Homoskedastizität und Heteroskedastizität
Heteroskedastizität (auch Varianzheterogenität, oder Heteroskedastie; gr. σκεδαστός, skedastós, zerstreut, verteilt; zerstreubar) bedeutet in der Statistik, dass die Varianz der Störterme bedingt auf die erklärenden Variablen nicht konstant ist. Wenn die Varianz der Störterme (und somit die Varianz der erklärten Variablen selbst) für alle Ausprägungen der exogenen (Prädiktor)-Variablen nicht signifikant unterschiedlich ist, liegt Homoskedastizität (Varianzhomogenität auch Homoskedastie) vor. Der Begriff spielt insbesondere in der Ökonometrie und der empirischen Forschung eine wichtige Rolle. Die Homoskedastizitätsannahme ist ein wichtiger Bestandteil der Gauß-Markow-Annahmen.
Homoskedastizität und Heteroskedastizität
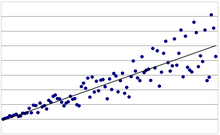
In der Statistik spielt die Verteilung von Merkmalen
eine entscheidende Rolle. Beispielsweise hat man in der Regressionsanalyse
eine Menge von Datenpunkten gegeben, in die eine Gerade möglichst passgenau
eingelegt wird. Die Abweichungen der Datenpunkte von der Geraden werden
Störterme oder Residuen
genannt und sind wahrscheinlichkeitstheoretisch jeweils Zufallsvariablen.
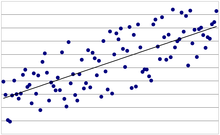
Homoskedastie bzw. Heteroskedastie bezieht sich auf die Verteilung dieser
Störterme, die mittels der Varianz erfasst wird. Haben diese Störterme  alle die gleiche Varianz, liegt Varianzhomogenität (d.h. Homoskedastie)
vor
alle die gleiche Varianz, liegt Varianzhomogenität (d.h. Homoskedastie)
vor
 beziehungsweise
beziehungsweise  .
.
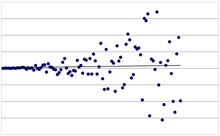
Heteroskedastizität dagegen bedeutet, dass Varianz der Störterme bedingt auf die erklärenden Variablen nicht konstant ist:
 .
.
In diesem Fall weisen die Störterme nicht die gleiche Varianz auf und folglich führt die gewöhnliche Methode der kleinsten Quadrate nicht zu effizienten Schätzwerten für die Regressionskoeffizienten. Dies bedeutet, dass diese Schätzwerte nicht die kleinstmögliche Varianz aufweisen. Die Standardfehler der Regressionskoeffizienten werden verzerrt geschätzt und außerdem ist dann eine naive Anwendung des t-Tests nicht möglich; die t-Werte sind nicht mehr brauchbar. Abhilfe schafft in vielen Fällen eine geeignete Datentransformation: Herrscht Heteroskedastizität, kann es durchaus sinnvoll sein, die Daten mittels Anwendung des Logarithmus oder der Quadratwurzel zu transformieren, um Homoskedastizität zu erreichen. Diese führt dann zur korrekten Verwendung des Satzes von Gauß-Markow.
Praktisch tritt Heteroskedastizität auf, wenn die Streuung der abhängigen Variablen von der Höhe der erklärenden Variablen abhängt. Zum Beispiel ist mit einer größeren Streuung der Ausgaben im Urlaub zu rechnen, wenn das verfügbare Monatseinkommen höher ist.
Folgen von Heteroskedastizität bei linearer Regression
- die erste KQ-Annahme bleibt erfüllt, also korreliert die exogene erklärende Variable trotzdem nicht mit dem Residuum
- die exogene und die endogene Variable sind nicht mehr identisch verteilt, was zur Folge hat, dass die KQ-Schätzer nicht mehr effizient sind und die Standardfehler der Regressionskoeffizienten verzerrt und nicht konsistent wird. Daraus folgt, dass – wie oben erwähnt – natürlich auch die t-Werte nicht mehr verlässlich sind. Dies, weil der t-Wert ja berechnet wird, indem die Koeffizientenschätzung einer exogenen (Prädiktor-)Variablen durch deren Standardfehler dividiert wird. Bei Vorliegen von Heteroskedastizität kann jedoch auf andere Standardfehler zurückgegriffen werden, z. B. auf heteroskedastie-robuste Standardfehler (Eicker-Huber-White-Schätzer (benannt nach Friedhelm Eicker, Peter J. Huber, Halbert L. White); manchmal auch nur schlicht mit einem der Entwicklernamen benannt, etwa als White-Schätzer). Eine weitere Möglichkeit bei Vorliegen von Heteroskedastie ist der Rückgriff auf den gewichteten Kleinste-Quadrate-Schätzer (englisch weighted least squares estimator, kurz WLSE) als Spezialfall des verallgemeinerten Kleinste-Quadrate-Schätzers (VKQ-Schätzer).
Beispiele
Heteroskedastizität in Zeitreihen
Ein typisches Beispiel für Heteroskedastizität ist, wenn bei einer Zeitreihe die Abweichungen von der Trendgeraden mit Fortlauf der Zeit steigen (z.B. für die Treffgenauigkeit bei der Wettervorhersage: je weiter in der Zukunft, desto unwahrscheinlicher ist eine genaue Prognose). Allerdings können auch in Zeitreihen ohne konstante Varianz bestimmte charakteristische Auffälligkeiten wie z.B. Volatilitätscluster beobachtet werden. Deshalb wurde im Rahmen von Volatilitätsmodellen versucht, dem Verlauf der Varianz eine systematische Erklärung zu Grunde zu legen.
Heteroskedastizität bei der linearen Regression
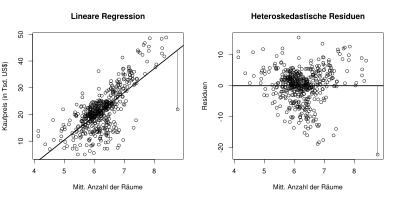
Heteroskedastizität kann bei einer einfachen linearen Regression auftreten. Dies ist ein Problem, da in der klassischen linearen Regressionsanalyse Homoskedastizität der Residuen vorausgesetzt wird. Die untenstehende Grafik zeigt die Variablen mittlere Raumzahl pro Haus (X) sowie mittlerer Kaufpreis pro Haus (Y) für (fast) jeden Distrikt in Boston. Die Grafik Lineare Regression zeigt den Zusammenhang zwischen den beiden Variablen. Die rote Linie zeigt das Residuum für die ganz rechte Beobachtung, also die Differenz zwischen dem beobachteten Wert (runder Kreis) und dem geschätzten Wert auf der Regressionsgerade.
In der Grafik Heteroskedastische Residuen sieht man die Residuen für alle Beobachtungen. Betrachtet man die Streuung der Residuen im Bereich von 4–5 Räumen oder im Bereich ab 7,5 Räumen, so ist sie größer als die Streuung in dem Bereich 5–7,5 Räume. Die Streuung der Residuen in den einzelnen Bereichen ist also unterschiedlich, also heteroskedastisch. Wäre die Streuung der Residuen in allen Bereichen gleich, dann wäre sie homoskedastisch.
Literatur
- M.-W. Stoetzer: Regressionsanalyse in der empirischen Wirtschafts- und Sozialforschung. Band 1: Eine nichtmathematische Einführung mit SPSS und Stata. Berlin 2017, ISBN 978-3-662-53823-4.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 09.04. 2023