Wahrscheinlichkeitsmaß
Ein Wahrscheinlichkeitsmaß, kurz W-Maß oder synonym
Wahrscheinlichkeitsverteilung beziehungsweise kurz W-Verteilung
oder einfach Verteilung genannt, ist ein grundlegendes Konstrukt der
Stochastik und
Wahrscheinlichkeitstheorie.
Seltener findet sich auch die Bezeichnung Wahrscheinlichkeitsgesetz.
Wahrscheinlichkeitsmaße dienen dazu, Mengen eine Zahl zwischen null und eins
zuzuordnen. Diese Zahl ist dann die Wahrscheinlichkeit, dass das durch die Menge
beschriebene Ereignis
eintritt. Typisches Beispiel hierfür wäre das Werfen eines fairen Würfels: Der
Menge {2}, also dem Ereignis, dass die Augenzahl 2 geworfen wird, wird von der
Wahrscheinlichkeitsverteilung die Wahrscheinlichkeit  zugeordnet.
zugeordnet.
Im Rahmen der Maßtheorie entsprechen die Wahrscheinlichkeitsmaße speziellen endlichen Maßen, die sich durch ihre Normiertheit auszeichnen.
Insbesondere in der Physik werden manche Wahrscheinlichkeitsverteilungen auch als Statistiken bezeichnet. Beispiel hierfür sind die Boltzmann-Statistik und die Bose-Einstein-Statistik.
Definition
Gegeben sei
- eine Menge
 ,
der sogenannte Ergebnisraum,
,
der sogenannte Ergebnisraum, - eine σ-Algebra
 auf dieser Menge, das Ereignissystem.
auf dieser Menge, das Ereignissystem.
Dann heißt eine Abbildung
![{\displaystyle P\colon \Sigma \to [0,1]}](/svg/ee2dc5d58c30b739556a1ac64d47b5d839c8eb11.svg)
mit den Eigenschaften
- Normiertheit: Es ist

- σ-Additivität:
Für jede abzählbare Folge von paarweise
disjunkten Mengen
 aus
gilt
aus
gilt

ein Wahrscheinlichkeitsmaß oder eine Wahrscheinlichkeitsverteilung.
Die drei Forderungen Normiertheit, σ-Additivität und Werte im Intervall zwischen 0 und 1 werden auch die Kolmogorow-Axiome genannt.
Elementares Beispiel
Ein elementares Beispiel für ein Wahrscheinlichkeitsmaß ist durch den Wurf eines fairen Würfels gegeben. Der Ergebnisraum ist gegeben durch

und enthält alle möglichen Ausgänge des Würfelns. Das Ereignissystem enthält
alle Teilmengen des Ergebnisraumes, denen man eine Wahrscheinlichkeit zuordnen
will. In diesem Fall will man jeder Teilmenge des Ergebnisraumes eine
Wahrscheinlichkeit zuordnen, daher wählt man als Ereignissystem die Potenzmenge, also die Menge
aller Teilmengen von
 .
.
Das Wahrscheinlichkeitsmaß lässt sich nun definieren als
 ,
,
da man von einem fairen Würfel ausgeht. Jede Augenzahl ist demnach gleich wahrscheinlich. Interessiert man sich nun für die Frage, wie groß die Wahrscheinlichkeit ist, eine gerade Zahl zu würfeln, folgt aus der σ-Additivität

Wichtig ist hier, dass Wahrscheinlichkeitsmaße keine Zahlen, sondern nur
Mengen als Argumente nehmen. Daher sind Schreibweisen wie  streng genommen falsch und müssten korrekterweise
streng genommen falsch und müssten korrekterweise  lauten.
lauten.
Wahrscheinlichkeitsverteilungen und Verteilungen von Zufallsvariablen
In der Literatur wird nicht immer streng zwischen einer Wahrscheinlichkeitsverteilung – also einer Abbildung, die auf einem Mengensystem definiert ist und den Kolmogorow-Axiomen genügt – und der Verteilung einer Zufallsvariablen unterschieden.
Verteilungen von Zufallsvariablen entstehen, wenn man eine Zufallsvariable auf einem Wahrscheinlichkeitsraum definiert, um relevante Informationen zu extrahieren. Beispiel hierfür wäre eine Lottoziehung: Der Wahrscheinlichkeitsraum modelliert die Wahrscheinlichkeit, eine ganz bestimmte Zahlenkombination zu ziehen. Interessant ist aber nur die Information über die Anzahl der richtigen Zahlen. Diese wird von der Zufallsvariablen extrahiert. Die Verteilung dieser Zufallsvariablen ordnet nur dieser neuen Information aufgrund der ursprünglichen Wahrscheinlichkeiten im Wahrscheinlichkeitsraum eine neue Wahrscheinlichkeit zu.
Das Wahrscheinlichkeitsmaß wird durch die Zufallsvariable vom originären Wahrscheinlichkeitsraum in einen neuen „künstlichen“ Wahrscheinlichkeitsraum übertragen und induziert dort als Bildmaß unter der Zufallsvariablen ein neues Wahrscheinlichkeitsmaß. Im maßtheoretischen Sinne handelt es sich bei einer Zufallsvariablen um eine Abbildung

