Äquivalenztest
Äquivalenztests sind eine Variation von Hypothesentests, mit denen statistische Schlussfolgerungen aus beobachteten Daten gezogen werden können.
In Äquivalenztests wird die Nullhypothese definiert als ein Effekt, der groß genug ist, um als interessant angesehen zu werden, spezifiziert durch eine Äquivalenzgrenze. Die alternative Hypothese ist jeder Effekt, der weniger extrem ist als die gebundene Äquivalenz. Die beobachteten Daten werden statistisch mit den Äquivalenzgrenzen verglichen.
Wenn der statistische Test zeigt, dass die beobachteten Daten überraschend sind, unter der Annahme, dass wahre Effekte mindestens so extrem wie die Äquivalenzgrenzen sind, kann ein Neyman-Pearson-Ansatz für statistische Schlussfolgerungen verwendet werden, um Effektgrößen, die größer als die Äquivalenzgrenzen sind, mit einer im Voraus festgelegten Typ-1-Fehlerrate abzulehnen.
Äquivalenztests können zusätzlich zu Signifikanztests mit Nullhypothese durchgeführt werden. Dies könnte häufige Fehlinterpretationen von p-Werten, die größer als der Alpha-Wert sind, verhindern, um das Fehlen eines wahren Effekts zu unterstützen. Darüber hinaus können Äquivalenztests statistisch signifikante, aber praktisch unbedeutende Effekte identifizieren, wenn die Effekte statistisch von Null verschieden sind, aber auch statistisch kleiner als jede als sinnvoll erachtete Effektgröße (siehe erste Abbildung).
Motivation
Äquivalenztests stammen aus dem Bereich der Pharmakodynamik bzw. der Medikamentenentwicklung. Eine Anwendung besteht darin, zu zeigen, dass ein neues Medikament, das billiger ist als verfügbare Alternativen, genauso gut funktioniert wie ein bestehendes Medikament. Im Wesentlichen bestehen Äquivalenztests darin, ein Konfidenzintervall um eine beobachtete Effektgröße herum zu berechnen und Effekte abzulehnen, die extremer sind als die Äquivalenzgrenze, wenn sich das Konfidenzintervall nicht mit der Äquivalenzgrenze überschneidet. Bei zweiseitigen Tests wird eine obere und untere Äquivalenzgrenze angegeben. In Nicht-Unterlegenheitsstudien, in denen das Ziel darin besteht, die Hypothese zu testen, dass eine neue Behandlung nicht schlechter ist als bestehende Behandlungen, ist nur eine niedrigere Äquivalenzgrenze im Voraus festgelegt.
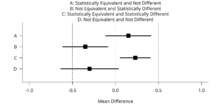
TOST-Verfahren
Ein sehr einfacher Äquivalenztestansatz ist das Verfahren der „zwei einseitigen t-Tests“ (englisch two one sided tests, kurz: TOST). Im TOST-Verfahren wird eine obere (ΔU) und eine untere (–ΔL) Äquivalenzgrenze basierend auf der kleinsten Effektgröße von Interesse (z.B. eine positive oder negative Differenz von d = 0,3) angegeben. Zwei zusammengesetzte Nullhypothesen werden getestet: H01: Δ ≤ -ΔL und H02: Δ ≥ ΔU. Wenn beide einseitigen Tests statistisch abgelehnt werden können, können wir zu dem Schluss kommen, dass -ΔL < Δ < ΔU, oder dass der beobachtete Effekt innerhalb der Äquivalenzgrenzen liegt und statistisch kleiner ist als jeder als sinnvoll erachtete und praktisch gleichwertige Effekt. Alternativen zum TOST-Verfahren wurden ebenfalls entwickelt. Eine erfolgte Modifikation von TOST macht den Ansatz bei wiederholten Messungen und der Bewertung mehrerer Variablen möglich.
Bootstrap-Test
Bootstrap-Tests können die Nullhypothese
 testen und sind somit für Äquivalenztests geeignet.
testen und sind somit für Äquivalenztests geeignet.
Vergleich zwischen t-Test und Äquivalenztest
Der Äquivalenztest kann zu Vergleichszwecken aus dem t-Test „induziert“ werden. Bei einem t-Test zum Signifikanzniveau αt-Test und welcher für eine Effektgröße dr eine Power von 1-βt-Test erreicht, führen beide Tests zu der gleichen Schlussfolgerung, wenn die Parameter Δ=dr sowie αequiv.-test=βt-test und βequiv.-test=αt-test zusammenfallen, d.h. die Fehler (Typ I und Typ II) zwischen dem t-Test und dem Äquivalenztest sind vertauscht. Um dies für den t-Test zu gewährleisten, muss entweder die Fallzahlplanung korrekt durchgeführt werden oder durch Anpassung des Signifikanzniveaus αt-test ein korrigierter Test bestimmt werden. Beide Ansätze haben praktische Probleme, da die Fallzahlplanung auf nicht überprüfbaren Annahmen hinsichtlich der Standardabweichung beruht und beim Anpassen von αt-test (sogenannter revised t-Test) numerische Probleme auftreten. Diese Einschränkungen treten bei Anwendung des Äquivalenztests nicht auf.
Die zweite Abbildung ermöglicht einen Vergleich des Äquivalenztests und des t-Tests, wenn die Fallzahlplanung von Differenzen zwischen der A-priori-Standardabweichung
 und der Standardabweichung aus der Stichprobe
und der Standardabweichung aus der Stichprobe
 betroffen ist. Die Verwendung eines Äquivalenztests anstelle eines t-Tests stellt sicher, dass αequiv.-test (bzw. βt-test) beschränkt ist, was der t-Test
nicht tut. Insbesondere im Fall
betroffen ist. Die Verwendung eines Äquivalenztests anstelle eines t-Tests stellt sicher, dass αequiv.-test (bzw. βt-test) beschränkt ist, was der t-Test
nicht tut. Insbesondere im Fall
 kann im t-Test der Typ II Fehler beliebig groß werden. Demgegenüber führt
kann im t-Test der Typ II Fehler beliebig groß werden. Demgegenüber führt
 dazu, dass der t-Test strenger ausfällt als der für dr geplante, was zu zufälligen Nachteilen
(z.B. eines Geräteherstellers) führen kann. Dies macht den Äquivalenztest sicherer in der Anwendung.
dazu, dass der t-Test strenger ausfällt als der für dr geplante, was zu zufälligen Nachteilen
(z.B. eines Geräteherstellers) führen kann. Dies macht den Äquivalenztest sicherer in der Anwendung.

Weiterführende Literatur
- Esteban Walker, Amy S. Nowacki: Understanding Equivalence and Noninferiority Testing. In:
Journal of General Internal Medicine. 26. Jahrgang, Februar 2011,
S. 192–6,
 PMC 3019319 (freier Volltext).
PMC 3019319 (freier Volltext).


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 01.03. 2026