Trennschärfe eines Tests
Trennschärfe eines Tests beschreibt die Entscheidungsfähigkeit eines statistischen Tests. Andere Ausdrücke hierfür sind Güte, Macht, Power, Schärfe eines Tests, Teststärke oder Testschärfe. Das entsprechende Fachgebiet ist die Testtheorie, ein Teilgebiet der mathematischen Statistik. Im Kontext der Beurteilung eines binären Klassifikators wird die Trennschärfe eines Tests auch als Sensitivität (recall) bezeichnet. Die Trennschärfe eines Tests ist genauso wie das Niveau eines Tests ein Begriff, der aus der Gütefunktion (Trennschärfefunktion) abgeleitet ist.
Die Trennschärfe eines Tests gibt die Fähigkeit eines Tests an, Unterschiede (Effekte) zu erkennen, wenn sie in Wirklichkeit vorhanden sind. Genauer gesagt
gibt die Trennschärfe an, mit welcher Wahrscheinlichkeit ein
statistischer Test die abzulehnende Nullhypothese
 („Es gibt keinen Unterschied“) korrekt zurückweist, wenn die Alternativhypothese
(„Es gibt keinen Unterschied“) korrekt zurückweist, wenn die Alternativhypothese
 („Es gibt einen Unterschied“) wahr ist. Unter der Annahme, dass die Nullhypothese die Abwesenheit einer bestimmten Krankheit („nicht krank“),
die Alternativhypothese das Vorhandensein der Krankheit („krank“) und die Ablehnung der Nullhypothese einen positiven diagnostischen
Test darstellt, ist die Trennschärfe des Tests äquivalent[1] zur
Sensitivität des Tests
(der Wahrscheinlichkeit, dass ein Kranker ein positives Testergebnis aufweist). Zugleich stellt diese Tatsache einen Brückenschlag zwischen der Testtheorie
und der Theorie diagnostischen Testens dar.
(„Es gibt einen Unterschied“) wahr ist. Unter der Annahme, dass die Nullhypothese die Abwesenheit einer bestimmten Krankheit („nicht krank“),
die Alternativhypothese das Vorhandensein der Krankheit („krank“) und die Ablehnung der Nullhypothese einen positiven diagnostischen
Test darstellt, ist die Trennschärfe des Tests äquivalent[1] zur
Sensitivität des Tests
(der Wahrscheinlichkeit, dass ein Kranker ein positives Testergebnis aufweist). Zugleich stellt diese Tatsache einen Brückenschlag zwischen der Testtheorie
und der Theorie diagnostischen Testens dar.
Die Trennschärfe des Tests kann also als „Ablehnungskraft“ des Tests interpretiert werden. Hohe Trennschärfe des Tests spricht gegen niedrige Trennschärfe
für die Nullhypothese
.
Es wird versucht, den Ablehnbereich
 so zu bestimmen, dass die Wahrscheinlichkeit für die Ablehnung einer „falschen Nullhypothese“
,
d.h. für Beibehaltung der Alternativhypothese
unter der Bedingung, dass
wahr ist, möglichst groß ist:
so zu bestimmen, dass die Wahrscheinlichkeit für die Ablehnung einer „falschen Nullhypothese“
,
d.h. für Beibehaltung der Alternativhypothese
unter der Bedingung, dass
wahr ist, möglichst groß ist:
 .
Um die Trennschärfe eines Tests berechnen zu können, muss die Alternativhypothese in Form einer konkreten Punkthypothese
spezifiziert sein.
.
Um die Trennschärfe eines Tests berechnen zu können, muss die Alternativhypothese in Form einer konkreten Punkthypothese
spezifiziert sein.
Sie bildet das Komplement zur Typ-II-Fehlerwahrscheinlichkeit
 ,
d.h. der Wahrscheinlichkeit, bei Gültigkeit von
fälschlich zugunsten der Nullhypothese
()
zu entscheiden. Die Trennschärfe selbst ist also die Wahrscheinlichkeit, einen ebensolchen Fehler zu vermeiden.
,
d.h. der Wahrscheinlichkeit, bei Gültigkeit von
fälschlich zugunsten der Nullhypothese
()
zu entscheiden. Die Trennschärfe selbst ist also die Wahrscheinlichkeit, einen ebensolchen Fehler zu vermeiden.