zwischen dem originären Wahrscheinlichkeitsraum und den reellen Zahlen,
versehen mit der Borelschen  -Algebra.
Da eine Zufallsvariable zudem per Definition die -
-Algebra.
Da eine Zufallsvariable zudem per Definition die - -Messbarkeit
erfüllt, also für jede messbare Menge
-Messbarkeit
erfüllt, also für jede messbare Menge  gilt
gilt

ergibt sich für alle
durch

auf natürliche Weise das Bildmaß von  unter
unter  oder kurz die Verteilung der Zufallsvariablen .
oder kurz die Verteilung der Zufallsvariablen .
Jede Verteilung einer Zufallsvariablen ist eine
Wahrscheinlichkeitsverteilung. Umgekehrt kann jede Wahrscheinlichkeitsverteilung
als Verteilung einer nicht näher präzisierten Zufallsvariablen angesehen
werden. Einfachstes Beispiel für solch eine Konstruktion ist, von einem
vorgegebenen Wahrscheinlichkeitsraum  eine identische
Abbildung
eine identische
Abbildung

zu definieren. Die Verteilung  der Zufallsvariablen
entspricht also in diesem Fall genau dem Wahrscheinlichkeitsmaß
der Zufallsvariablen
entspricht also in diesem Fall genau dem Wahrscheinlichkeitsmaß 
Da sich demnach abstrakte und komplizierte Wahrscheinlichkeitsmaße durch Zufallsexperimente als konkrete Verteilungen von Zufallsvariablen auffassen lassen, ergeben sich die üblichen Notationen
![{\displaystyle P(X\leq k)\equiv P(\{\omega \in \Omega \mid X(\omega )\leq k\})\equiv P_{X}((-\infty ,k])}](/svg/28427fd1b5e8ccb451d47ab12d6ba028c37b0ff3.svg)
für die Verteilungsfunktion von .
Diese entspricht also offensichtlich der Verteilung eingeschränkt auf das System
der Halbstrahlen – ein konkreter schnittstabiler Erzeuger der Borelschen -Algebra.
Über den Maßeindeutigkeitssatz
ergibt sich unmittelbar, dass durch die Verteilungsfunktion einer
Zufallsvariablen immer auch die Verteilung in eindeutiger Weise bestimmt
wird.
Eigenschaften als Maß
Die folgenden Eigenschaften folgen aus der Definition.
- Es ist
 .
Dies folgt aus der σ-Additivität und der Tatsache, dass die leere Menge
disjunkt zu sich selbst ist.
.
Dies folgt aus der σ-Additivität und der Tatsache, dass die leere Menge
disjunkt zu sich selbst ist. - Subtraktivität: Für
 mit
mit  gilt
gilt
-
 .
.
- Monotonie: Ein Wahrscheinlichkeitsmaß ist eine monotone Abbildung
von
 nach
nach ![{\displaystyle ([0,1],\leq )}](/svg/8341d3c2b6b62b870e1bd71b2d1de891cbc315a3.svg) ,
das heißt, für
gilt
,
das heißt, für
gilt
-
 .
.
- Endliche Additivität: Aus der σ-Additivität folgt direkt, dass für
paarweise disjunkte Mengen
 gilt:
gilt:

- σ-Subadditivität:
Für eine beliebige Folge
 von Mengen aus
gilt
von Mengen aus
gilt
-
 .
.
- σ-Stetigkeit
von unten: Ist
eine monoton
gegen
 wachsende Mengenfolge in ,
also
wachsende Mengenfolge in ,
also  ,
so ist
,
so ist  .
. - σ-Stetigkeit
von oben: Ist
eine monoton
gegen
fallende Mengenfolge in ,
also
 ,
so ist .
,
so ist . - Prinzip von Inklusion und Exklusion: Es gilt

