, eine zufällige
Auswahl von
Elementen, erhoben (Teilerhebung).
Stichprobenvariable
An dieser Stelle setzt die statistische Modellierung an. Die
Stichprobenvariable  ,
eine Zufallsvariable,
beschreibt mit ihrer Verteilung die Wahrscheinlichkeit,
mit der eine bestimmte Merkmalsausprägung
bei der
,
eine Zufallsvariable,
beschreibt mit ihrer Verteilung die Wahrscheinlichkeit,
mit der eine bestimmte Merkmalsausprägung
bei der  -ten
Ziehung aus der Grundgesamtheit
auftritt. Jeder Beobachtungswert
-ten
Ziehung aus der Grundgesamtheit
auftritt. Jeder Beobachtungswert  ist die Realisierung
einer Stichprobenvariable .
ist die Realisierung
einer Stichprobenvariable .
Stichprobenfunktion
Die Definition von Stichprobenvariablen
erlaubt die Definition von Stichprobenfunktionen analog z.B. zu Kennwerten
aus der deskriptiven Statistik:
| Arithmetisches Mittel | Stichprobenfunktion |
|---|---|

|

|
Da jede Stichprobe aufgrund der Zufälligkeit anders ausfällt, sind auch diese Stichprobenfunktionen Zufallsvariablen, deren Verteilung von
- der Art der Ziehung der Stichprobe aus der Grundgesamtheit und
- der Verteilung des Merkmals in der Grundgesamtheit
abhängt.
Stichprobenverteilung
Unter Stichprobenverteilung versteht man die Verteilung einer
Stichprobenfunktion  über alle möglichen Stichproben aus der Grundgesamtheit. Die Stichprobenfunktion
über alle möglichen Stichproben aus der Grundgesamtheit. Die Stichprobenfunktion
 ist in der Regel eine Schätzfunktion für einen unbekannten Parameter der
Grundgesamtheit oder eine Teststatistik für eine Hypothese über einen
unbekannten Parameter der Grundgesamtheit. Daher spricht man statt von
Stichprobenverteilung auch einfach von der Verteilung einer Schätzfunktion oder
Teststatistik. Die Verteilung der Stichprobenfunktion dient der Gewinnung von
Aussagen über unbekannte Parameter in der Grundgesamtheit aufgrund einer
Stichprobe.
ist in der Regel eine Schätzfunktion für einen unbekannten Parameter der
Grundgesamtheit oder eine Teststatistik für eine Hypothese über einen
unbekannten Parameter der Grundgesamtheit. Daher spricht man statt von
Stichprobenverteilung auch einfach von der Verteilung einer Schätzfunktion oder
Teststatistik. Die Verteilung der Stichprobenfunktion dient der Gewinnung von
Aussagen über unbekannte Parameter in der Grundgesamtheit aufgrund einer
Stichprobe.
Die Stichprobenverteilung ist ein frequentistisches Konzept, das bayessche Pendant ist die A-posteriori-Verteilung.
Berechnung der Stichprobenverteilung
Die Stichprobenverteilung für eine Stichprobenfunktion mit bestimmtem
Stichprobenumfang aus einer endlichen Grundgesamtheit lässt sich stets berechnen
(siehe die folgenden Beispiele), im Allgemeinen jedoch ist man eher an
generellen Formeln mit z.B. unbestimmtem Stichprobenumfang
interessiert. Wichtige Hilfsmittel sind dabei folgende Aussagen:
- Reproduktivität
der Normalverteilung:
Sind die Stichprobenvariablen
voneinander unabhängig und normalverteilt (
 ),
dann ist auch
),
dann ist auch  normalverteilt (
normalverteilt ( ).
). - Zentraler
Grenzwertsatz: Sind die Stichprobenvariablen
 voneinander unabhängig und existieren für sie die Erwartungswerte