Beschreibung
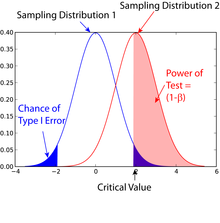
Für eine Fehlerwahrscheinlichkeit vom Typ II
beträgt die entsprechende Trennschärfe
 .
Wenn beispielsweise Experiment E eine Trennschärfe von
.
Wenn beispielsweise Experiment E eine Trennschärfe von
 und Experiment F eine Trennschärfe von
und Experiment F eine Trennschärfe von
 hat, besteht eine höhere Wahrscheinlichkeit, dass Experiment E einen Typ-II-Fehler aufweist als Experiment F, und Experiment F ist,
aufgrund seiner geringeren Wahrscheinlichkeit eines Fehlers vom Typ II, zuverlässiger als Experiment E. Äquivalent kann die Trennschärfe eines Tests als die
Wahrscheinlichkeit angesehen werden, dass ein
statistischer Test die abzulehnende Nullhypothese
(„Es gibt keinen Unterschied“) korrekt zurückweist, wenn die Alternativhypothese
(„Es gibt einen Unterschied“) wahr ist, d.h.
hat, besteht eine höhere Wahrscheinlichkeit, dass Experiment E einen Typ-II-Fehler aufweist als Experiment F, und Experiment F ist,
aufgrund seiner geringeren Wahrscheinlichkeit eines Fehlers vom Typ II, zuverlässiger als Experiment E. Äquivalent kann die Trennschärfe eines Tests als die
Wahrscheinlichkeit angesehen werden, dass ein
statistischer Test die abzulehnende Nullhypothese
(„Es gibt keinen Unterschied“) korrekt zurückweist, wenn die Alternativhypothese
(„Es gibt einen Unterschied“) wahr ist, d.h.
 .
.
Sie kann also als Fähigkeit eines Tests angesehen werden, einen bestimmten Effekt zu erkennen, wenn dieser bestimmte Effekt tatsächlich vorliegt. Wenn
keine Gleichheit ist, sondern lediglich die Negation von
(so hätte man zum Beispiel für
 mit einem nicht beobachtbaren Populationsparameter
mit einem nicht beobachtbaren Populationsparameter
 als Negation einfach
als Negation einfach
 ),
dann kann die Trennschärfe des Tests nicht berechnet werden, es sei denn die Wahrscheinlichkeiten für alle möglichen Werte des Parameters, die die Nullhypothese
verletzen sind bekannt. Man bezieht sich also allgemein auf die Trennschärfe eines Tests gegen eine spezifische Alternativhypothese (Punkthypothese).
),
dann kann die Trennschärfe des Tests nicht berechnet werden, es sei denn die Wahrscheinlichkeiten für alle möglichen Werte des Parameters, die die Nullhypothese
verletzen sind bekannt. Man bezieht sich also allgemein auf die Trennschärfe eines Tests gegen eine spezifische Alternativhypothese (Punkthypothese).
Mit zunehmender Trennschärfe nimmt die Wahrscheinlichkeit eines Fehlers vom Typ II ab, da die Trennschärfe gleich
ist. Ein ähnliches Konzept ist die Fehlerwahrscheinlichkeit vom Typ I.
Je kleiner bei vorgegebenem Fehler 1. Art
 die Wahrscheinlichkeit
ist, desto schärfer trennt der Test
und .
Ein Test heißt trennscharf, wenn er im Vergleich zu anderen möglichen Tests bei vorgegebenem
eine relativ hohe Trennschärfe aufweist. Wenn
wahr ist, ist die maximale Trennschärfe eines Tests gleich
.
die Wahrscheinlichkeit
ist, desto schärfer trennt der Test
und .
Ein Test heißt trennscharf, wenn er im Vergleich zu anderen möglichen Tests bei vorgegebenem
eine relativ hohe Trennschärfe aufweist. Wenn
wahr ist, ist die maximale Trennschärfe eines Tests gleich
.
| Wirklichkeit | |||
|---|---|---|---|
| H0 ist wahr | H1 ist wahr | ||
| Entscheidung des Tests … |
… für H0 | Richtige Entscheidung (Spezifität) Wahrscheinlichkeit: 1 - α |
Fehler 2. Art Wahrscheinlichkeit: β |
| … für H1 | Fehler 1. Art Wahrscheinlichkeit: α |
richtige Entscheidung Wahrscheinlichkeit: 1-β (Trennschärfe des Tests) | |
Trennschärfe-Analysen
Trennschärfe-Analysen bzw. Power-Analysen können verwendet werden, um die erforderliche minimale Stichprobengröße zu berechnen, bei der mit
hinreichender Wahrscheinlichkeit (Trennschärfe
)
ein Effekt einer bestimmten Größe (Effektstärke) erkannt werden kann.