- sowie
 .
.
- Im einfachsten Fall entspricht dies

Konstruktion von Wahrscheinlichkeitsmaßen
Verfahren bei Wahrscheinlichkeitsmaßen auf den ganzen oder reellen Zahlen
Wahrscheinlichkeitsfunktionen
Auf einer endlichen oder abzählbar
unendlichen Grundmenge  ,
versehen mit der Potenzmenge
als σ-Algebra, also
,
versehen mit der Potenzmenge
als σ-Algebra, also  lassen sich Wahrscheinlichkeitmaße durch Wahrscheinlichkeitsfunktionen
definieren. Dies sind Abbildungen
lassen sich Wahrscheinlichkeitmaße durch Wahrscheinlichkeitsfunktionen
definieren. Dies sind Abbildungen
![{\displaystyle f\colon M\to [0,1]{\text{, für die gilt: }}\sum _{i\in M}f(i)=1}](/svg/31e6b331bb28ef1e91245b025102106cd2f0608c.svg) .
.
Die zweite Forderung liefert die Normiertheit des Wahrscheinlichkeitsmaßes. Dieses wird dann definiert durch
 .
.
Beispielsweise wäre im Falle eines fairen Würfels die Wahrscheinlichkeitsfunktion definiert durch
![{\displaystyle f\colon \{1,\dots ,6\}\to [0,1],\quad f(i)={\tfrac {1}{6}}{\text{ für }}i=1,\dotsc ,6}](/svg/6f1dac4e18e7126465a6ac764d5afe33b945ef1b.svg) .
.
Ein Beispiel für eine Wahrscheinlichkeitsfunktion auf einer abzählbar unendlichen Menge liefert die geometrische Verteilung, eine ihrer Varianten besitzt die Wahrscheinlichkeitsfunktion
 .
.
Dabei ist  .
Die Normiertheit folgt hier mittels der geometrischen
Reihe. Aus formaler Sicht ist wichtig, dass Wahrscheinlichkeitsfunktionen
nicht wie Wahrscheinlichkeitsmaße Mengen als Argumente nehmen, sondern
Elemente der Grundmenge .
Daher wäre die Schreibweise
.
Die Normiertheit folgt hier mittels der geometrischen
Reihe. Aus formaler Sicht ist wichtig, dass Wahrscheinlichkeitsfunktionen
nicht wie Wahrscheinlichkeitsmaße Mengen als Argumente nehmen, sondern
Elemente der Grundmenge .
Daher wäre die Schreibweise  falsch, korrekterweise heißt es
falsch, korrekterweise heißt es  .
.
Aus maßtheoretischer Sicht lassen sich Wahrscheinlichkeitsfunktionen auch als Wahrscheinlichkeitsdichten auffassen. Sie sind dann die Wahrscheinlichkeitsdichten bezüglich des Zählmaßes. Daher werden Wahrscheinlichkeitsfunktionen auch als Zähldichten bezeichnet. Trotz dieser Gemeinsamkeit wird streng zwischen den Wahrscheinlichkeitsfunktionen (auf diskreten Grundräumen) und den Wahrscheinlichkeitsdichten (auf stetigen Grundräumen) unterschieden.
Wahrscheinlichkeitsdichtefunktionen
Auf den reellen Zahlen  ,
versehen mit der Borelschen
σ-Algebra
lassen sich Wahrscheinlichkeitsmaße über Wahrscheinlichkeitsdichtefunktionen
definieren. Dies sind integrierbare
Funktionen
,
versehen mit der Borelschen
σ-Algebra
lassen sich Wahrscheinlichkeitsmaße über Wahrscheinlichkeitsdichtefunktionen
definieren. Dies sind integrierbare
Funktionen  ,
für die gilt:
,
für die gilt:
- Positivität:

- Normiertheit:

Das Wahrscheinlichkeitsmaß wird dann für  durch
durch

definiert.
Das Integral ist hier ein Lebesgue-Integral.
In vielen Fällen ist jedoch ein Riemann-Integral
ausreichend, man schreibt dann  anstelle von
anstelle von  .
Typisches Beispiel eines Wahrscheinlichkeitsmaßes, das auf diese Art definiert
wird, ist die Exponentialverteilung.
Sie besitzt die Wahrscheinlichkeitsdichtefunktion
.
Typisches Beispiel eines Wahrscheinlichkeitsmaßes, das auf diese Art definiert
wird, ist die Exponentialverteilung.
Sie besitzt die Wahrscheinlichkeitsdichtefunktion