voneinander unabhängig und existieren für sie die Erwartungswerte  und
und  ,
ist
für großes
approximativ normalverteilt (
,
ist
für großes
approximativ normalverteilt ( ).
).
Bootstrap-Stichprobenverteilungen
Wenn eine hinreichend große Stichprobe repräsentativ für die Grundgesamtheit
ist, kann die Stichprobenverteilung für eine beliebige Stichprobenfunktion
nichtparametrisch mit Hilfe des
Bootstrap-Verfahrens
geschätzt werden, ohne dass die Verteilung der
bekannt sein muss. Jedoch muss allgemein mathematisch gezeigt werden, dass die
Bootstrap-Stichprobenverteilungen mit steigender Zahl der Bootstrap-Stichproben
gegen die wahre
Stichprobenverteilung konvergiert.
Beispiele
Beispiel 1
Gegeben sei eine Urne mit sieben Kugeln mit den Aufschriften 10, 11, 11, 12, 12, 12 und 16. Wenn man zwei Kugeln mit Zurücklegen zieht, zeigt die folgende Tabelle alle möglichen Stichproben aus der Grundgesamtheit:
| 10 | 11 | 11 | 12 | 12 | 12 | 16 | |
|---|---|---|---|---|---|---|---|
| 10 | 10;10 | 10;11 | 10;11 | 10;12 | 10;12 | 10;12 | 10;16 |
| 11 | 11;10 | 11;11 | 11;11 | 11;12 | 11;12 | 11;12 | 11;16 |
| 11 | 11;10 | 11;11 | 11;11 | 11;12 | 11;12 | 11;12 | 11;16 |
| 12 | 12;10 | 12;11 | 12;11 | 12;12 | 12;12 | 12;12 | 12;16 |
| 12 | 12;10 | 12;11 | 12;11 | 12;12 | 12;12 | 12;12 | 12;16 |
| 12 | 12;10 | 12;11 | 12;11 | 12;12 | 12;12 | 12;12 | 12;16 |
| 16 | 16;10 | 16;11 | 16;11 | 16;12 | 16;12 | 16;12 | 16;16 |
Jede der möglichen Stichproben tritt mit der Wahrscheinlichkeit von  auf. Berechnet man nun den Stichprobenmittelwert
auf. Berechnet man nun den Stichprobenmittelwert  aus den zwei Kugeln, so ergibt sich:
aus den zwei Kugeln, so ergibt sich:
 |
10 | 11 | 11 | 12 | 12 | 12 | 16 |
|---|---|---|---|---|---|---|---|
| 10 | 10,0 | 10,5 | 10,5 | 11,0 | 11,0 | 11,0 | 13,0 |
| 11 | 10,5 | 11,0 | 11,0 | 11,5 | 11,5 | 11,5 | 13,5 |
| 11 | 10,5 | 11,0 | 11,0 | 11,5 | 11,5 | 11,5 | 13,5 |
| 12 | 11,0 | 11,5 | 11,5 | 12,0 | 12,0 | 12,0 | 14,0 |
| 12 | 11,0 | 11,5 | 11,5 | 12,0 | 12,0 | 12,0 | 14,0 |
| 12 | 11,0 | 11,5 | 11,5 | 12,0 | 12,0 | 12,0 | 14,0 |
| 16 | 13,0 | 13,5 | 13,5 | 14,0 | 14,0 | 14,0 | 16,0 |
Fasst man die Ergebnisse von
entsprechend der Wahrscheinlichkeit des Auftretens der Stichprobe zusammen, so
erhält man die Stichprobenverteilung von :
 |
10,0 | 10,5 | 11,0 | 11,5 | 12,0 | 13,0 | 13,5 | 14,0 | 16,0 |
 |
1/49 | 4/49 | 10/49 | 12/49 | 9/49 | 2/49 | 4/49 | 6/49 | 1/49 |
Ändert man die Art der Ziehung, von einer Ziehung mit Zurücklegen in
eine Ziehung ohne Zurücklegen, so ergibt sich eine andere Verteilung für
.
In den oberen Tabellen fällt dann die Hauptdiagonale weg, sodass es nur  mögliche Stichproben gibt. Daher ergibt sich dann folgende Verteilung für :
mögliche Stichproben gibt. Daher ergibt sich dann folgende Verteilung für :
|
10,0 | 10,5 | 11,0 | 11,5 | 12,0 | 13,0 | 13,5 | 14,0 | 16,0 |
|
0 | 4/42 | 8/42 | 12/42 | 6/42 | 2/42 | 4/42 | 6/42 | 0 |
Beispiel 2
In einer Urne sind fünf rote und vier blaue Kugeln. Es werden drei Kugeln
ohne Zurücklegen aus dieser Urne gezogen. Definiert man die Stichprobenfunktion
 :