Beispiel: „Wie oft muss ich eine Münze werfen, um zu dem Schluss zu kommen, dass sie um ein gewisses Ausmaß manipuliert ist?“. Im Kontext der
Beurteilung eines binären Klassifikators wird die
Trennschärfe eines Tests auch als Sensitivität bezeichnet.
Trennschärfe-Analysen sind in vielen Software-Bibliotheken implementiert, beispielsweise im Python-Paket statsmodels, in der Software G*power und in der statistischen Umgebung R.
Faustregel Stichprobengröße
Die grobe Faustregel von Lehr besagt, dass die Stichprobengröße
 für einen zweiseitigen Zweistichproben-t-Test mit
Trennschärfe 80 % (
für einen zweiseitigen Zweistichproben-t-Test mit
Trennschärfe 80 % ( ) und Signifikanzniveau
) und Signifikanzniveau
 folgendes gilt:
folgendes gilt:

wobei  die (geschätzte) Populationsvarianz ist und
die (geschätzte) Populationsvarianz ist und
 die zu detektierenden Unterschiede der Mittelwerte beider Stichproben.
Um die Trennschärfe auf 90 % zu erhöhen muss statt mit 16 mit 21 multipliziert werden.
Für einen Einstichproben-t-Test wird 16 mit 8 ersetzt.
die zu detektierenden Unterschiede der Mittelwerte beider Stichproben.
Um die Trennschärfe auf 90 % zu erhöhen muss statt mit 16 mit 21 multipliziert werden.
Für einen Einstichproben-t-Test wird 16 mit 8 ersetzt.
Eine intuitive Erklärung ist laut Lehr, dass bei einer Standardnormalverteilung
circa 80 % der Fläche unter der Wahrscheinlichkeitsdichte rechts von
 liegt. Daher sollte bei
liegt. Daher sollte bei
 am kritischen Wert
am kritischen Wert
 folgendes gelten:
folgendes gelten:

wobei  der mit
der mit  multiplizierte Standardfehler des Mittelwertes ist (wobei der Faktor
auftritt, da die Standardabweichung der Schätzung der Differenz zweier Mittelwerte betrachtet wird). Auflösen nach
liefert
multiplizierte Standardfehler des Mittelwertes ist (wobei der Faktor
auftritt, da die Standardabweichung der Schätzung der Differenz zweier Mittelwerte betrachtet wird). Auflösen nach
liefert

Der Wert der Faustregel liegt in der einfachen Form (welche auch nach
 umgestellt werden kann) und der leichten Merkbarkeit. Bei genauen Aussagen, sollte man eine Trennschärfen-Analyse mit einer Software-Bibliothek durchführen.
umgestellt werden kann) und der leichten Merkbarkeit. Bei genauen Aussagen, sollte man eine Trennschärfen-Analyse mit einer Software-Bibliothek durchführen.
Wahl des β-Fehler-Niveaus
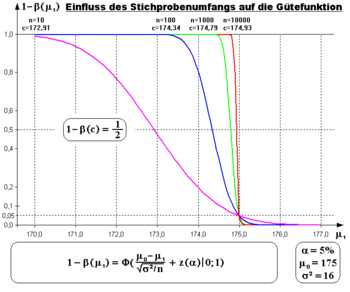
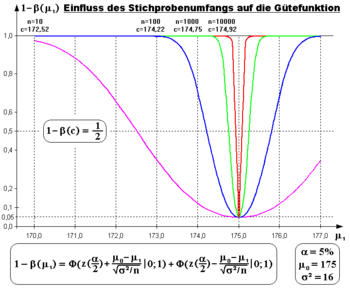
Für Wirksamkeitsstudien medizinischer Behandlungen schlägt Cohen (1969: 56) für
einen 4-mal so hohen Wert wie für das Signifikanzniveau
vor.
