Erwartungstreue
Erwartungstreue (selten Unverzerrtheit, englisch unbiasedness) bezeichnet in der mathematischen Statistik eine Eigenschaft einer Schätzfunktion (kurz: eines Schätzers). Ein Schätzer heißt erwartungstreu, wenn sein Erwartungswert gleich dem wahren Wert des zu schätzenden Parameters ist. Ist eine Schätzfunktion nicht erwartungstreu, spricht man davon, dass der Schätzer verzerrt ist. Das Ausmaß der Abweichung seines Erwartungswerts vom wahren Wert nennt man Verzerrung oder Bias. Das Bias drückt den systematischen Fehler des Schätzers aus.
Erwartungstreue zählt neben Konsistenz, Suffizienz und (asymptotischer) Effizienz zu den vier gebräuchlichen Kriterien zur Beurteilung der Qualität von Schätzern. Des Weiteren gehört sie gemeinsam mit der Suffizienz und der Invarianz/Äquivarianz zu den typischen Reduktionsprinzipien der mathematischen Statistik.
Bedeutung
Die Erwartungstreue ist eine wichtige Eigenschaft eines Schätzers, da die Varianz der meisten Schätzer mit steigendem Stichprobenumfang gegen Null konvergiert. D.h. die Verteilung zieht sich um den Erwartungswert des Schätzers, und damit bei erwartungstreuen Schätzern um den gesuchten wahren Parameter der Grundgesamtheit, zusammen. Bei erwartungstreuen Schätzern können wir erwarten, dass die Differenz zwischen dem aus der Stichprobe berechneten Schätzwert und dem wahren Parameter umso kleiner ist, je größer der Stichprobenumfang ist.
Außer zur praktischen Beurteilung der Qualität von Schätzern ist der Begriff der Erwartungstreue auch für die mathematische Schätztheorie von großer Bedeutung. In der Klasse aller erwartungstreuen Schätzer gelingt es – unter geeigneten Voraussetzungen an das zugrundeliegende Verteilungsmodell –, Existenz und Eindeutigkeit bester Schätzer zu beweisen. Das sind erwartungstreue Schätzer, die unter allen möglichen erwartungstreuen Schätzern minimale Varianz haben.
Grundidee und einführende Beispiele
Um einen unbekannten reellen Parameter  einer Grundgesamtheit zu schätzen, berechnet man in der mathematischen Statistik
aus einer zufälligen Stichprobe
einer Grundgesamtheit zu schätzen, berechnet man in der mathematischen Statistik
aus einer zufälligen Stichprobe
 mit Hilfe einer geeignet gewählten Funktion
mit Hilfe einer geeignet gewählten Funktion  eine Schätzung
eine Schätzung  .
Allgemein lassen sich geeignete Schätzfunktionen mit Hilfe von Schätzmethoden,
z.B. der Maximum-Likelihood-Methode,
gewinnen.
.
Allgemein lassen sich geeignete Schätzfunktionen mit Hilfe von Schätzmethoden,
z.B. der Maximum-Likelihood-Methode,
gewinnen.
Da die Stichprobenvariablen
Zufallsvariablen sind,
ist auch der Schätzer
selbst eine Zufallsvariable. Er wird erwartungstreu genannt, wenn der
Erwartungswert dieser Zufallsvariable stets gleich dem Parameter
ist, egal welchen Wert
in Wirklichkeit hat.
Beispiel Stichprobenmittel
Zur Schätzung des Erwartungswertes  der Grundgesamtheit wird üblicherweise das Stichprobenmittel
der Grundgesamtheit wird üblicherweise das Stichprobenmittel

