Störgröße und Residuum
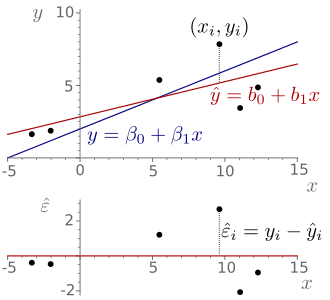
 und geschätzte Regressionsgerade
und geschätzte Regressionsgerade  .
Das Residuum
.
Das Residuum  ist die Differenz zwischen dem Messwert
ist die Differenz zwischen dem Messwert  und Schätzwert
und Schätzwert  .
.In der Statistik sind Störgröße und Residuum zwei eng verwandte Konzepte. Die Störgrößen (nicht zu verwechseln mit Störparametern, oder Störfaktoren), auch Störvariablen, Störterme, Fehlerterme, oder kurz Fehler genannt, sind in einer einfachen oder multiplen Regressionsgleichung unbeobachtbare Zufallsvariablen, die den vertikalen Abstand zwischen Beobachtungspunkt und wahrer Gerade (Regressionsfunktion der Grundgesamtheit) messen. Für sie nimmt man für gewöhnlich an, dass sie unkorreliert sind, einen Erwartungswert von Null und eine homogene Varianz aufweisen (Gauß-Markow-Annahmen). Sie beinhalten unbeobachtete Faktoren, die sich auf die abhängige Variable auswirken. Die Störgröße kann auch Messfehler in den beobachteten abhängigen oder unabhängigen Variablen enthalten.
Im Gegensatz zu den Störgrößen sind Residuen (lateinisch residuum = „das Zurückgebliebene“) berechnete Größen und messen den vertikalen Abstand zwischen Beobachtungspunkt und der geschätzten Regressionsgerade. Mitunter wird das Residuum auch als „geschätztes Residuum“ bezeichnet. Diese Benennung ist problematisch, da die Störgröße eine Zufallsvariable und kein Parameter ist. Von einer Schätzung der Störgröße kann daher nicht die Rede sein.
Die Problematik bei der sogenannten Regressionsdiagnostik
ist, dass sich die Gauß-Markow-Annahmen nur auf die Störgrößen, nicht aber auf
die Residuen beziehen. Die Residuen haben zwar ebenfalls einen Erwartungswert
von Null, sind aber nicht unkorreliert und weisen auch keine homogene Varianz
auf. Um diesem Missstand Rechnung zu tragen, werden die Residuen meist
modifiziert, um die geforderten Annahmen zu erfüllen, z.B. studentisierte
Residuen. Die Quadratsumme
der Residuen spielt in der Statistik in vielen Anwendungen eine große Rolle,
z.B. bei der Methode
der kleinsten Quadrate. Die Notation der Störgrößen als  bzw.
bzw.  ist an das lateinische Wort erratum (Irrtum) angelehnt. Die Residuen
können mit Hilfe der Residualmatrix
generiert werden.
ist an das lateinische Wort erratum (Irrtum) angelehnt. Die Residuen
können mit Hilfe der Residualmatrix
generiert werden.
Störgröße und Residuum
Störgrößen sind nicht mit den Residuen zu verwechseln. Man unterscheidet die beiden Konzepte wie folgt:
- :
Unbeobachtbare zufällige
Störgrößen, die den vertikalen Abstand zwischen Beobachtungspunkt und
theoretischer (wahrer
Gerade) messen
 :
Messen den vertikalen Abstand zwischen empirischer Beobachtung und der
geschätzten Regressionsgerade
:
Messen den vertikalen Abstand zwischen empirischer Beobachtung und der
geschätzten Regressionsgerade
Einfache lineare Regression
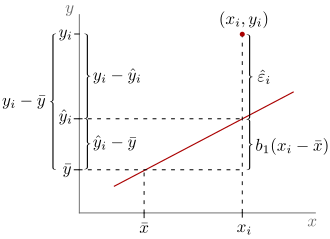
 in die „erklärte Abweichung“
in die „erklärte Abweichung“  und das „Residuum“
und das „Residuum“  .
.In der einfachen linearen Regression mit dem Modell der linearen
Einfachregression  sind die gewöhnlichen Residuen gegeben durch
sind die gewöhnlichen Residuen gegeben durch
 .
.
Hierbei handelt es sich um Residuen, da vom wahren
Wert ein geschätzter Wert abgezogen wird. Genauer gesagt werden von den
Beobachtungswerten
die angepassten Werte (englisch
fitted values)  abgezogen. In der einfachen linearen Regression werden an die Störgrößen für
gewöhnlich zahlreiche Annahmen getroffen.
abgezogen. In der einfachen linearen Regression werden an die Störgrößen für
gewöhnlich zahlreiche Annahmen getroffen.
Residualvarianz
Die Residualvarianz (auch Restvarianz genannt) ist eine Schätzung der Varianz
der Regressionsfunktion
in der Grundgesamtheit  .
In der einfachen linearen Regression ist eine durch die Maximum-Likelihood-Schätzung
gefundene Schätzung gegeben durch
.
In der einfachen linearen Regression ist eine durch die Maximum-Likelihood-Schätzung
gefundene Schätzung gegeben durch
 .
.
Allerdings erfüllt der Schätzer nicht gängige Qualitätskriterien
für Punktschätzer und wird daher nicht oft genutzt.
Beispielsweise ist der Schätzer nicht erwartungstreu für  .
In der einfachen
linearen Regression lässt sich unter den Voraussetzungen des klassischen
Modells der linearen Einfachregression zeigen, dass eine
erwartungstreue
Schätzung der Varianz der Störgrößen ,
d..h eine Schätzung, die
.
In der einfachen
linearen Regression lässt sich unter den Voraussetzungen des klassischen
Modells der linearen Einfachregression zeigen, dass eine
erwartungstreue
Schätzung der Varianz der Störgrößen ,
d..h eine Schätzung, die  erfüllt, gegeben ist durch die um die Anzahl
der Freiheitsgrade adjustierte Variante:
erfüllt, gegeben ist durch die um die Anzahl
der Freiheitsgrade adjustierte Variante:
 .
.
Die positive Quadratwurzel dieser erwartungstreuen Schätzfunktion wird auch als Standardfehler der Regression bezeichnet.
Residuen als Funktion der Störgrößen
In der einfachen linearen Regression lassen sich die Residuen als Funktion
der Störgrößen
für jede einzelne Beobachtung schreiben als
 .
.
Summe der Residuen
Die KQ-Regressionsgleichung wird so bestimmt, dass die Residuenquadratsumme zu einem Minimum wird. Äquivalent dazu bedeutet das, dass sich positive und negative Abweichungen von der Regressionsgeraden ausgleichen. Wenn das Modell der linearen Einfachregression einen – von Null verschiedenen – Achsenabschnitt enthält, dann muss also gelten, dass die Summe der Residuen Null ist

