Standardfehler
Der Standardfehler oder Stichprobenfehler ist ein Streuungsmaß für
eine Schätzfunktion
 der Grundgesamtheit.
Der Standardfehler ist definiert als die Standardabweichung
der Grundgesamtheit.
Der Standardfehler ist definiert als die Standardabweichung
 der Schätzfunktion,
der Schätzfunktion,  ,
das heißt also die positive Quadratwurzel
aus der Varianz.
In den Naturwissenschaften und der Metrologie wird auch der durch den GUM [1] geprägte Begriff
Standardunsicherheit
verwendet.
,
das heißt also die positive Quadratwurzel
aus der Varianz.
In den Naturwissenschaften und der Metrologie wird auch der durch den GUM [1] geprägte Begriff
Standardunsicherheit
verwendet.
Bei einem erwartungstreuen Schätzer ist daher der Standardfehler ein Maß für die durchschnittliche Abweichung des geschätzten Parameterwertes vom wahren Parameterwert. Je kleiner der Standardfehler ist, desto genauer kann der unbekannte Parameter mit Hilfe der Schätzfunktion geschätzt werden. Der Standardfehler hängt unter anderem ab von
- dem Stichprobenumfang und
- der Varianz in der Grundgesamtheit.
Allgemein gilt: Je größer der Stichprobenumfang, desto kleiner der Standardfehler; je kleiner die Varianz, desto kleiner der Standardfehler.
Eine wichtige Rolle spielt der Standardfehler auch bei der Berechnung von Schätzfehlern, Konfidenzintervallen und Teststatistiken.
Interpretation
Der Standardfehler liefert eine Aussage über die Güte des geschätzten Parameters. Je mehr Einzelwerte es gibt, desto kleiner ist der Standardfehler, und umso genauer kann der unbekannte Parameter geschätzt werden. Der Standardfehler macht die gemessene Streuung (Standardabweichung) zweier Datensätze mit unterschiedlichen Stichprobenumfängen vergleichbar, indem er die Standardabweichung auf den Stichprobenumfang normiert.
Wird mit Hilfe von mehreren Stichproben der unbekannte Parameter geschätzt, so werden die Ergebnisse von Stichprobe zu Stichprobe variieren. Natürlich stammt diese Variation nicht von einer Variation des unbekannten Parameters (denn der ist fix), sondern von Zufallseinflüssen, z.B. Messungenauigkeiten. Der Standardfehler ist die Standardabweichung der geschätzten Parameter in vielen Stichproben. Im Allgemeinen gilt: Für eine Halbierung des Standardfehlers ist eine Vervierfachung des Stichprobenumfangs nötig.
Im Gegensatz dazu bildet die Standardabweichung die in einer Grundgesamtheit tatsächlich vorhandene Streuung ab, die auch bei höchster Messgenauigkeit und unendlich vielen Einzelmessungen vorhanden ist (z.B. bei Gewichtsverteilung, Größenverteilung, Monatseinkommen). Sie zeigt, ob die Einzelwerte nahe beieinander liegen oder eine starke Spreizung der Daten vorliegt.
Beispiel
Angenommen, man untersucht die Grundgesamtheit von Kindern, die Gymnasien
besuchen, hinsichtlich ihrer Intelligenzleistung. Der unbekannte Parameter ist
also die mittlere Intelligenzleistung der Kinder, die ein Gymnasium besuchen.
Wenn nun zufällig aus dieser Grundgesamtheit eine Stichprobe des Umfanges  (also mit
Kindern) gezogen wird, dann kann man aus allen
Messergebnissen den Mittelwert
berechnen. Wenn nun nach dieser Stichprobe noch eine weitere, zufällig gezogene
Stichprobe mit der gleichen Anzahl von
Kindern gezogen und deren Mittelwert ermittelt wird, so werden die beiden
Mittelwerte nicht exakt übereinstimmen. Zieht man noch eine Vielzahl weiterer
zufälliger Stichproben des Umfanges ,
dann kann die Streuung aller empirisch ermittelten Mittelwerte um den Mittelwert
der Grundgesamtheit ermittelt werden. Diese Streuung ist der Standardfehler. Da
der Mittelwert der Stichprobenmittelwerte der beste Schätzer für den Mittelwert
der Grundgesamtheit ist, entspricht der Standardfehler der Streuung der
empirischen Mittelwerte um den Mittelwert der Grundgesamtheit. Er bildet nicht
die Intelligenzstreuung der Kinder, sondern die Genauigkeit des errechneten
Mittelwerts ab.
(also mit
Kindern) gezogen wird, dann kann man aus allen
Messergebnissen den Mittelwert
berechnen. Wenn nun nach dieser Stichprobe noch eine weitere, zufällig gezogene
Stichprobe mit der gleichen Anzahl von
Kindern gezogen und deren Mittelwert ermittelt wird, so werden die beiden
Mittelwerte nicht exakt übereinstimmen. Zieht man noch eine Vielzahl weiterer
zufälliger Stichproben des Umfanges ,
dann kann die Streuung aller empirisch ermittelten Mittelwerte um den Mittelwert
der Grundgesamtheit ermittelt werden. Diese Streuung ist der Standardfehler. Da
der Mittelwert der Stichprobenmittelwerte der beste Schätzer für den Mittelwert
der Grundgesamtheit ist, entspricht der Standardfehler der Streuung der
empirischen Mittelwerte um den Mittelwert der Grundgesamtheit. Er bildet nicht
die Intelligenzstreuung der Kinder, sondern die Genauigkeit des errechneten
Mittelwerts ab.
Notation
Für den Standardfehler benutzt man verschiedene Bezeichnungen um ihn von der
Standardabweichung  der Grundgesamtheit zu unterscheiden und um zu verdeutlichen, dass es sich um
die Streuung des geschätzten Parameters von Stichproben handelt:
der Grundgesamtheit zu unterscheiden und um zu verdeutlichen, dass es sich um
die Streuung des geschätzten Parameters von Stichproben handelt:
 ,
, oder
oder .
.
Schätzung
Da in den Standardfehler die Standardabweichung
der Grundgesamtheit eingeht, muss für eine Schätzung des Standardfehlers die
Standardabweichung in der Grundgesamtheit mit einem möglichst erwartungstreuen
Schätzer derselben geschätzt werden.
Konfidenzintervalle und Tests
Der Standardfehler spielt auch eine wichtige Rolle bei Konfidenzintervallen
und Tests. Wenn
die Schätzfunktion
erwartungstreu
und zumindest approximativ normalverteilt
( )
ist, dann ist
)
ist, dann ist
 .
.
Auf dieser Basis lassen sich  -Konfidenzintervalle
für den Parameter
angeben:
-Konfidenzintervalle
für den Parameter
angeben:

bzw. Tests formulieren, z. B. ob der Parameter einen bestimmten Wert  annimmt:
annimmt:
 vs.
vs. 
und die Teststatistik ergibt sich zu:
 .
.
 ist das
ist das  -Quantil
der Standardnormalverteilung und sind auch der kritische
Wert für den formulierten Test. In der Regel muss
aus der Stichprobe geschätzt werden, so dass
-Quantil
der Standardnormalverteilung und sind auch der kritische
Wert für den formulierten Test. In der Regel muss
aus der Stichprobe geschätzt werden, so dass

gilt, wobei
die Anzahl der Beobachtungen ist. Für  kann die t-Verteilung
durch die Standardnormalverteilung approximiert werden.
kann die t-Verteilung
durch die Standardnormalverteilung approximiert werden.
Standardfehler des arithmetischen Mittels
Der Standardfehler des arithmetischen Mittels ist gleich
 ,
,
wobei
die Standardabweichung einer einzelnen Messung bezeichnet.
Herleitung
Der Mittelwert einer Stichprobe vom Umfang
ist definiert durch

Betrachtet man die Schätzfunktion

mit unabhängigen,
identisch verteilten Zufallsvariablen  mit endlicher Varianz
mit endlicher Varianz  ,
so ist der Standardfehler definiert als die Wurzel aus der Varianz von
,
so ist der Standardfehler definiert als die Wurzel aus der Varianz von  .
Man berechnet unter Verwendung der Rechenregeln
für Varianzen und der Gleichung
von Bienaymé:
.
Man berechnet unter Verwendung der Rechenregeln
für Varianzen und der Gleichung
von Bienaymé:

woraus die Formel für den Standardfehler folgt. Falls  gilt, so folgt analog
gilt, so folgt analog
 .
.
Berechnung
von
Unterstellt man eine Stichprobenverteilung, so kann der Standardfehler anhand der Varianz der Stichprobenverteilung berechnet werden:
- bei der Binomialverteilung
mit Parametern

 ,
,
- bei der Exponentialverteilung
mit Parameter
 (Erwartungswert = Standardabweichung =
(Erwartungswert = Standardabweichung =  ):
):

- und bei der Poisson-Verteilung
mit Parameter
(Erwartungswert = Varianz = ):