verwendet. Werden alle Stichprobenvariablen  zufällig aus der Grundgesamtheit gezogen, so haben alle den Erwartungswert
zufällig aus der Grundgesamtheit gezogen, so haben alle den Erwartungswert  .
Damit berechnet sich der Erwartungswert des Stichprobenmittels zu
.
Damit berechnet sich der Erwartungswert des Stichprobenmittels zu
 .
.
Das Stichprobenmittel ist also ein erwartungstreuer Schätzer des unbekannten
Verteilungsparameters  .
.
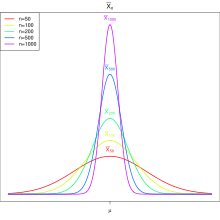
 für verschiedene Stichprobenumfänge
für verschiedene Stichprobenumfänge  .
.Falls die Grundgesamtheit normalverteilt
ist mit Erwartungswert
und Varianz  ,
dann lässt sich die Verteilung von
genau angeben. In diesem Fall gilt
,
dann lässt sich die Verteilung von
genau angeben. In diesem Fall gilt

das heißt, das Stichprobenmittel ist ebenfalls normalverteilt mit
Erwartungswert
und Varianz  .
Ist der Stichprobenumfang
groß, so gilt aufgrund des zentralen
Grenzwertsatzes diese Verteilungsaussage zumindest näherungsweise,
auch wenn die Grundgesamtheit nicht normalverteilt ist. Die Varianz dieses
Schätzers konvergiert also gegen 0, wenn der Stichprobenumfang
gegen unendlich geht. Die Grafik rechts zeigt, wie sich für verschiedene
Stichprobenumfänge die Verteilung der Stichprobenmittel immer weiter auf einen
festen Wert zusammenzieht. Aufgrund der Erwartungstreue ist sichergestellt, dass
dieser Wert der gesuchte Parameter
ist.
.
Ist der Stichprobenumfang
groß, so gilt aufgrund des zentralen
Grenzwertsatzes diese Verteilungsaussage zumindest näherungsweise,
auch wenn die Grundgesamtheit nicht normalverteilt ist. Die Varianz dieses
Schätzers konvergiert also gegen 0, wenn der Stichprobenumfang
gegen unendlich geht. Die Grafik rechts zeigt, wie sich für verschiedene
Stichprobenumfänge die Verteilung der Stichprobenmittel immer weiter auf einen
festen Wert zusammenzieht. Aufgrund der Erwartungstreue ist sichergestellt, dass
dieser Wert der gesuchte Parameter
ist.
Beispiel relative Häufigkeit
Um zu schätzen, mit welcher Wahrscheinlichkeit  ein bestimmtes Merkmal in der Grundgesamtheit auftritt, wird daraus eine
Stichprobe von Umfang
zufällig ausgewählt und die absolute
Häufigkeit
ein bestimmtes Merkmal in der Grundgesamtheit auftritt, wird daraus eine
Stichprobe von Umfang
zufällig ausgewählt und die absolute
Häufigkeit  >
des Merkmals in der Stichprobe ausgezählt. Die Zufallsvariable
ist dann binomialverteilt
mit den Parametern
und ,
insbesondere gilt für ihren Erwartungswert
>
des Merkmals in der Stichprobe ausgezählt. Die Zufallsvariable
ist dann binomialverteilt
mit den Parametern
und ,
insbesondere gilt für ihren Erwartungswert  .
Für die relative
Häufigkeit
.
Für die relative
Häufigkeit

folgt dann  das heißt, sie ist ein erwartungstreuer Schätzer der unbekannten
Wahrscheinlichkeit .
das heißt, sie ist ein erwartungstreuer Schätzer der unbekannten
Wahrscheinlichkeit .
Definition
In der modernen, maßtheoretisch
begründeten mathematischen Statistik wird ein statistisches Experiment durch ein
statistisches
Modell  beschrieben. Dieses besteht aus einer Menge
beschrieben. Dieses besteht aus einer Menge  ,
dem Stichprobenraum, zusammen mit einer σ-Algebra
,
dem Stichprobenraum, zusammen mit einer σ-Algebra
 und einer Familie
und einer Familie
 von Wahrscheinlichkeitsmaßen
auf .
von Wahrscheinlichkeitsmaßen
auf .
Es sei ein Punktschätzer

