Wahrscheinlichkeitsdichtefunktion
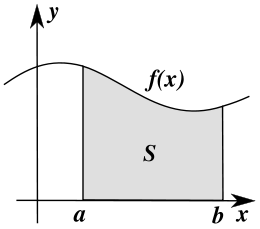
 und
und  annimmt, entspricht dem Inhalt der Fläche
annimmt, entspricht dem Inhalt der Fläche  unter dem Graph der Wahrscheinlichkeitsdichtefunktion
unter dem Graph der Wahrscheinlichkeitsdichtefunktion  .
.Eine Wahrscheinlichkeitsdichtefunktion, oft kurz Dichtefunktion, Wahrscheinlichkeitsdichte, Verteilungsdichte oder nur Dichte genannt und mit WDF oder englisch pdf von probability density function abgekürzt, ist eine spezielle reellwertige Funktion in der Stochastik, einem Teilgebiet der Mathematik. Dort dienen die Wahrscheinlichkeitsdichtefunktionen zur Konstruktion von Wahrscheinlichkeitsverteilungen mithilfe von Integralen sowie zur Untersuchung und Klassifikation von Wahrscheinlichkeitsverteilungen.
Im Gegensatz zu Wahrscheinlichkeiten können
Wahrscheinlichkeitsdichtefunktionen auch Werte über eins annehmen. Die
Konstruktion von Wahrscheinlichkeitsverteilungen über
Wahrscheinlichkeitsdichtefunktionen beruht auf der Idee, dass die Fläche
zwischen der Wahrscheinlichkeitsdichtefunktion und der x-Achse von einem Punkt
bis zu einem Punkt
der Wahrscheinlichkeit entspricht, einen Wert zwischen
und
zu erhalten. Nicht der Funktionswert der Wahrscheinlichkeitsdichtefunktion ist
somit relevant, sondern die Fläche unter ihrem Funktionsgraph,
also das Integral.
In einem allgemeineren Kontext handelt es sich bei Wahrscheinlichkeitsdichtefunktionen um Dichtefunktionen (im Sinne der Maßtheorie) bezüglich des Lebesgue-Maßes.
Während im diskreten Fall Wahrscheinlichkeiten von Ereignissen durch
Aufsummieren der Wahrscheinlichkeiten der einzelnen Elementarereignisse
berechnet werden können (ein idealer Würfel zeigt beispielsweise jede Zahl mit
einer Wahrscheinlichkeit von  ),
gilt dies nicht mehr für den stetigen Fall. Beispielsweise sind zwei Menschen
kaum exakt gleich groß, sondern nur bis auf Haaresbreite oder weniger. In
solchen Fällen sind Wahrscheinlichkeitsdichtefunktionen nützlich. Mit Hilfe
dieser Funktionen lässt sich die Wahrscheinlichkeit für ein beliebiges Intervall
– beispielsweise eine Körpergröße zwischen 1,80 m und
1,81 m – bestimmen, obwohl unendlich viele Werte in diesem Intervall
liegen, von denen jeder einzelne die Wahrscheinlichkeit
),
gilt dies nicht mehr für den stetigen Fall. Beispielsweise sind zwei Menschen
kaum exakt gleich groß, sondern nur bis auf Haaresbreite oder weniger. In
solchen Fällen sind Wahrscheinlichkeitsdichtefunktionen nützlich. Mit Hilfe
dieser Funktionen lässt sich die Wahrscheinlichkeit für ein beliebiges Intervall
– beispielsweise eine Körpergröße zwischen 1,80 m und
1,81 m – bestimmen, obwohl unendlich viele Werte in diesem Intervall
liegen, von denen jeder einzelne die Wahrscheinlichkeit  hat.
hat.
Definition
Wahrscheinlichkeitsdichten können auf zwei Arten definiert werden: einmal als Funktion, aus der sich eine Wahrscheinlichkeitsverteilung konstruieren lässt, das andere Mal als Funktion, die aus einer Wahrscheinlichkeitsverteilung abgeleitet wird. Unterschied ist also die Richtung der Herangehensweise.