Es ist dann beispielsweise
![{\displaystyle P((-1,1])=\int _{(-1,1]}f_{\lambda }(x)\mathrm {d} x=\int _{[0,1]}\lambda {\rm {e}}^{-\lambda x}\mathrm {d} x=1-\mathrm {e} ^{-\lambda }}](/svg/ba5946380d9407e8b6045627852c8414be47f3ab.svg)
für einen Parameter  .
Das Konzept von Wahrscheinlichkeitsdichtefunktionen kann auch auf den
.
Das Konzept von Wahrscheinlichkeitsdichtefunktionen kann auch auf den  ausgeweitet werden. Es lassen sich aber nicht alle Wahrscheinlichkeitsmaße durch
eine Wahrscheinlichkeitsdichte darstellen, sondern nur diejenigen, die absolutstetig
bezüglich des Lebesgue-Maßes
sind.
ausgeweitet werden. Es lassen sich aber nicht alle Wahrscheinlichkeitsmaße durch
eine Wahrscheinlichkeitsdichte darstellen, sondern nur diejenigen, die absolutstetig
bezüglich des Lebesgue-Maßes
sind.
Verteilungsfunktionen
Auf den reellen Zahlen ,
versehen mit der Borelschen
σ-Algebra
lassen sich Wahrscheinlichkeitsmaße auch mit Verteilungsfunktionen
definieren. Eine Verteilungsfunktion ist eine Funktion
![{\displaystyle F\colon \mathbb {R} \to [0,1]}](/svg/d554e9659b1b9888629676b3c070ca42d86ecfca.svg)
mit den Eigenschaften
 ist monoton
wachsend.
ist monoton
wachsend.-
ist rechtsseitig
stetig sowie
 .
.
Für jede Verteilungsfunktion gibt es ein eindeutig bestimmtes
Wahrscheinlichkeitsmaß
mit
![{\displaystyle P((-\infty ,x])=F(x)}](/svg/770fb2d4647cda93e85b6217be148fc907c360d0.svg) .
.
Umgekehrt kann mittels der obigen Identität jedem Wahrscheinlichkeitsmaß eine Verteilungsfunktion zugeordnet werden. Die Zuordnung von Wahrscheinlichkeitsmaß und Verteilungsfunktion ist somit nach dem Korrespondenzsatz bijektiv. Die Wahrscheinlichkeiten eines Intervalles enthält man dann über
![{\displaystyle P((a,b])=F(b)-F(a)}](/svg/935003a95c49bca2badc7b6a939b31d0bc2e7e51.svg) .
.
Insbesondere lässt sich auch jedem Wahrscheinlichkeitsmaß auf  oder
oder  eine Verteilungsfunktion zuordnen. So ist die Bernoulli-Verteilung
auf der Grundmenge
eine Verteilungsfunktion zuordnen. So ist die Bernoulli-Verteilung
auf der Grundmenge  definiert durch
definiert durch  für einen reellen Parameter
für einen reellen Parameter  .
Aufgefasst als Wahrscheinlichkeitsmaß auf den reellen Zahlen besitzt sie die
Verteilungsfunktion
.
Aufgefasst als Wahrscheinlichkeitsmaß auf den reellen Zahlen besitzt sie die
Verteilungsfunktion
 .
.
Verteilungsfunktionen können auch für den
definiert werden, man spricht dann von multivariaten
Verteilungsfunktionen.
Allgemeine Verfahren
Verteilungen
Mittels der Verteilung einer Zufallsvariablen kann ein Wahrscheinlichkeitsmaß über eine Zufallsvariable in einen zweiten Messraum übertragen werden und erzeugt dort wieder eine entsprechend der Zufallsvariablen transformierte Wahrscheinlichkeitsverteilung. Dieses Vorgehen entspricht der Konstruktion eines Bildmaßes in der Maßtheorie und liefert viele wichtige Verteilungen wie beispielsweise die Binomialverteilung.
Normierung
Jedes endliche Maß, welches nicht das Null-Maß ist, kann durch Normierung in
ein Wahrscheinlichkeitsmaß umgewandelt werden. Ebenso kann man ein σ-endliches
Maß  in ein Wahrscheinlichkeitsmaß transformieren, dies ist aber nicht eindeutig. Ist
in ein Wahrscheinlichkeitsmaß transformieren, dies ist aber nicht eindeutig. Ist
 eine Zerlegung des Grundraumes in Mengen endlichen Maßes wie in der Definition
des σ-endlichen Maßes gefordert, so liefert beispielsweise
eine Zerlegung des Grundraumes in Mengen endlichen Maßes wie in der Definition
des σ-endlichen Maßes gefordert, so liefert beispielsweise

das Geforderte.
Produktmaße
Eine wichtige Möglichkeit, Wahrscheinlichkeitsmaße auf großen Räumen zu definieren, sind die Produktmaße. Dabei bildet man das kartesische Produkt zweier Grundmengen und fordert, dass das Wahrscheinlichkeitsmaß auf dieser größeren Menge (auf gewissen Mengen) genau dem Produkt der Wahrscheinlichkeitsmaße auf den kleineren Mengen entspricht. Insbesondere unendliche Produktmaße sind wichtig für die Existenz stochastischer Prozesse.
Eindeutigkeit der Konstruktionen
Bei der Konstruktion von Wahrscheinlichkeitsmaßen werden diese häufig nur
durch ihre Werte auf wenigen, besonders einfach zu handhabenden Mengen
definiert. Beispiel hierfür ist die Konstruktion mittels einer
Verteilungsfunktion, die nur die Wahrscheinlichkeiten der Intervalle ![{\displaystyle (-\infty ,a]}](/svg/aeced831f088e701d1985fb783959d2309e0d32a.svg) vorgibt. Die Borelsche σ-Algebra enthält aber weitaus komplexere Mengen als
diese Intervalle. Um die Eindeutigkeit der Definitionen zu garantieren, muss man
zeigen, dass kein zweites Wahrscheinlichkeitsmaß existiert, das auf den
Intervallen die geforderten Werte annimmt, sich aber auf einer weiteren,
möglicherweise sehr komplexen Menge der Borelschen σ-Algebra von dem ersten
Wahrscheinlichkeitsmaß unterscheidet. Dies leistet der folgende
Maßeindeutigkeitssatz
aus der Maßtheorie:
vorgibt. Die Borelsche σ-Algebra enthält aber weitaus komplexere Mengen als
diese Intervalle. Um die Eindeutigkeit der Definitionen zu garantieren, muss man
zeigen, dass kein zweites Wahrscheinlichkeitsmaß existiert, das auf den
Intervallen die geforderten Werte annimmt, sich aber auf einer weiteren,
möglicherweise sehr komplexen Menge der Borelschen σ-Algebra von dem ersten
Wahrscheinlichkeitsmaß unterscheidet. Dies leistet der folgende
Maßeindeutigkeitssatz
aus der Maßtheorie:
Ist
ein Wahrscheinlichkeitsmaß auf der σ-Algebra
und ist  ein durchschnittsstabiler
Erzeuger
dieser σ-Algebra, also
ein durchschnittsstabiler
Erzeuger
dieser σ-Algebra, also  ,
so ist
bereits durch seine Werte auf
eindeutig bestimmt. Genauer: Ist
,
so ist
bereits durch seine Werte auf
eindeutig bestimmt. Genauer: Ist  ein weiteres Wahrscheinlichkeitsmaß und ist
ein weiteres Wahrscheinlichkeitsmaß und ist