sowie eine zu schätzende Funktion

gegeben (im parametrischen Fall die sogenannte Parameterfunktion),
die jeder Wahrscheinlichkeitsverteilung  die zu schätzende Kennzahl
die zu schätzende Kennzahl  (Varianz, Median, Erwartungswert etc.) zuordnet.
(Varianz, Median, Erwartungswert etc.) zuordnet.
Dann heißt der Schätzer  erwartungstreu, wenn
erwartungstreu, wenn

für alle  ist. Hierbei bezeichnet
ist. Hierbei bezeichnet  den Erwartungswert bezüglich des Wahrscheinlichkeitsmaßes .
den Erwartungswert bezüglich des Wahrscheinlichkeitsmaßes .
In Anwendungen ist
oft die Verteilung
einer (reellen oder vektorwertigen) Zufallsvariable  auf einem Wahrscheinlichkeitsraum
auf einem Wahrscheinlichkeitsraum
 mit einem unbekannten Parameter oder Parametervektor
mit einem unbekannten Parameter oder Parametervektor  .
Ein Schätzer
für
.
Ein Schätzer
für  ist dann gegeben durch eine Funktion
ist dann gegeben durch eine Funktion  und diese heißt analog erwartungstreu, wenn gilt
und diese heißt analog erwartungstreu, wenn gilt

wobei der Erwartungswert nun bezüglich  gebildet wird.
gebildet wird.
Eigenschaften
Existenz
Erwartungstreue Schätzer müssen im Allgemeinen nicht existieren. Wesentlich
hierfür ist die Wahl der Funktion .
So kann bei unpassender Wahl der zu schätzenden Funktion die Menge der
erwartungstreuen Schätzer klein sein, unsinnige Eigenschaften aufweisen oder
leer sein.
Im Binomial-Modell
![{\displaystyle X=\{0,1,\dots ,n\},\;{\mathcal {A}}={\mathcal {P}}(X),\;P_{\vartheta }=\operatorname {Bin} _{n,\vartheta }{\text{ für }}\vartheta \in [0,1]}](/svg/e76c8b151f43d02d1b6e82ddae68d1d5378930fc.svg)
sind beispielsweise nur Polynome
in
von Grad kleinergleich n erwartungstreu schätzbar. Für zu schätzende Funktionen,
die nicht von der Form

sind existiert also kein erwartungstreuer Schätzer.
Im Poisson-Modell

und bei Verwendung der zu schätzenden Funktion

ergibt sich als einziger erwartungstreuer Schätzer
 .
.
Dieser Schätzer ist augenscheinlich sinnlos. Zu beachten ist hier, dass die Wahl der zu schätzenden Funktion nicht exotisch ist: Sie schätzt die Wahrscheinlichkeit, dass dreimal in Folge (bei unabhängiger Wiederholung) kein Ereignis eintritt.
Struktur
Gegeben sei ein fixes statistisches Modell. Sei  die Menge der erwartungstreuen Schätzer für die zu schätzende Funktion
und
die Menge der erwartungstreuen Schätzer für die zu schätzende Funktion
und  die Menge aller Nullschätzer, also
die Menge aller Nullschätzer, also
 .
.
Wählt man nun ein  aus, so ist
aus, so ist
 .
.
Die Menge aller erwartungstreuen Schätzer für
entstehen demnach aus einem erwartungstreuen Schätzer für
in Kombination mit den Nullschätzern.
Beziehung zu Verzerrung und MQF
Erwartungstreue Schätzer haben per Definition eine Verzerrung von Null:
 .
.
Damit reduziert sich der mittlere quadratische Fehler (MQF) zur Varianz des Schätzers:
 .
.
Optimalität
Erwartungstreue an sich ist bereits ein Qualitätskriterium, da erwartungstreue Schätzer immer eine Verzerrung von Null haben und somit im Mittel den zu schätzenden Wert liefern. Sie haben also keinen systematischen Fehler. In der Menge der erwartungstreuen Schätzer reduziert sich das zentrale Qualitätskriterium für Schätzer, der mittere quadratische Fehler, zu Varianz der Schätzer. Demnach vergleichen die beiden gängigen Optimalitätskriterien die Varianzen von Punktschätzern.
- Lokal
minimale Schätzer vergleichen die Varianzen von Punktschätzern für ein
vorgegebenes
 .
Ein Schätzer
.
Ein Schätzer  heißt dann ein lokal minimaler Schätzer in
heißt dann ein lokal minimaler Schätzer in  ,
wenn
,
wenn

