Fehler 1. und 2. Art
Die Fehler 1. und 2. Art, auch α-Fehler (Alpha-Fehler) und β-Fehler (Beta-Fehler) genannt, bezeichnen eine statistische Fehlentscheidung. Sie beziehen sich auf eine Methode der mathematischen Statistik, den sogenannten Hypothesentest. Beim Test einer Hypothese liegt ein Fehler 1. Art vor, wenn die Nullhypothese zurückgewiesen wird, obwohl sie in Wirklichkeit wahr ist (beruhend auf falsch positiven Ergebnissen). Dagegen bedeutet ein Fehler 2. Art, dass der Test die Nullhypothese fälschlicherweise bestätigt, obwohl die Alternativhypothese korrekt ist.
Entscheidungstabelle
| H0 ist richtig | H1 ist richtig | |
|---|---|---|
| Durch einen statistischen Test fällt eine Entscheidung für H0 | Richtige Entscheidung (Spezifität) Wahrscheinlichkeit: 1 - α |
Fehler 2. Art Wahrscheinlichkeit: β |
| Durch einen statistischen Test fällt eine Entscheidung für H1 | Fehler 1. Art Wahrscheinlichkeit: α |
richtige Entscheidung Wahrscheinlichkeit: 1-β (Power, Sensitivität) |
Hinweis: Sowohl Beta (wie auch Alpha) repräsentieren bedingte Wahrscheinlichkeiten:
 und
und ,
,
wobei A den Ablehnbereich und T die für den Test benutzte Teststatistik bezeichnet.
Fehler 1. Art
Beim Test einer Hypothese liegt ein Fehler 1. Art vor, wenn die Nullhypothese zurückgewiesen wird, obwohl sie in Wirklichkeit wahr ist (beruhend auf falsch positive Ergebnissen).
Die Ausgangshypothese  (Nullhypothese) ist hierbei die Annahme, die Testsituation befinde sich im
„Normalzustand“. Wird also dieser „Normalzustand“ nicht erkannt, obwohl er
tatsächlich vorliegt, ergibt sich ein Fehler 1. Art. Beispiele für einen
Fehler 1. Art sind:
(Nullhypothese) ist hierbei die Annahme, die Testsituation befinde sich im
„Normalzustand“. Wird also dieser „Normalzustand“ nicht erkannt, obwohl er
tatsächlich vorliegt, ergibt sich ein Fehler 1. Art. Beispiele für einen
Fehler 1. Art sind:
- der Patient wird als krank angesehen, obwohl er in Wirklichkeit gesund ist (Nullhypothese: der Patient ist gesund),
- der Angeklagte wird als schuldig verurteilt, obwohl er in Wirklichkeit unschuldig ist (Nullhypothese: der Angeklagte ist unschuldig),
- der Person wird kein Zugang gewährt, obwohl sie eine Zugangsberechtigung hat (Nullhypothese: die Person hat Zugangsberechtigung)
Die vor einem Test bzw. einer Untersuchung festgelegte maximale Wahrscheinlichkeit, bei einer auf dem Ergebnis des Tests fußenden Entscheidung einen solchen Fehler 1. Art zu begehen (Risiko 1. Art), nennt man auch Signifikanzniveau oder Irrtumswahrscheinlichkeit. In der Regel wählt man ein Signifikanzniveau von 5 % (signifikant) oder 1 % (sehr signifikant).
Die andere mögliche Fehlentscheidung, nämlich die Alternativhypothese
 zurückzuweisen, obwohl sie wahr ist, heißt Fehler 2. Art.
zurückzuweisen, obwohl sie wahr ist, heißt Fehler 2. Art.
Beispiele
- Ein Tester hat eine Urne
vor sich, in die er nicht hineinschauen kann. Darin befinden sich rote und
grüne Kugeln. Es kann jeweils nur eine Kugel zu Testzwecken aus der Urne
entnommen werden.
Alternativhypothese: „In der Urne befinden sich mehr rote als grüne Kugeln“.