Dabei bezeichnen
 die Standardfehler der jeweiligen Verteilung, und
die Standardfehler der jeweiligen Verteilung, und-
den Stichprobenumfang.
Soll der Standardfehler für den Mittelwert geschätzt werden, dann wird die
Varianz
mit der korrigierten
Stichprobenvarianz geschätzt.
Beispiel
Für die Eiscreme-Daten wurde für den Pro-Kopf-Verbrauch von Eiscreme (gemessen in Pint) das arithmetische Mittel, dessen Standardfehler und die Standardabweichung für die Jahre 1951, 1952 und 1953 berechnet.
| Jahr | Mittelwert | Standardfehler des Mittelwerts |
Standard- abweichung |
Anzahl der Beobachtungen |
|---|---|---|---|---|
| 1951 | 0,34680 | 0,01891 | 0,05980 | 10 |
| 1952 | 0,34954 | 0,01636 | 0,05899 | 13 |
| 1953 | 0,39586 | 0,03064 | 0,08106 | 7 |
Für die Jahre 1951 und 1952 sind die geschätzten Mittelwerte und Standardabweichungen sowie die Beobachtungszahlen etwa gleich. Deswegen ergeben die geschätzten Standardfehler auch etwa den gleichen Wert. Im Jahr 1953 sind zum einen die Beobachtungszahlen geringer als auch die Standardabweichung größer. Daher ist der Standardfehler fast doppelt so groß wie die Standardfehler aus den Jahren 1951 und 1952.
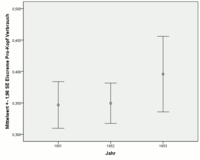
Die grafische Darstellung kann mittels eines Fehlerbalkendiagramms
erfolgen. Rechts werden die 95 %-Schätzintervalle für die Jahre 1951, 1952
und 1953 dargestellt. Wenn die Stichprobenfunktion
 zumindest approximativ normalverteilt ist, dann sind die
95 %-Schätzintervalle gegeben durch
zumindest approximativ normalverteilt ist, dann sind die
95 %-Schätzintervalle gegeben durch  mit
mit  und
und  die Stichprobenmittelwerte und
die Stichprobenmittelwerte und  die Stichprobenvarianzen.
die Stichprobenvarianzen.
Auch hier sieht man deutlich, dass der Mittelwert 1953 ungenauer geschätzt werden kann als die Mittelwerte von 1951 und 1952 (längerer Balken für 1953).
Standardfehler der Regressionskoeffizienten im einfachen Regressionsmodell
Im klassischen
Regressionsmodell für die einfache
lineare Regression  wird vorausgesetzt, dass
wird vorausgesetzt, dass
- die Störterme
 normalverteilt
sind,
normalverteilt
sind, - die Störterme unabhängig sind und
- die Werte
 fix sind (also keine Zufallsvariablen),
fix sind (also keine Zufallsvariablen),
wobei  die gemachten Beobachtungen durchläuft. Für die Schätzfunktionen
die gemachten Beobachtungen durchläuft. Für die Schätzfunktionen
 und
und

ergibt sich dann
 und
und  .
.
Die Standardfehler der Regressionskoeffizienten ergeben sich zu

und
 .
.
Beispiel: Für die Eiscreme-Daten wurde für den Pro-Kopf-Verbrauch von Eiscreme (gemessen in halbe Liter) eine einfache lineare Regression mit der mittleren Wochentemperatur (in Fahrenheit) als unabhängige Variable durchgeführt. Die Schätzung des Regressionsmodells ergab:
 .
.
| Modell | Nicht standardisierte Koeffizienten | Standardisierte Koeffizienten |
T | Sig. | |
|---|---|---|---|---|---|
| Regressionskoeffizienten | Standardfehler | ||||
| Konstante | 0,20686 | 0,02470 | 8,375 | 0,000 | |
| Temperatur | 0,00311 | 0,00048 | 0,776 | 6,502 | 0,000 |
Zwar ist der geschätzte Regressionkoeffizient für die mittlere Wochentemperatur sehr klein, jedoch ergab der geschätzte Standardfehler einen noch kleineren Wert. Die Genauigkeit, mit der der Regressionskoeffizient geschätzt wird, ist gut 6,5 mal so klein wie der Koeffizient selbst.
Anmerkungen
- ↑ GUM ist die Abkürzung für den 1993 veröffentlichten und zuletzt 2008 überarbeiteten ISO/BIPM-Leitfaden „Guide to the Expression of Uncertainty in Measurement“. Die Technische Regel ISO/IEC Guide 98-3:2008-09 Messunsicherheit – Teil 3: Leitfaden zur Angabe der Unsicherheit beim Messen ist identisch mit dem frei verfügbaren Leitfaden JCGM 100:2008 Evaluation of measurement data — Guide to the expression of uncertainty in measurement.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 29.09. 2023