- für alle weiteren erwartungstreuen Schätzer
gilt.
- Gleichmäßig
bester erwartungstreue Schätzer verschärfen diese Forderung dahingehend,
dass ein Schätzer
für alle
eine kleinere Varianz als jeder weitere erwartungstreue Schätzer haben soll.
Es gilt dann also

- und alle erwartungstreuen Schätzer .
Erwartungstreue vs. mittlerer quadratischer Fehler
Erwartungstreue Schätzer sind auf zwei Arten als „gut“ anzusehen:
- Einerseits ist ihre Verzerrung immer gleich null; sie haben demnach die wünschenswerte Eigenschaft, keinen systematischen Fehler aufzuweisen.
- Andererseits ist aufgrund der Zerlegung des mittleren quadratischen Fehlers in Verzerrung und Varianz der mittlere quadratische Fehler eines erwartungstreuen Schätzers immer automatisch klein, da die Verzerrung wegfällt.
Allerdings können nicht immer beide Ziele (Erwartungstreue und minimaler
quadratischer Fehler) gleichzeitig erfüllt werden. So ist im Binomialmodell
 mit
mit ![{\displaystyle \vartheta \in [0,1]}](/svg/41ffeb8c310c42bd652d8149e3a9b917e624ee1a.svg) ein gleichmäßig
bester erwartungstreuer Schätzer gegeben durch
ein gleichmäßig
bester erwartungstreuer Schätzer gegeben durch
 .
.
Der Schätzer

ist nicht erwartungstreu und folglich verzerrt, besitzt aber für Werte
von
nahe an  einen geringeren mittleren quadratischen Fehler.
einen geringeren mittleren quadratischen Fehler.
Es können also nicht immer Verzerrung und mittlerer quadratischer Fehler gleichzeitig minimiert werden.
Schätzer mit Verzerrung

Es ergibt sich aus der Definition, dass „gute“ Schätzer zumindest näherungsweise erwartungstreu sein, sich also dadurch auszeichnen sollen, dass sie im Mittel nah am zu schätzenden Wert liegen. Üblicherweise ist Erwartungstreue jedoch nicht das einzige wichtige Kriterium für die Qualität eines Schätzers; so sollte er beispielsweise auch eine kleine Varianz haben, also möglichst gering um den zu schätzenden Wert schwanken. Zusammengefasst ergibt sich das klassische Kriterium einer minimalen mittleren quadratischen Abweichung für optimale Schätzer.
Die Verzerrung  eines Schätzers
ist definiert als Differenz zwischen seinem Erwartungswert und der zu
schätzenden Größe:
eines Schätzers
ist definiert als Differenz zwischen seinem Erwartungswert und der zu
schätzenden Größe:

Sein mittlerer quadratischer Fehler  ist
ist

Der mittlere quadratische Fehler ist gleich der Summe des Quadrats der Verzerrung und der Varianz des Schätzers:

In der Praxis kann eine Verzerrung zwei Ursachen haben:
- einen systematischen Fehler, beispielsweise ein nicht-zufälliger Messfehler in der Apparatur, oder
- einen zufälligen Fehler, dessen Erwartungswert ungleich 0 ist.
Zufällige Fehler können tolerabel sein, wenn sie dazu beitragen, dass der Schätzer eine kleinere minimale quadratische Abweichung als ein unverzerrter besitzt.
Asymptotische Erwartungstreue
In der Regel ist es nicht von Bedeutung, dass ein Schätzer erwartungstreu
ist. Die meisten Resultate der mathematischen Statistik gelten erst asymptotisch, also wenn der
Stichprobenumfang ins
Unendliche wächst. Daher ist es in der Regel ausreichend, wenn Erwartungstreue
im Grenzwert gilt, d. h. für eine Folge von Schätzern  die Konvergenzaussage
die Konvergenzaussage  gilt.
gilt.
Weiteres Beispiel: Stichprobenvarianz im Normalverteilungsmodell
Ein typisches Beispiel sind Schätzer für die Parameter von Normalverteilungen. Man betrachtet in diesem Fall die parametrische Familie
 mit
mit  und
und  ,
,
wobei
die Normalverteilung mit Erwartungswert
und Varianz
ist. Üblicherweise sind Beobachtungen
gegeben, die stochastisch
unabhängig sind und jeweils die Verteilung
besitzen.
Wie bereits gesehen, ist das Stichprobenmittel
ein erwartungstreuer Schätzer von  .
.
Für die Varianz  erhält man als Maximum-Likelihood-Schätzer
erhält man als Maximum-Likelihood-Schätzer
 .
Dieser Schätzer ist allerdings nicht erwartungstreu, da sich
.
Dieser Schätzer ist allerdings nicht erwartungstreu, da sich  zeigen lässt (siehe Stichprobenvarianz
(Schätzfunktion)#Erwartungstreue). Die Verzerrung beträgt also
zeigen lässt (siehe Stichprobenvarianz
(Schätzfunktion)#Erwartungstreue). Die Verzerrung beträgt also  .
Da diese asymptotisch, also für
.
Da diese asymptotisch, also für  ,
verschwindet, ist der Schätzer allerdings asymptotisch erwartungstreu.
,
verschwindet, ist der Schätzer allerdings asymptotisch erwartungstreu.
Darüber hinaus kann man in diesem Fall den Erwartungswert der Verzerrung
genau angeben und folglich die Verzerrung korrigieren, indem man mit  multipliziert (sog. Bessel-Korrektur),
und erhält so einen Schätzer für die Varianz, der auch für kleine Stichproben
erwartungstreu ist.
multipliziert (sog. Bessel-Korrektur),
und erhält so einen Schätzer für die Varianz, der auch für kleine Stichproben
erwartungstreu ist.
Im Allgemeinen ist es jedoch nicht möglich, die erwartete Verzerrung exakt zu bestimmen und somit vollständig zu korrigieren. Es gibt aber Verfahren, um die Verzerrung eines asymptotisch erwartungstreuen Schätzers für endliche Stichproben zumindest zu verringern, zum Beispiel das sogenannte Jackknife.
Aufbauende Begriffe
Ein erwartungstreuer Schätzer
heißt ein regulärer erwartungstreuer Schätzer, wenn

gilt.  bezeichnet hier die Dichtefunktion zum Parameter .
Differentiation und Integration sollen also vertauschbar sein. Reguläre
erwartungstreue Schätzer spielen eine wichtige Rolle in der Cramér-Rao-Ungleichung.
bezeichnet hier die Dichtefunktion zum Parameter .
Differentiation und Integration sollen also vertauschbar sein. Reguläre
erwartungstreue Schätzer spielen eine wichtige Rolle in der Cramér-Rao-Ungleichung.
Verallgemeinerungen
Eine Verallgemeinerung der Erwartungstreue ist die L-Unverfälschtheit, sie verallgemeinert die Erwartungstreue mittels allgemeinerer Verlustfunktionen. Bei Verwendung des Gauß-Verlustes erhält man die Erwartungstreue als Spezialfall, bei Verwendung des Laplace-Verlustes die Median-Unverfälschtheit.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 03.04. 2026