so ist  .
Typische Erzeuger von σ-Algebren sind
.
Typische Erzeuger von σ-Algebren sind
- für endliche oder abzählbar unendliche Mengen ,
versehen mit der Potenzmenge das Mengensystem der Elemente von ,
also
 ,
,
- für die Borelsche σ-Algebra
 auf
das System der Intervalle
auf
das System der Intervalle
![{\displaystyle {\mathcal {E}}=\{I\,|\,I=(-\infty ,a]{\text{ für ein }}a\in \mathbb {R} \}}](/svg/93ae17184bae503aba85d5a887c134148c23a551.svg) ,
,
- für die Produkt-σ-Algebra das System der Zylindermengen.
Diese Erzeuger liefern somit die Eindeutigkeit der Konstruktion von Wahrscheinlichkeitsmaßen mittels Wahrscheinlichkeitsfunktionen, Verteilungsfunktionen und Produktmaßen.
Typen von Wahrscheinlichkeitsverteilungen
Diskrete Verteilungen
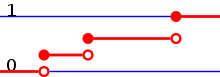
Als diskrete Verteilungen werden Wahrscheinlichkeitsverteilungen auf
endlichen oder abzählbar
unendlichen Grundräumen bezeichnet. Diese Grundräume werden fast immer mit
der Potenzmenge als
Mengensystem versehen, die Wahrscheinlichkeiten werden dann meist über
Wahrscheinlichkeitsfunktionen
definiert. Diskrete Verteilungen auf den natürlichen oder ganzen Zahlen können
in den Messraum
 eingebettet werden und besitzen dann auch eine Verteilungsfunktion.
Diese zeichnet sich durch ihre Sprungstellen aus.
eingebettet werden und besitzen dann auch eine Verteilungsfunktion.
Diese zeichnet sich durch ihre Sprungstellen aus.
Stetige Verteilungen
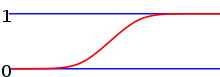
Verteilungen auf den reellen Zahlen, versehen mit der borelschen σ-Algebra werden als stetige Verteilung bezeichnet, wenn sie stetige Verteilungsfunktionen besitzen. Die stetigen Verteilungen lassen sich noch in absolutstetige und stetigsinguläre Wahrscheinlichkeitsverteilungen unterteilen.
Absolutstetige Wahrscheinlichkeitsverteilungen
Als absolutstetige Wahrscheinlichkeitsverteilungen bezeichnet man diejenigen Wahrscheinlichkeitsverteilungen, die eine Wahrscheinlichkeitsdichtefunktion besitzen, sich also in der Form
![{\displaystyle P((-\infty ,x])=\int _{(-\infty ,x]}f_{P}\,\mathrm {d} \lambda }](/svg/9485a407a1a5149ac09c847ed750a2f618043174.svg)
darstellen lassen für eine integrierbare Funktion
 .
Hierbei handelt es sich um ein Lebesgue-Integral,
das aber in den meisten Fällen durch ein Riemann-Integral
ersetzt werden kann.
.
Hierbei handelt es sich um ein Lebesgue-Integral,
das aber in den meisten Fällen durch ein Riemann-Integral
ersetzt werden kann.
Diese Definition kann auch auf Verteilungen auf dem
entsprechend ausgeweitet werden. Aus maßtheoretischer Sicht handelt es sich nach
dem Satz
von Radon-Nikodým bei den absolutstetigen Verteilungen genau um die absolutstetigen
Maße bezüglich des Lebesgue-Maßes.
Stetigsinguläre Wahrscheinlichkeitsverteilungen
Als stetigsinguläre Verteilungen werden diejenigen Wahrscheinlichkeitsverteilungen bezeichnet, die zwar eine stetige Verteilungsfunktion, aber keine Wahrscheinlichkeitsdichtefunktion besitzen. Stetigsinguläre Wahrscheinlichkeitsverteilungen sind in der Anwendung selten und werden meist gezielt konstruiert. Beispiel hierfür ist das pathologische Beispiel der Cantor-Verteilung.
Mischformen und ihre Zerlegung
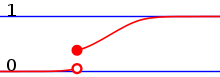
Außer den oben genannten Reinformen von Wahrscheinlichkeitsverteilungen existieren noch Mischformen. Diese entstehen beispielsweise, wenn man Konvexkombinationen von diskreten und stetigen Verteilungen bildet.
Umgekehrt kann man nach dem Darstellungssatz jede Wahrscheinlichkeitsverteilung eindeutig in ihre absolutstetigen, stetigsingulären und diskreten Anteile zerlegt werden.
Univariate und multivariate Verteilungen
Wahrscheinlichkeitsverteilungen, die sich in mehrere Raumdimensionen
erstrecken, werden multivariate
Verteilungen genannt. Im Gegensatz dazu nennt man die eindimensionalen
Verteilungen univariate
Wahrscheinlichkeitsverteilungen. Die Dimensionalität bezieht sich hier nur
auf den Grundraum, nicht auf die Parameter, welche die
Wahrscheinlichkeitsverteilung beschreiben. So ist die (gewöhnliche) Normalverteilung eine
univariate Verteilung, auch wenn sie durch zwei Formparameter  bestimmt wird.
bestimmt wird.
Des Weiteren existieren noch matrixvariate Wahrscheinlichkeitsverteilungen wie die Wishart-Verteilung.
Charakterisierung durch Kennzahlen
Wahrscheinlichkeitsverteilungen können unterschiedliche Kennzahlen zugeordnet werden. Diese versuchen jeweils, eine Eigenschaft einer Wahrscheinlichkeitsverteilung zu quantifizieren und damit kompakte Aussagen über die Eigenheiten der Verteilung zu ermöglichen. Beispiele hierfür sind:
Kennzahlen, die auf den Momenten beruhen:
- Erwartungswert, die Kennzahl für die mittlere Lage einer Wahrscheinlichkeitsverteilung
- Varianz und die daraus berechnete Standardabweichung, Kennzahl für den Grad der „Streuung“ der Verteilung
- Schiefe, Kennzahl für die Asymmetrie der Verteilung
- Wölbung, Kennzahl für die „Spitzigkeit“ der Verteilung
Des Weiteren gibt es
- den Median, der sich über die verallgemeinerte inverse Verteilungsfunktion berechnen lässt
- allgemeiner die Quantile, beispielsweise die Terzile, Quartile, Dezile etc.