Um ein Urteil über den Inhalt der Urne abgeben zu können, wird der Tester der Urne mehrmals Kugeln zu Testzwecken entnehmen. Wenn er daraufhin zu der Entscheidung gelangt, dass die Alternativhypothese zutreffend sein kann, also er die Meinung vertritt, dass mehr rote als grüne Kugeln in der Urne seien, obwohl in Wirklichkeit die Nullhypothese zutrifft, nämlich dass gleich viele rote wie grüne oder weniger rote als grüne Kugeln in der Urne sind, dann begeht er einen Fehler 1. Art. - Wir wollen überprüfen, ob eine neue Lernmethode die Lernleistung von
Schülern steigert. Dafür vergleichen wir eine Gruppe von Schülern, die nach
der neuen Lernmethode unterrichtet wurden, mit einer Stichprobe von Schülern,
die nach der alten Methode unterrichtet wurden.
Alternativhypothese: „Schüler, die nach der neuen Lernmethode unterrichtet wurden, haben eine höhere Lernleistung als Schüler, die nach der alten Methode unterrichtet wurden.“
Angenommen in unserer Untersuchung weist die Stichprobe von Schülern, die nach der neuen Lernmethode unterrichtet wurden, tatsächlich eine bessere Lernleistung auf. Vielleicht beruht dieser Unterschied aber auch nur auf Zufall oder anderen Einflüssen. Wenn also in Wahrheit zwischen den beiden Populationen überhaupt kein Unterschied besteht und wir fälschlicherweise die Nullhypothese verwerfen – es also als gesichert ansehen, dass die neue Methode das Lernen verbessert – dann begehen wir einen Fehler 1. Art. Dieser kann natürlich fatale Folgen haben, wenn wir z.B. mit hohen Kosten und viel Aufwand den gesamten Unterricht auf die neue Lernmethode umstellen, obwohl diese in Wahrheit überhaupt keine besseren Ergebnisse bewirkt. - Spam-Filter für ankommende E-Mails:
Ein Filter soll erkennen, ob eine E-Mail Spam ist oder
nicht.
Nullhypothese: Es ist eine normale E-Mail und kein Spam.
Alternativhypothese: Es ist Spam.
Falls eine E-Mail als Spam klassifiziert wird, sie jedoch in Wirklichkeit kein Spam ist, die E-Mail also falsch als Spam klassifiziert wird, so sprechen wir von einem Fehler 1. Art (falsch-positiv).
Fehler 2. Art
Im Gegensatz zum Fehler 1. Art bedeutet ein Fehler 2. Art, dass der Test die Nullhypothese fälschlicherweise bestätigt, obwohl die Alternativhypothese korrekt ist.
Schwierigkeiten bei der Bestimmung des Fehlers 2. Art
 )
abhängt,
jedoch bei Annahme der Alternativhypothese i.d.R. unbekannt ist, kann auch die
Wahrscheinlichkeit eines Fehlers 2. Art im Gegensatz zu der eines Fehlers 1. Art
(blau) nicht vorab bestimmt werden.
)
abhängt,
jedoch bei Annahme der Alternativhypothese i.d.R. unbekannt ist, kann auch die
Wahrscheinlichkeit eines Fehlers 2. Art im Gegensatz zu der eines Fehlers 1. Art
(blau) nicht vorab bestimmt werden.Im Gegensatz zum Risiko
1. Art, die gegebene Null-Hypothese, obwohl sie in Wirklichkeit zutrifft,
irrtümlicherweise abzulehnen, lässt sich das Risiko 2. Art, also die
Wahrscheinlichkeit eines Fehlers 2. Art meist nicht vorab bestimmen. Grund
dessen ist die Art und Weise der Festlegung von Hypothesen statistischer Tests:
Während die Null-Hypothese stets eine dezidierte Aussage wie beispielsweise
:
„Mittelwert“  darstellt, ist die Alternativhypothese, da sie im Grunde alle übrigen
Möglichkeiten erfasst, damit i.d.R. auch nur recht unbestimmter bzw. globaler
Natur (bspw. :
„Mittelwert
darstellt, ist die Alternativhypothese, da sie im Grunde alle übrigen
Möglichkeiten erfasst, damit i.d.R. auch nur recht unbestimmter bzw. globaler
Natur (bspw. :
„Mittelwert  “).