Zahl der roten Kugeln unter den drei gezogenen, ist
hypergeometrisch
verteilt mit
:
Zahl der roten Kugeln unter den drei gezogenen, ist
hypergeometrisch
verteilt mit  als Zahl der roten Kugeln in der Urne,
als Zahl der roten Kugeln in der Urne,  als Gesamtzahl der Kugeln in der Urne und
als Gesamtzahl der Kugeln in der Urne und  als Zahl der Versuche. Hier können alle Informationen über die Verteilung von
gewonnen werden, weil sowohl das stochastische Modell (Ziehen aus einer Urne)
als auch die zugehörigen Parameter (Anzahl der roten und blauen Kugeln) bekannt
sind.
als Zahl der Versuche. Hier können alle Informationen über die Verteilung von
gewonnen werden, weil sowohl das stochastische Modell (Ziehen aus einer Urne)
als auch die zugehörigen Parameter (Anzahl der roten und blauen Kugeln) bekannt
sind.
Beispiel 3
Ein Lebensmittelgroßmarkt bekommt eine Lieferung von 2000 Gläsern mit Pflaumenkompott. Problematisch sind in den Früchten verbliebene Kerne. Der Kunde toleriert einen Anteil von Gläsern mit Kernen von 5 %. Er möchte sich bei dieser Lieferung vergewissern, dass diese Quote nicht überschritten wird. Eine komplette Erhebung der Grundgesamtheit von 2000 Gläsern ist allerdings nicht durchführbar, denn 2000 Gläser zu kontrollieren ist zu aufwendig und außerdem zerstört das Öffnen eines Glases die Ware.
Allerdings könnte man eine kleine Zahl von Gläsern zufällig aussuchen, also eine Stichprobe nehmen, und die Zahl der zu beanstandenden Gläser zählen. Übersteigt diese Zahl eine bestimmte Grenze, den kritischen Wert der Prüfgröße, geht man davon aus, dass auch in der Lieferung zu viele zu beanstandende Gläser sind.
Eine mögliche Stichprobenfunktion ist  ,
wobei
eine Zufallsvariable bezeichnet, die nur die Werte 1 (Glas enthält Pflaumen mit
Kern) oder 0 (Glas enthält keine Pflaumen mit Kern) annimmt.
,
wobei
eine Zufallsvariable bezeichnet, die nur die Werte 1 (Glas enthält Pflaumen mit
Kern) oder 0 (Glas enthält keine Pflaumen mit Kern) annimmt.
Wenn die Zufallsvariablen
Bernoulli-verteilt
sind, dann ist aufgrund des zentralen Grenzwertsatzes  approximativ normalverteilt.
approximativ normalverteilt.
Schätzfunktionen
Grundgedanke und Konzept der Schätzfunktion
Schätzfunktionen sind spezielle Stichprobenfunktionen, um Parameter oder Verteilungen der Grundgesamtheit zu bestimmen. Beeinflusst werden Schätzfunktionen unter anderem durch
- die Art der Ziehung der Stichprobe (z.B. Ziehen mit oder ohne Zurücklegen) und
- die Art der Schätzmethode (z.B. Methode der kleinsten Quadrate, Maximum-Likelihood-Methode oder Momentenmethode).
Man möchte letztlich versuchen, ausschließlich anhand des Wissens um das zu Grunde liegende Modell und die beobachtete Stichprobe etwa Intervalle anzugeben, die mit größter Wahrscheinlichkeit den wahren Parameter enthalten. Alternativ möchte man auch bei einer bestimmten Fehlerwahrscheinlichkeit testen, ob eine spezielle Vermutung über den Parameter (zum Beispiel, dass zu viele Gläser Kerne enthalten) bestätigt werden kann. Schätzfunktionen bilden in diesem Sinne die Basis für jede begründete Entscheidung über die Ausprägungen der Grundgesamtheit, die bestmögliche Wahl solcher Funktionen ist das Ergebnis der mathematischen Untersuchung.