Allgemein unterscheidet man zwischen Lagemaßen und Dispersionsmaßen. Lagemaße wie der Erwartungswert geben an, „wo“ sich die Wahrscheinlichkeitsverteilung befindet und was „typische“ Werte sind, Dispersionsmaße wie die Varianz hingegen geben an, wie sehr die Verteilung um diese typischen Werte streut.
Wichtige Wahrscheinlichkeitsmaße
Diskret
Eine der elementaren Wahrscheinlichkeitsverteilungen ist die Bernoulli-Verteilung. Sie modelliert einen Münzwurf mit einer möglicherweise gezinkten Münze. Dementsprechend gibt es zwei Ausgänge: Kopf oder Zahl, häufig der Einfachheit halber mit 0 und 1 codiert. Darauf aufbauend ist die Binomialverteilung. Sie gibt die Wahrscheinlichkeit an, bei n Würfen mit einer Münze k-mal Kopf zu werfen.
Eine weitere wichtige Wahrscheinlichkeitsverteilung ist die diskrete Gleichverteilung. Sie entspricht dem Würfeln mit einem fairen, n-flächigen Würfel. Jede Fläche hat demnach dieselbe Wahrscheinlichkeit. Ihr Bedeutung kommt daher, dass sich aus der diskreten Gleichverteilung über das Urnenmodell eine große Anzahl weiterer Wahrscheinlichkeitsverteilungen als Verteilung von entsprechenden Zufallsvariablen erzeugen lassen. Auf diese Weise lassen sich beispielsweise die hypergeometrische Verteilung, die geometrische Verteilung und die negative Binomialverteilung erzeugen.
Stetig
Herausragend unter den stetigen Verteilungen ist die Normalverteilung. Diese Sonderstellung ist auf den zentralen Grenzwertsatz zurückzuführen. Er besagt, dass unter gewissen Umständen eine Überlagerung zufälliger Ereignisse sich immer mehr der Normalverteilung annähert. Dementsprechend wichtig ist die Normalverteilung in der Statistik. Direkt aus ihr abgeleitet sind die Chi-Quadrat-Verteilung und die Studentsche t-Verteilung, die zur Parameterschätzung in der Statistik verwendet werden.
Verteilungsklassen
Als Verteilungsklassen bezeichnet man eine Menge von Wahrscheinlichkeitsmaßen, die sich durch eine gemeinsame, mehr oder weniger allgemein formulierte Eigenschaft auszeichnen. Eine zentrale Verteilungsklasse in der Statistik ist die Exponentialfamilie, sie zeichnet sich durch eine allgemeine Dichtefunktion aus. Wichtige Verteilungsklassen in der Stochastik sind beispielsweise die unendlich teilbaren Verteilungen oder die alpha-stabilen Verteilungen.
Konvergenz von Wahrscheinlichkeitsmaßen
Die Konvergenz von Wahrscheinlichkeitsmaßen wird Konvergenz in Verteilung oder schwache Konvergenz genannt. Dabei betont die Benennung als
- Konvergenz in Verteilung, dass es sich um die Konvergenz von Verteilungen von Zufallsvariablen handelt,
- schwache Konvergenz, dass es sich um einen Spezialfall der schwachen Konvergenz von Maßen aus der Maßtheorie handelt.
Meist wird die Konvergenz in Verteilung als Bezeichnung bevorzugt, da dies einen besseren Vergleich mit den Konvergenzarten der Stochastik (Konvergenz in Wahrscheinlichkeit, Konvergenz im p-ten Mittel und fast sichere Konvergenz) ermöglicht, die alle Konvergenzarten von Zufallsvariablen und nicht von Wahrscheinlichkeitsmaßen sind.
Es existieren viele äquivalente Charakterisierungen der schwachen Konvergenz / Konvergenz in Verteilung. Diese werden im Portmanteau-Theorem aufgezählt.
Auf den reellen Zahlen
Die Konvergenz in Verteilung wird auf den reellen Zahlen über die Verteilungsfunktionen definiert:
- Eine Folge von Wahrscheinlichkeitsmaßen
 konvergiert genau dann schwach gegen das Wahrscheinlichkeitsmaß ,
wenn die Verteilungsfunktionen
konvergiert genau dann schwach gegen das Wahrscheinlichkeitsmaß ,
wenn die Verteilungsfunktionen  an jeder Stetigkeitsstelle der Verteilungsfunktion
an jeder Stetigkeitsstelle der Verteilungsfunktion  punktweise gegen diese konvergieren.
punktweise gegen diese konvergieren. - Eine Folge von Zufallsvariablen
 heißt konvergent in Verteilung gegen ,
wenn die Verteilungsfunktionen
heißt konvergent in Verteilung gegen ,
wenn die Verteilungsfunktionen  an jeder Stetigkeitsstelle der Verteilungsfunktion
an jeder Stetigkeitsstelle der Verteilungsfunktion  punktweise gegen diese konvergieren.
punktweise gegen diese konvergieren.
Diese Charakterisierung der schwachen Konvergenz / Konvergenz in Verteilung
ist eine Folgerung aus dem Satz
von Helly-Bray, wird aber oft als Definition genutzt, da sie leichter
zugänglich ist als die allgemeine Definition. Die obige Definition entspricht
der schwachen
Konvergenz von Verteilungsfunktionen für den Spezialfall von
Wahrscheinlichkeitsmaßen, wo sie der Konvergenz bezüglich des Lévy-Abstandes
entspricht. Der Satz von Helly-Bray liefert die Äquivalenz der schwachen
Konvergenz von Verteilungsfunktionen und der schwachen Konvergenz / Konvergenz
in Verteilung auf .
Allgemeiner Fall
Im allgemeinen Fall wird die schwache Konvergenz / Konvergenz in Verteilung
durch eine trennende
Familie charakterisiert. Ist  ein metrischer
Raum, sei als σ-Algebra immer die Borelsche
σ-Algebra gewählt und sei
ein metrischer
Raum, sei als σ-Algebra immer die Borelsche
σ-Algebra gewählt und sei  die Menge der beschränkten
stetigen Funktionen. Dann heißt
die Menge der beschränkten
stetigen Funktionen. Dann heißt
- eine Folge von Wahrscheinlichkeitsmaßen
 schwach konvergent gegen das Wahrscheinlichkeitsmaß ,
wenn
schwach konvergent gegen das Wahrscheinlichkeitsmaß ,
wenn