“).
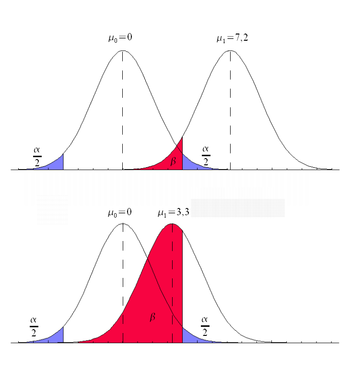
Die rechtsstehende Grafik illustriert diese Abhängigkeit der
Wahrscheinlichkeit eines Fehlers 2. Art  ;
(rot) vom unbekannten Mittelwert ,
wenn als „Signifikanzniveau“, d.h. maximales Risiko 1. Art,
;
(rot) vom unbekannten Mittelwert ,
wenn als „Signifikanzniveau“, d.h. maximales Risiko 1. Art,  ;
(blau) in beiden Fällen derselbe Wert gewählt wird. Wie zu sehen, ergibt sich
dabei überdies die paradoxe Situation, dass die Wahrscheinlichkeit eines Fehlers
2. Art umso größer wird, je näher der wahre Wert
an dem von der Nullhypothese behaupteten Wert
;
(blau) in beiden Fällen derselbe Wert gewählt wird. Wie zu sehen, ergibt sich
dabei überdies die paradoxe Situation, dass die Wahrscheinlichkeit eines Fehlers
2. Art umso größer wird, je näher der wahre Wert
an dem von der Nullhypothese behaupteten Wert  liegt, bis hin dazu, dass für
liegt, bis hin dazu, dass für  das Risiko 2. Art ;
den Grenzwert
das Risiko 2. Art ;
den Grenzwert  ;
annimmt. Anders gesagt: Je kleiner die Abweichung des tatsächlichen vom
behaupteten Wert
;
annimmt. Anders gesagt: Je kleiner die Abweichung des tatsächlichen vom
behaupteten Wert  ,
desto größer paradoxerweise die Wahrscheinlichkeit, einen Fehler zu
machen, wenn man aufgrund des Testergebnisses weiterhin dem behaupteten
Wert
Glauben schenkt (obwohl die Abweichung beider Werte voneinander möglicherweise
aufgrund ihrer Geringfügigkeit praktisch gar keine Rolle mehr spielt).
Wie dieser Widerspruch zeigt, kann ein rein formal-logischer Umgang mit der
Problematik des Fehlers 2. Art leicht Grundlage von Fehlentscheidungen sein. Bei
biometrischen und medizinstatistischen Anwendungen heißt die Wahrscheinlichkeit,
eine Entscheidung für H0 zu treffen, falls H0 richtig ist,
Spezifität. Die Wahrscheinlichkeit, eine Entscheidung für H1
zu treffen, falls H1 richtig ist, wird Sensitivität genannt.
Wünschenswert ist, dass ein Testverfahren hohe Sensitivität und hohe Spezifität
und damit kleine Wahrscheinlichkeiten für die Fehler erster und zweiter Art
hat.
,
desto größer paradoxerweise die Wahrscheinlichkeit, einen Fehler zu
machen, wenn man aufgrund des Testergebnisses weiterhin dem behaupteten
Wert
Glauben schenkt (obwohl die Abweichung beider Werte voneinander möglicherweise
aufgrund ihrer Geringfügigkeit praktisch gar keine Rolle mehr spielt).
Wie dieser Widerspruch zeigt, kann ein rein formal-logischer Umgang mit der
Problematik des Fehlers 2. Art leicht Grundlage von Fehlentscheidungen sein. Bei
biometrischen und medizinstatistischen Anwendungen heißt die Wahrscheinlichkeit,
eine Entscheidung für H0 zu treffen, falls H0 richtig ist,
Spezifität. Die Wahrscheinlichkeit, eine Entscheidung für H1
zu treffen, falls H1 richtig ist, wird Sensitivität genannt.