Wenn  ist, sollte das -Fehler-Niveau also 20 % betragen. Liegt in einer Untersuchung die
-Fehler-Wahrscheinlichkeit (Wahrscheinlichkeit für einen Fehler 2. Art) unter dieser 20 %-Grenze, so ist die Trennschärfe
() damit größer als 80 %.
ist, sollte das -Fehler-Niveau also 20 % betragen. Liegt in einer Untersuchung die
-Fehler-Wahrscheinlichkeit (Wahrscheinlichkeit für einen Fehler 2. Art) unter dieser 20 %-Grenze, so ist die Trennschärfe
() damit größer als 80 %.
Es sollte dabei bedacht werden, dass
-Fehler
bei vorgegebenem, festem Signifikanzniveau
im Allgemeinen nicht direkt kontrolliert werden können. So ist der
-Fehler
bei vielen asymptotischen oder nichtparametrischen
Tests schlechthin unberechenbar oder es existieren nur Simulationsstudien. Bei einigen Tests dagegen, zum Beispiel dem t-Test, kann der
-Fehler
kontrolliert werden, wenn der statistischen Auswertung eine Stichprobenumfangsplanung vorausgeht.
Ein (aus den Parametern des t-Tests induzierter)
Äquivalenztest kann verwendet
werden, um den (t-Test)
-Fehler
unabhängig von der Fallzahlplanung zu kontrollieren. In diesem Fall ist das (t-Test) Signifikanzniveau
variabel.
Bestimmungsfaktoren der Trennschärfe
Es gibt verschiedene Möglichkeiten zur Erhöhung der Trennschärfe eines Tests. Die Trennschärfe
() wird größer:
- mit wachsender Differenz von
 (das bedeutet: ein großer Unterschied zwischen zwei Teilpopulationen wird seltener übersehen als ein kleiner Unterschied)
(das bedeutet: ein großer Unterschied zwischen zwei Teilpopulationen wird seltener übersehen als ein kleiner Unterschied) - mit kleiner werdender Merkmalsstreuung

- mit größer werdendem Signifikanzniveau
(sofern
nicht festgelegt ist)
- mit wachsendem Stichprobenumfang, da der
Standardfehler dann kleiner wird:
 . Kleinere Effekte lassen sich durch einen größeren Stichprobenumfang trennen
. Kleinere Effekte lassen sich durch einen größeren Stichprobenumfang trennen - bei einseitigen Tests im Vergleich zu
zweiseitigen Tests: Für den zweiseitigen Test braucht man einen etwa um
 größeren Stichprobenumfang, um dieselbe Trennschärfe wie für den einseitigen Test zu erreichen.
größeren Stichprobenumfang, um dieselbe Trennschärfe wie für den einseitigen Test zu erreichen. - durch die Verwendung des besten bzw. trennschärfsten (englisch most powerful) Tests
- durch die Reduktion von Streuung in den Daten, z.B. durch den Einsatz von Filtern oder die Wahl von homogenen Untergruppen (Stratifizierung)
- durch die Erhöhung der Empfindlichkeit des Messverfahrens (Verstärken der Effekte, z.B. durch höhere Dosierung)
Wichtig für die Trennschärfe bzw. Power ist auch die Art des statistischen Tests: Parametrische Tests wie zum Beispiel der t-Test haben, falls die Verteilungsannahme stimmt, bei gleichem Stichprobenumfang stets eine höhere Trennschärfe als nichtparametrische Tests wie zum Beispiel der Wilcoxon-Vorzeichen-Rang-Test. Weichen die angenommene und die wahre Verteilung jedoch voneinander ab, liegt also beispielsweise in Wahrheit eine Laplace-Verteilung zugrunde, während eine Normalverteilung angenommen wurde, können nichtparametrische Verfahren jedoch auch eine wesentlich größere Trennschärfe aufweisen als ihre parametrischen Gegenstücke.
Entgegengesetzte Notation
In manchen Quellen wird – was für Verwirrung sorgen kann – für den Fehler 2. Art und die Trennschärfe die genau entgegengesetzte Notation verwendet, also die
Wahrscheinlichkeit, einen Fehler 2. Art zu begehen, mit dem Wert
.
Literatur
- Jacob Cohen: Statistical Power Analysis for the Behavioral Sciences. Erlbaum, Hillsdale, NJ 1969, ISBN 0-8058-0283-5.
Anmerkungen
- ↑ Dies gilt, da
 .
Für die Bedeutung der Notation, siehe Wahrheitsmatrix: Richtige und falsche Klassifikationen.
.
Für die Bedeutung der Notation, siehe Wahrheitsmatrix: Richtige und falsche Klassifikationen.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 26.01. 2026