Zur Konstruktion von Wahrscheinlichkeitsmaßen
Gegeben sei eine reelle Funktion
 ,
für die gilt:
,
für die gilt:
-
ist nichtnegativ, das heißt,
 für alle
für alle  .
. -
ist integrierbar.
-
ist normiert in dem Sinne, dass
-
 .
.
Dann heißt
eine Wahrscheinlichkeitsdichtefunktion und definiert durch
![{\displaystyle P([a,b]):=\int _{a}^{b}f(x)\,\mathrm {d} x}](/svg/bc8420a5e0d9d51abcba931f5e011e6e8f364419.svg)
eine Wahrscheinlichkeitsverteilung auf den reellen Zahlen.
Aus Wahrscheinlichkeitsmaßen abgeleitet
Gegeben sei eine Wahrscheinlichkeitsverteilung  oder eine reellwertige Zufallsvariable
oder eine reellwertige Zufallsvariable
 .
.
Existiert eine reelle Funktion
,
sodass für alle 
![{\displaystyle P((-\infty ,a])=\int _{-\infty }^{a}f(x)\,\mathrm {d} x}](/svg/48fb41cb1600798fcbb82405eed24043e171b94a.svg)
bzw.

gilt, so heißt
die Wahrscheinlichkeitsdichtefunktion von
bzw. von .
Beispiele
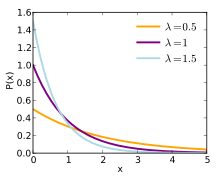
Eine Wahrscheinlichkeitsverteilung, die über eine Wahrscheinlichkeitsdichtefunktion definiert werden kann, ist die Exponentialverteilung. Sie besitzt die Wahrscheinlichkeitsdichtefunktion
Hierbei ist  ein reeller Parameter. Insbesondere überschreitet die
Wahrscheinlichkeitsdichtefunktion für Parameter
ein reeller Parameter. Insbesondere überschreitet die
Wahrscheinlichkeitsdichtefunktion für Parameter  an der Stelle
an der Stelle  den Funktionswert
den Funktionswert  ,
wie in der Einleitung beschrieben. Dass es sich bei
,
wie in der Einleitung beschrieben. Dass es sich bei  wirklich um eine Wahrscheinlichkeitsdichtefunktion handelt, folgt aus den
elementaren Integrationsregeln für die Exponentialfunktion,
Positivität und Integrierbarkeit der Exponentialfunktion sind klar.
wirklich um eine Wahrscheinlichkeitsdichtefunktion handelt, folgt aus den
elementaren Integrationsregeln für die Exponentialfunktion,
Positivität und Integrierbarkeit der Exponentialfunktion sind klar.
Eine Wahrscheinlichkeitsverteilung, aus der eine
Wahrscheinlichkeitsdichtefunktion abgeleitet werden kann, ist die stetige
Gleichverteilung auf dem Intervall ![[0,1]](/svg/738f7d23bb2d9642bab520020873cccbef49768d.svg) .
Sie ist definiert durch
.
Sie ist definiert durch
![{\displaystyle P([a,b])=b-a}](/svg/6052c0e18e49b3f8c4e3b8b4202077ef3688ccc7.svg) für
für  und
und ![{\displaystyle a,b\in [0,1]}](/svg/60ee2939f5ce032e8c7851830c3e89f6eee99c7e.svg)
Außerhalb des Intervalls erhalten alle Ereignisse die Wahrscheinlichkeit
null. Gesucht ist nun eine Funktion ,
für die
![{\displaystyle \int _{a}^{b}f(x)\,\mathrm {d} x=P([a,b])=b-a}](/svg/b2930c09ea9d8790b88d49b01e408265fb8468d7.svg)
gilt, falls .