- eine Folge von Zufallsvariablen
 konvergent in Verteilung gegen ,
wenn
konvergent in Verteilung gegen ,
wenn

Meist werden noch weitere strukturelle Eigenschaften von der Grundmenge gefordert, um gewisse Eigenschaften der Konvergenz zu garantieren.
Räume von Wahrscheinlichkeitsmaßen
Die Eigenschaften der Menge von Wahrscheinlichkeitsmaßen hängen maßgeblich von den Eigenschaften des Grundraumes und der σ-Algebra ab. Im Folgenden wird eine Übersicht über die wichtigsten Eigenschaften der Menge der Wahrscheinlichkeitsmaße gegeben. Dabei sind die allgemeinsten Eigenschaften zuerst genannt und folgen, soweit nicht explizit anders erwähnt, auch für alle weiter unten stehenden Abschnitte. Als Notation sei vereinbart:
-
ist die Borelsche
σ-Algebra, falls
mindestens ein topologischer
Raum ist.
 ist die Menge der endlichen signierten
Maße auf dem Messraum
ist die Menge der endlichen signierten
Maße auf dem Messraum
 .
. ist die Menge der endlichen
Maße auf dem entsprechenden Messraum.
ist die Menge der endlichen
Maße auf dem entsprechenden Messraum. ist die Menge der Sub-Wahrscheinlichkeitsmaße
auf dem entsprechenden Messraum.
ist die Menge der Sub-Wahrscheinlichkeitsmaße
auf dem entsprechenden Messraum. ist die Menge der Wahrscheinlichkeitsmaße auf dem entsprechenden
Messraum.
ist die Menge der Wahrscheinlichkeitsmaße auf dem entsprechenden
Messraum.
Allgemeine Grundräume
Auf allgemeinen Mengen sind die Wahrscheinlichkeitsmaße eine Teilmenge des reellen Vektorraumes der endlichen signierten Maße. Es gelten demnach die Inklusionen
 .
.
Der Vektorraum der endlichen signierten Maße wird mit der
Totalvariationsnorm
 zu einem normierten Vektorraum. Da die Wahrscheinlichkeitsmaße aber nur eine
Teilmenge und kein Untervektorraum
der signierten Maße sind, sind sie selbst kein normierter Raum. Anstelle dessen
werden sie mit dem Totalvariationsabstand
zu einem normierten Vektorraum. Da die Wahrscheinlichkeitsmaße aber nur eine
Teilmenge und kein Untervektorraum
der signierten Maße sind, sind sie selbst kein normierter Raum. Anstelle dessen
werden sie mit dem Totalvariationsabstand