Trifft man auf dieser Basis eine Entscheidung, z.B. geht die Lieferung zurück, besteht die Möglichkeit, dass die Entscheidung falsch ist. Es gibt folgende Fehlerquellen:
- Die Stichprobe ist nicht repräsentativ für die Grundgesamtheit, d.h., sie spiegelt die Grundgesamtheit nicht wider.
- Das Modell für die Zufallsvariablen
ist falsch.
- Die Stichprobe könnte untypisch ausgefallen sein, so dass man die Lieferung fälschlicherweise ablehnt.
Dennoch besteht in der Praxis zumeist keine Alternative zu statistischen Verfahren dieser Art. Den zuvor genannten Problemen tritt man auf verschiedene Weisen entgegen:
- Man versucht möglichst eine einfache Zufallsstichprobe zu ziehen.
- Die Modelle für die Zufallsvariablen
werden zum einen möglichst groß gewählt (so dass das "richtige" Modell
enthalten ist) und zum anderen wird die Schätzfunktion so gewählt, dass ihre
Verteilung für viele Modelle berechenbar ist (siehe Zentraler
Grenzwertsatz).
- Aufgrund der Schätzfunktion wird eine Irrtumswahrscheinlichkeit angegeben.
Formale Definition der Schätzfunktion
Grundlage einer jeden Schätzfunktion sind die Beobachtungen
eines statistischen Merkmals .
Modelltheoretisch wird dieses Merkmal idealisiert: Man geht davon aus, dass es
sich bei den Beobachtungen in Wahrheit um Realisierungen von Zufallsvariablen
handelt, deren „wahre“ Verteilung und „wahre“ Verteilungsparameter unbekannt
sind.
Um Informationen über die tatsächlichen Eigenschaften des Merkmals zu
erhalten, erhebt man eine Stichprobe von
Elementen. Mit Hilfe dieser Stichprobenelemente schätzt man dann die gesuchten
Parameter bzw. die gesuchte Verteilung.
Um also beispielsweise einen Parameter  einer unbekannten Verteilung zu schätzen, hat man es formal mit einer
Zufallsstichprobe vom Umfang
zu tun, es werden also
Realisierungen
(
einer unbekannten Verteilung zu schätzen, hat man es formal mit einer
Zufallsstichprobe vom Umfang
zu tun, es werden also
Realisierungen
( )
der Zufallsvariablen
beobachtet. Die Zufallsvariablen
werden dann mittels einer Schätzmethode in einer geeigneten Schätzfunktion
)
der Zufallsvariablen
beobachtet. Die Zufallsvariablen
werden dann mittels einer Schätzmethode in einer geeigneten Schätzfunktion  zusammengefasst. Formal wird dabei vorausgesetzt, dass
eine messbare
Funktion ist.
zusammengefasst. Formal wird dabei vorausgesetzt, dass
eine messbare
Funktion ist.
Zur Vereinfachung der Berechnung der Schätzfunktion wird oft vorausgesetzt,
dass die Zufallsvariablen
unabhängig voneinander und identisch verteilt sind, also die
gleiche Verteilung und die gleichen Verteilungsparameter besitzen.
Ausgewählte Schätzfunktionen
In der statistischen Praxis wird oft nach den folgenden Parametern der Grundgesamtheit gesucht:
- den Mittelwert
 und
und - der Varianz
 eines metrischen Merkmals sowie
eines metrischen Merkmals sowie - dem Anteilswert
einer dichotomen Grundgesamtheit.
Schätzfunktionen und Schätzwert für den Mittelwert
Der Erwartungswert
wird in der Regel mit dem arithmetischen Mittel der Stichprobe geschätzt:
| Schätzfunktion | Schätzwert |
|---|---|