Wünschenswert ist, dass ein Testverfahren hohe Sensitivität und hohe Spezifität
und damit kleine Wahrscheinlichkeiten für die Fehler erster und zweiter Art
hat.
Beispiele
- Im Six-Sigma-Projektmanagement: Fehler 1. Art: Man stellt am Projektende fest, dass bei der initialen Planung Aspekte ausgelassen wurden („zu wenig gemacht“). Ein Fehler 2. Art wäre hier, dass das gesamte Projekt über Dinge gemacht wurden, die sich am Ende als überflüssig bzw. irrelevant für den Projekterfolg herausstellen („zu viel gemacht“).
- Ein Tester hat eine Urne vor sich, in die er nicht hineinschauen kann. Darin befinden sich rote und grüne Kugeln. Es kann jeweils nur eine Kugel zu Testzwecken aus der Urne entnommen werden.
- Alternativhypothese: „In der Urne befinden sich mehr rote als grüne Kugeln“.
- Um ein Urteil über den Inhalt der Urne abgeben zu können, wird der Tester der Urne mehrmals Kugeln zu Testzwecken entnehmen. Die Nullhypothese in unserem Beispiel lautet, dass entweder genauso viele rote wie grüne, oder aber mehr grüne als rote Kugeln in der Urne sind (das Gegenteil der Alternativhypothese). Wenn der Tester aufgrund seiner Stichprobe also zu dem Schluss kommt, die Nullhypothese sei richtig bzw. die Alternativhypothese falsch, obwohl in Wahrheit doch die Alternativhypothese richtig ist, dann beginge er einen Fehler 2. Art.
- Wir möchten den Einfluss der Ernährung auf die geistige Entwicklung von Kindern in Kinderheimen untersuchen. Dafür vergleichen wir zwei Gruppen von Kindern hinsichtlich ihrer Leistung in kognitiven Tests: Die eine Stichprobe wird nach dem herkömmlichen Plan ernährt, die andere erhält eine besonders gesunde Kost. Wir vermuten, dass die gesunde Kost sich positiv auf die kognitiven Leistungen auswirkt.
- Alternativhypothese: „Kinder, die eine besonders gesunde Kost erhalten, weisen bessere kognitive Leistung auf als Kinder, die auf die herkömmliche Weise ernährt werden.“
- Wenn wir nun die kognitive Leistung unserer beiden Stichproben vergleichen, so stellen wir keinen Unterschied in der kognitiven Leistung fest. Demzufolge halten wir die Alternativhypothese für falsch und bestätigen die Nullhypothese. Wenn jedoch in Wahrheit die Population der gesund Ernährten doch eine bessere Leistung aufweist, dann begehen wir einen Fehler 2. Art.
- Aber wir haben in unserer Stichprobe doch keinen Unterschied festgestellt? Diese Gleichheit kann aber auch auf die zufällige Streuung der Messergebnisse oder auf die ungünstige Zusammenstellung unserer Stichproben zurückzuführen sein.
- Das Begehen eines Fehlers 2. Art ist in der Regel weniger „schlimm“, als ein Fehler 1. Art. Dies hängt jedoch individuell vom Untersuchungsgegenstand ab. In unserem Beispiel hat der Fehler 2. Art ausgesprochen nachteilige Konsequenzen: Obwohl die gesunde Ernährung die Leistung verbessert, entscheiden wir uns, die herkömmliche Ernährung beizubehalten. Ein Fehler 1. Art, also die Einführung der gesunden Ernährung für alle Kinder, obwohl diese keine Leistungsverbesserung bringt, hätte hier weniger nachteilige Konsequenzen gehabt.
Entgegengesetzte Notation
In manchen Quellen wird, was für Verwirrung sorgen kann, für den Fehler 2. Art und die Teststärke die genau entgegengesetzte Notation verwendet, also die Wahrscheinlichkeit, einen Fehler 2. Art zu begehen, mit dem Wert 1-β bezeichnet, die Teststärke oder Power dagegen mit β.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 30.04. 2020