zu einem metrischen
Raum. Ist  eine dominierte
Verteilungsklasse, besitzen also alle Maße in dieser Menge eine
Wahrscheinlichkeitsdichtefunktion bezüglich eines einzigen σ-endlichen
Maßes, so ist die Konvergenz bezüglich des Totalvariationsabstandes
äquivalent zur Konvergenz bezüglich des Hellingerabstandes.
eine dominierte
Verteilungsklasse, besitzen also alle Maße in dieser Menge eine
Wahrscheinlichkeitsdichtefunktion bezüglich eines einzigen σ-endlichen
Maßes, so ist die Konvergenz bezüglich des Totalvariationsabstandes
äquivalent zur Konvergenz bezüglich des Hellingerabstandes.
Metrische Räume
Ist
ein metrischer Raum, so lässt sich auf  die schwache
Konvergenz definieren. Bezeichnet man die von der schwachen Konvergenz
erzeugten Topologie mit
die schwache
Konvergenz definieren. Bezeichnet man die von der schwachen Konvergenz
erzeugten Topologie mit  und die entsprechenden Spurtopologie
auf den Wahrscheinlichkeitsmaßen als
und die entsprechenden Spurtopologie
auf den Wahrscheinlichkeitsmaßen als  ,
so wird
,
so wird  zu einem topologischen
Raum, der sogar ein Hausdorff-Raum
ist. Außerdem sind Limites schwach konvergenter Folgen von
Wahrscheinlichkeitsmaßen immer selbst Wahrscheinlichkeitsmaße (setze dazu
zu einem topologischen
Raum, der sogar ein Hausdorff-Raum
ist. Außerdem sind Limites schwach konvergenter Folgen von
Wahrscheinlichkeitsmaßen immer selbst Wahrscheinlichkeitsmaße (setze dazu  in der Definition). Die Konvergenz bezüglich des Totalvariationsabstandes
impliziert immer die schwache Konvergenz, die Umkehrung gilt aber im Allgemeinen
nicht. Somit ist die vom Totalvariationsabstand erzeugte Topologie
in der Definition). Die Konvergenz bezüglich des Totalvariationsabstandes
impliziert immer die schwache Konvergenz, die Umkehrung gilt aber im Allgemeinen
nicht. Somit ist die vom Totalvariationsabstand erzeugte Topologie  stärker als .
stärker als .
Des Weiteren lässt sich noch die Prochorow-Metrik
 auf
auf  definieren. Sie macht
definieren. Sie macht  zu einem metrischen Raum. Außerdem impliziert die Konvergenz bezüglich der
Prochorow-Metrik in allgemeinen metrischen Räumen die schwache Konvergenz. Die
von ihr erzeugte Topologie ist demnach stärker als .
zu einem metrischen Raum. Außerdem impliziert die Konvergenz bezüglich der
Prochorow-Metrik in allgemeinen metrischen Räumen die schwache Konvergenz. Die
von ihr erzeugte Topologie ist demnach stärker als .
Separable metrische Räume
Ist
ein separabler
metrischer Raum, so ist auch  ein separabler metrischer Raum (tatsächlich gilt auch der Umkehrschluss). Da
sich bei metrischen Räumen die Separabilität auf Teilmengen überträgt, ist auch
separabel.
ein separabler metrischer Raum (tatsächlich gilt auch der Umkehrschluss). Da
sich bei metrischen Räumen die Separabilität auf Teilmengen überträgt, ist auch
separabel.
Außerdem sind auf separablen metrischen Räumen die schwache Konvergenz und
die Konvergenz bezüglich der Prochorow-Metrik äquivalent. Die Prochorow-Metrik
metrisiert
also .
Polnische Räume
Ist
ein polnischer
Raum, so ist auch
ein polnischer Raum. Da
abgeschlossen ist in ,
ist auch
ein polnischer Raum.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 28.09. 2021