Die Funktion

erfüllt dies. Sie wird dann außerhalb des Intervalles
durch die Null fortgesetzt, um problemlos über beliebige Teilmengen der reellen
Zahlen integrieren zu können. Eine Wahrscheinlichkeitsdichtefunktion der
stetigen Gleichverteilung wäre somit:
![{\displaystyle f(x)={\begin{cases}\displaystyle 1&{\text{ falls }}x\in [0,1]\\0&{\text{ sonst }}\end{cases}}}](/svg/7794ae707a329efb8b2e59a7d5a515020e943ce7.svg)
Ebenso wäre die Wahrscheinlichkeitsdichtefunktion

möglich, da sich beide nur auf einer Lebesgue-Nullmenge unterscheiden und beide den Anforderungen genügen. Man könnte beliebig viele Wahrscheinlichkeitsdichtefunktionen allein durch Abwandlung des Wertes an einem Punkt erzeugen. Faktisch ändert dies nichts an den Eigenschaft der Funktion, Wahrscheinlichkeitsdichtefunktion zu sein, da das Integral diese kleinen Modifikationen ignoriert.
Bemerkungen zur Definition
Streng genommen handelt es sich bei dem Integral in der Definition um ein Lebesgue-Integral
bezüglich des Lebesgue-Maßes
 und es müsste dementsprechend als
und es müsste dementsprechend als  geschrieben werden. In den meisten Fällen ist das herkömmliche Riemann-Integral aber
ausreichend, weshalb hier
geschrieben werden. In den meisten Fällen ist das herkömmliche Riemann-Integral aber
ausreichend, weshalb hier  geschrieben wird. Nachteil des Riemann-Integrals auf struktureller Ebene ist,
dass es sich nicht wie das Lebesgue-Integral in einen allgemeinen maßtheoretischen Rahmen
einbetten lässt. Für Details zur Beziehung von Lebesgue- und Riemann-Integral
siehe Riemann-
und Lebesgue-Integral.
geschrieben wird. Nachteil des Riemann-Integrals auf struktureller Ebene ist,
dass es sich nicht wie das Lebesgue-Integral in einen allgemeinen maßtheoretischen Rahmen
einbetten lässt. Für Details zur Beziehung von Lebesgue- und Riemann-Integral
siehe Riemann-
und Lebesgue-Integral.
Manche Autoren unterscheiden die beiden obigen Herangehensweisen auch namentlich. So wird die Funktion, die zur Konstruktion von Wahrscheinlichkeitsverteilungen verwendet wird, dann Wahrscheinlichkeitsdichte genannt, die aus einer Wahrscheinlichkeitsverteilung abgeleitete Funktion hingegen Verteilungsdichte.
Existenz und Eindeutigkeit
Konstruktion von Wahrscheinlichkeitsverteilungen
Das in der Definition beschriebene
liefert wirklich eine Wahrscheinlichkeitsverteilung. Denn aus der Normiertheit
folgt  .
Dass die Wahrscheinlichkeiten alle positiv sind, folgt aus der Positivität der
Funktion. Die σ-Additivität
folgt aus dem Satz
von der majorisierten Konvergenz mit der Wahrscheinlichkeitsdichtefunktion
als Majorante und der Funktionenfolge
.
Dass die Wahrscheinlichkeiten alle positiv sind, folgt aus der Positivität der
Funktion. Die σ-Additivität
folgt aus dem Satz
von der majorisierten Konvergenz mit der Wahrscheinlichkeitsdichtefunktion
als Majorante und der Funktionenfolge
 ,
,
mit paarweise disjunkten Mengen  .
.
Hierbei bezeichnet  die charakteristische
Funktion auf der Menge
die charakteristische
Funktion auf der Menge  .
.
Dass die Wahrscheinlichkeitsverteilung eindeutig ist, folgt aus dem Maßeindeutigkeitssatz und der Schnittstabilität des Erzeugers der Borelschen σ-Algebra, hier das Mengensystem der abgeschlossenen Intervalle.