|

|
Ist die Verteilung symmetrisch, kann auch der Median der Stichprobe als Schätzwert für den Erwartungswert verwendet werden:
| Schätzfunktion | Schätzwert |
|---|---|

|

|
wobei  die untere
Gaußklammer bezeichnet. Der Median ist also der Wert derjenigen
Zufallsvariable, die nach Sortierung der Daten "in der Mitte" liegt. Es befinden
sich also zahlenmäßig genauso viele Werte oberhalb wie unterhalb des Median.
die untere
Gaußklammer bezeichnet. Der Median ist also der Wert derjenigen
Zufallsvariable, die nach Sortierung der Daten "in der Mitte" liegt. Es befinden
sich also zahlenmäßig genauso viele Werte oberhalb wie unterhalb des Median.
Welche Schätzfunktion im Falle symmetrischer Verteilungen besser ist, hängt von der betrachteten Verteilungsfamilie ab.
Schätzfunktionen und Schätzwert für die Varianz
Für die Varianz
der Grundgesamtheit
verwendet man als Schätzfunktion meist die korrigierte
Stichprobenvarianz:
| Schätzfunktion | Schätzwert |
|---|---|

|

|
Typische andere Vorfaktoren sind auch  und
und  .
Alle diese Schätzer sind zwar asymptotisch
äquivalent, werden aber je nach Art der Stichprobe unterschiedlich benutzt
(siehe auch Stichprobenvarianz
(Schätzfunktion)).
.
Alle diese Schätzer sind zwar asymptotisch
äquivalent, werden aber je nach Art der Stichprobe unterschiedlich benutzt
(siehe auch Stichprobenvarianz
(Schätzfunktion)).
Schätzfunktionen und Schätzwert für den Anteilswert
Man betrachtet hier das Urnenmodell mit zwei Sorten Kugeln. Es soll der Anteilswert der Kugeln erster Sorte in der Grundgesamtheit geschätzt werden. Als Schätzfunktion verwendet man den Anteil der Kugeln erster Sorte in der Stichprobe.
| Schätzfunktion | Schätzwert |
|---|---|

|

|
mit :
Zahl der Kugeln erster Sorte in der Stichprobe und
eine binäre Zufallsvariable: Kugel der ersten Sorte in der -ten
Ziehung gezogen ( )
oder nicht gezogen (
)
oder nicht gezogen ( ).
).
Die Verteilung von  ist eine Binomialverteilung
im Modell mit Zurücklegen und eine hypergeometrische
Verteilung im Modell ohne Zurücklegen.
ist eine Binomialverteilung
im Modell mit Zurücklegen und eine hypergeometrische
Verteilung im Modell ohne Zurücklegen.
Verteilung der Schätzfunktionen
Die Verteilung der Schätzfunktionen hängt natürlich von der Verteilung des Merkmals in der Grundgesamtheit ab.
Seien  unabhängig
und identisch normalverteilte Zufallsvariablen mit Erwartungswert
und Varianz
.
Der Schätzer
(Stichprobenmittel)
als lineare
Transformation der
besitzt dann die Verteilung
unabhängig
und identisch normalverteilte Zufallsvariablen mit Erwartungswert
und Varianz
.
Der Schätzer
(Stichprobenmittel)
als lineare
Transformation der
besitzt dann die Verteilung
 .
.
Der Varianzschätzer  enthält eine Quadratsumme
von bezüglich
zentrierten
normalverteilten Zufallsvariablen. Deshalb ist der Ausdruck
enthält eine Quadratsumme
von bezüglich
zentrierten
normalverteilten Zufallsvariablen. Deshalb ist der Ausdruck

Chi-Quadrat-verteilt
mit  Freiheitsgraden.
Freiheitsgraden.
Ist die Verteilung des Merkmals unbekannt, kann bei Vorliegen der Voraussetzung des zentralen Grenzwertsatzes die Verteilung der Schätzfunktion näherungsweise mit der Normalverteilung oder einer ihrer abgeleiteten Verteilungen angegeben werden.
Gütekriterien von Schätzfunktionen
 (
( ).
Mit steigendem Stichprobenumfang wird der unbekannte Parameter
immer genauer geschätzt.
).
Mit steigendem Stichprobenumfang wird der unbekannte Parameter
immer genauer geschätzt.Erwartungstreue
Eine erwartungstreue
Schätzfunktion ist im Mittel (Erwartungswert) gleich dem wahren Parameter :
 .
.
Weicht  hingegen systematisch von
ab, ist der Schätzer verzerrt (englisch biased). Die Verzerrung
eines Schätzers
hingegen systematisch von
ab, ist der Schätzer verzerrt (englisch biased). Die Verzerrung
eines Schätzers  errechnet sich dabei zu
errechnet sich dabei zu
 .
.
Für eine lediglich asymptotisch erwartungstreue Schätzfunktion dagegen muss nur gelten:

Konsistenz
Eine Schätzfunktion heißt konsistent,
wenn für jedes  (Infinitesimalzahl)
gilt:
(Infinitesimalzahl)
gilt:
 .
.
mit  .
Man spricht hier von stochastischer
Konvergenz.
.
Man spricht hier von stochastischer
Konvergenz.
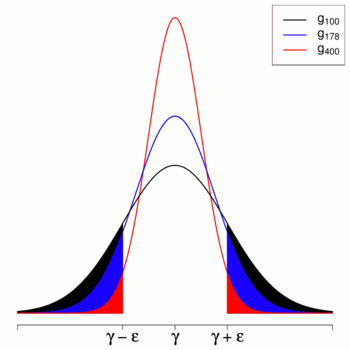
Die Grafik rechts illustriert den Prozess: Für jedes
müssen die ausgefüllten Flächen mit steigendem Stichprobenumfang immer kleiner
werden.
Mit einfachen Worten: Eine konsistente Schätzfunktion nähert sich mit
wachsendem
immer mehr dem wahren Parameter
an (schätzt den wahren Parameter immer genauer).
Konsistente Schätzfunktionen müssen daher mindestens asymptotisch erwartungstreu (s.o.) sein.
Diese Eigenschaft ist grundlegend für die gesamte induktive
Statistik; sie garantiert, dass eine Erhöhung des Stichprobenumfangs
genauere Schätzungen, kleinere Konfidenzintervalle oder kleinere Annahmebereiche der
 in Hypothesentests ermöglicht.
in Hypothesentests ermöglicht.
Minimale Varianz, Effizienz
Die Schätzfunktion soll eine möglichst kleine Varianz haben. Die
Schätzfunktion  aus allen erwartungstreuen Schätzfunktionen ,
welche die kleinste Varianz hat, wird dabei als effiziente,
beste oder wirksamste Schätzfunktion bezeichnet:
aus allen erwartungstreuen Schätzfunktionen ,
welche die kleinste Varianz hat, wird dabei als effiziente,
beste oder wirksamste Schätzfunktion bezeichnet:
 .
.
Unter bestimmten Bedingungen kann durch die Cramér-Rao-Ungleichung
auch eine untere Grenze für  angegeben werden. Das heißt, für eine Schätzfunktion kann gezeigt werden, dass
es keine effizienteren Schätzfunktionen geben kann; höchstens noch genauso
effiziente Schätzfunktionen.
angegeben werden. Das heißt, für eine Schätzfunktion kann gezeigt werden, dass
es keine effizienteren Schätzfunktionen geben kann; höchstens noch genauso
effiziente Schätzfunktionen.
Mittlerer quadratischer Fehler
Die Genauigkeit einer
Schätzfunktion bzw. eines Schätzers wird oft durch seinen mittleren
quadratischen Fehler (englisch mean squared error)
ausgedrückt. Eine (dabei nicht notwendigerweise auch erwartungstreue)
Schätzfunktion sollte daher stets einen möglichst kleinen mittleren
quadratischen Fehler aufweisen, der sich rechnerisch als Erwartungswert der
quadratischen Abweichung des Schätzers
vom wahren Parameter
bestimmen lässt:
![{\displaystyle \mathrm {MSE} (g_{n})=\operatorname {E} {\bigl [}(g_{n}-\gamma )^{2}{\bigr ]}={\bigl (}\operatorname {E} [g_{n}-\gamma ]{\bigr )}^{2}+\operatorname {E} {\bigl [}(g_{n}-E(g))^{2}{\bigr ]}=(\operatorname {Bias} (g_{n}))^{2}+\operatorname {Var} (g_{n})}](/svg/4532c1a3f8ea838394a81d07b9dbe008d5a36913.svg)
Wie zu sehen, ist der mittlere quadratische Fehler eines nicht erwartungstreuen Schätzers die Summe seiner Varianz und des Quadrats der Bias (Verzerrung); für erwartungstreue Schätzer dagegen sind Varianz und MSE gleich groß.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 24.10. 2025