Multiple lineare Regression
Da die Residuen im Gegensatz zu den Störgrößen beobachtbar und berechnete
Größen sind, können sie graphisch dargestellt oder auf andere Weise untersucht
werden. Im Gegensatz zur einfachen linearen Regression, bei der eine Gerade
bestimmt wird, bestimmt man bei der multiplen linearen Regression (Erweiterung
der einfachen linearen Regression auf  Regressoren) eine Hyperebene,
die durch die Punktwolke verläuft. Falls zwei Regressoren vorliegen, liegen die
Beobachtungen bildlich gesprochen über beziehungsweise unter der
Regressionsebene. Die Differenzen der beobachteten und der vorhergesagten, auf
der Hyperebene liegenden -Werte,
stellen die Residuen dar.
Für sie gilt:
Regressoren) eine Hyperebene,
die durch die Punktwolke verläuft. Falls zwei Regressoren vorliegen, liegen die
Beobachtungen bildlich gesprochen über beziehungsweise unter der
Regressionsebene. Die Differenzen der beobachteten und der vorhergesagten, auf
der Hyperebene liegenden -Werte,
stellen die Residuen dar.
Für sie gilt:
 .
.
Die Residuen, die durch die Kleinste-Quadrate-Schätzung gewonnen werden,
werden gewöhnliche Residuen genannt. Wenn zusätzlich  Beobachtungen vorliegen, dann sind die gewöhnlichen KQ-Residuen in
der multiplen
linearen Regression gegeben durch
Beobachtungen vorliegen, dann sind die gewöhnlichen KQ-Residuen in
der multiplen
linearen Regression gegeben durch
 ,
,
wobei  eine Projektionmatrix,
oder genauer gesagt die idempotente
und symmetrische
Residualmatrix
darstellt und
eine Projektionmatrix,
oder genauer gesagt die idempotente
und symmetrische
Residualmatrix
darstellt und  den KQ-Schätzer
im multiplen Fall darstellt.
den KQ-Schätzer
im multiplen Fall darstellt.
Eigenschaften
Die gewöhnlichen Residuen sind im Mittel
 ,
d.h.
,
d.h.

Die Kovarianzmatrix der gewöhnlichen Residuen ist gegeben durch
 .
.
Die gewöhnlichen Residuen sind also heteroskedastisch, da
 .
.
Dies bedeutet, dass für die gewöhnlichen Residuen die Gauß-Markow-Annahmen
nicht erfüllt sind, da die Homoskedastizitätsannahme  nicht zutrifft.
nicht zutrifft.
Mithilfe der Prädiktions- und der Residualmatrix lässt sich zeigen, dass die Residuen mit den vorhergesagten Werten unkorreliert sind
 .
.
Partielle Residuen
Partielle Residuen-Streudiagramme werden mithilfe von partiellen Residuen erstellt, die definiert sind durch
 .
.
Studentisierte Residuen
Für dieses einfache Modell sei die Versuchsplanmatrix

gegeben. Die Prädiktionsmatrix
 ist die Matrix der Orthogonalprojektion
auf den Spaltenraum der Versuchsplanmatrix.
ist gegeben durch
ist die Matrix der Orthogonalprojektion
auf den Spaltenraum der Versuchsplanmatrix.
ist gegeben durch
 .
.
Die statistischen Hebelwerte
 sind die
sind die  -ten
Diagonalelemente der Prädiktionsmatrix. Die Varianz des -ten
Residuums ist gegeben durch
-ten
Diagonalelemente der Prädiktionsmatrix. Die Varianz des -ten
Residuums ist gegeben durch
 .
.
In diesem Fall hat die Versuchsplanmatrix  nur zwei Spalten, was zu folgender Varianz führt
nur zwei Spalten, was zu folgender Varianz führt
 .
.
Die dazugehörigen studentisierten Residuen lauten
 .
.
Die studentisierten Residuen sind identisch (aber nicht unabhängig) verteilt und damit insbesondere homoskedastisch. Sie könnten somit eine Lösung für die Verletzung der Homoskedastizitätsannahme darstellen.
Aufbauende Maße
Residuenquadratsumme
Bildet man die Summe der quadrierten Residuen für alle Beobachtungen, so erhält man die Residuenquadratsumme:
 .
.
Diese spezielle Abweichungsquadratsumme taucht in vielen statistischen Maßen, wie z.B. dem Bestimmtheitsmaß, der F-Statistik und diversen Standardfehlern, wie dem Standardfehler der Regression auf. Die Minimierung der Residuenquadratsumme führt zum Kleinste-Quadrate-Schätzer.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 16.03. 2020