Aus einer Wahrscheinlichkeitsdichtefunktion abgeleitet
Die zentrale Aussage über die Existenz einer Wahrscheinlichkeitsdichtefunktion zu einer vorgegebenen Wahrscheinlichkeitsverteilung ist der Satz von Radon-Nikodým:
- Die Wahrscheinlichkeitsverteilung
besitzt genau dann eine Wahrscheinlichkeitsdichtefunktion, wenn sie absolut
stetig bezüglich des Lebesgue-Maßes
ist. Das bedeutet, dass aus
 immer
immer  folgen muss.
folgen muss.
Es kann durchaus mehr als eine solche Wahrscheinlichkeitsdichtefunktion existieren, aber diese unterscheiden sich nur auf einer Menge vom Lebesgue-Maß 0 voneinander, sind also fast überall identisch.
Somit können diskrete
Wahrscheinlichkeitsverteilungen keine Wahrscheinlichkeitsdichtefunktion
besitzen, denn für sie gilt immer  für ein passendes Element
für ein passendes Element  .
Solche Punktmengen besitzen aber immer das Lebesgue-Maß 0, somit sind diskrete
Wahrscheinlichkeitsverteilungen nicht absolut stetig bezüglich des
Lebesgue-Maßes.
.
Solche Punktmengen besitzen aber immer das Lebesgue-Maß 0, somit sind diskrete
Wahrscheinlichkeitsverteilungen nicht absolut stetig bezüglich des
Lebesgue-Maßes.
Berechnung von Wahrscheinlichkeiten
Grundlage
Die Wahrscheinlichkeit für ein Intervall lässt sich mit der
Wahrscheinlichkeitsdichte
berechnen als
![{\displaystyle P(X\in [a,b])=\int _{a}^{b}f(x)\,\mathrm {d} x}](/svg/085f9d43e54f4b7f26f7ac8283988df577e23382.svg) .
.
Diese Formel gilt ebenso für die Intervalle  ,
,
![(a,b]](/svg/6a6969e731af335df071e247ee7fb331cd1a57ae.svg) und
und  ,
denn es liegt in der Natur stetiger Zufallsvariablen, dass die
Wahrscheinlichkeit für das Annehmen eines konkreten Wertes
ist (unmögliches
Ereignis). Formal ausgedrückt gilt:
,
denn es liegt in der Natur stetiger Zufallsvariablen, dass die
Wahrscheinlichkeit für das Annehmen eines konkreten Wertes
ist (unmögliches
Ereignis). Formal ausgedrückt gilt:


Für komplexere Mengen kann die Wahrscheinlichkeit analog durch Integrieren über Teilintervalle ermittelt werden. Allgemein erhält die Wahrscheinlichkeit die Form
 .
.
Hilfreich ist oft die σ-Additivität
der Wahrscheinlichkeitsverteilung. Das bedeutet: Sind  paarweise
disjunkte Intervalle und ist
paarweise
disjunkte Intervalle und ist

die Vereinigung all dieser Intervalle, so gilt
 .
.
Dabei sind die Intervalle von der Form  .
Dies gilt auch für endlich viele Intervalle. Ist somit die Wahrscheinlichkeit
von disjunkten Intervallen zu berechnen, so kann man entsprechend zuerst die
Wahrscheinlichkeit jedes einzelnen Intervalles berechnen und diese
Wahrscheinlichkeiten dann aufsummieren.
.
Dies gilt auch für endlich viele Intervalle. Ist somit die Wahrscheinlichkeit
von disjunkten Intervallen zu berechnen, so kann man entsprechend zuerst die
Wahrscheinlichkeit jedes einzelnen Intervalles berechnen und diese
Wahrscheinlichkeiten dann aufsummieren.
Beispiel: Zeit zwischen Anrufen in einem Callcenter
Die Zeit zwischen zwei Anrufen in einem Callcenter
ist erfahrungsgemäß ungefähr exponentialverteilt
zu einem Parameter
und besitzt demnach die Wahrscheinlichkeitsdichtefunktion
 ,
,
vergleiche auch den Abschnitt Beispiele
und den Artikel Poisson-Prozess.
Dabei ist die x-Achse mit einer beliebigen Zeiteinheit versehen (Stunden,
Minuten, Sekunden). Der Parameter
entspricht dann der mittleren Anzahl von Anrufen pro Zeiteinheit.
Die Wahrscheinlichkeit, dass der nächste Anruf ein bis zwei Zeiteinheiten nach dem vorangegangenen eintritt, ist dann
![{\displaystyle P(X\in [1,2])=\int _{1}^{2}\lambda \mathrm {e} ^{-\lambda x}\,\mathrm {d} x=\lbrack -\mathrm {e} ^{-\lambda x}\rbrack _{1}^{2}=-\mathrm {e} ^{-2\lambda }+\mathrm {e} ^{-\lambda }}](/svg/68382583b8316c94d4694280e092218a09d1ac77.svg) .
.
Angenommen, eine Servicekraft im Callcenter benötigt fünf Zeiteinheiten für eine Pause. Die Wahrscheinlichkeit, dass sie keinen Anruf verpasst, ist gleich der Wahrscheinlichkeit, dass der nächste Anruf zum Zeitpunkt fünf oder später eingeht. Es ist damit

Eigenschaften
Zusammenhang von Verteilungsfunktion und Dichtefunktion
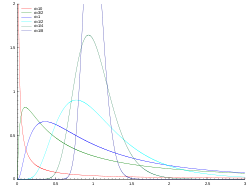
 )
)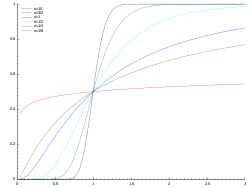 )
)Die Verteilungsfunktion
einer Zufallsvariablen
oder einer Wahrscheinlichkeitsverteilung
mit Wahrscheinlichkeitsdichtefunktion  beziehungsweise
beziehungsweise  wird als Integral über die Dichtefunktion gebildet:
wird als Integral über die Dichtefunktion gebildet:


Dies folgt direkt aus der Definition der Verteilungsfunktion. Die Verteilungsfunktionen von Zufallsvariablen oder Wahrscheinlichkeitsverteilungen mit Wahrscheinlichkeitsdichtefunktion sind somit immer stetig.
Wenn die Verteilungsfunktion  differenzierbar
ist, ist ihre Ableitung eine Dichtefunktion der Verteilung:
differenzierbar
ist, ist ihre Ableitung eine Dichtefunktion der Verteilung:

Dieser Zusammenhang gilt auch dann noch, wenn
stetig ist und es höchstens abzählbar viele Stellen
gibt, an denen
nicht differenzierbar ist; welche Werte man an diesen Stellen für  verwendet, ist unerheblich.
verwendet, ist unerheblich.
Allgemein existiert eine Dichtefunktion genau dann, wenn die
Verteilungsfunktion
absolut
stetig ist. Diese Bedingung impliziert unter anderem, dass
stetig ist und fast
überall eine Ableitung besitzt, die mit der Dichte übereinstimmt.
Es ist jedoch zu beachten, dass es Verteilungen wie die Cantor-Verteilung gibt, die eine stetige, fast überall differenzierbare Verteilungsfunktion besitzen, aber dennoch keine Wahrscheinlichkeitsdichte. Fast überall differenzierbar sind Verteilungsfunktionen immer, aber die entsprechende Ableitung erfasst generell nur den absolutstetigen Anteil der Verteilung.
Dichten auf Teilintervallen
Die Wahrscheinlichkeitsdichte einer Zufallsvariablen ,
die nur Werte in einem Teilintervall  der reellen Zahlen annimmt, kann so gewählt werden, dass sie außerhalb des
Intervalls den Wert
hat. Ein Beispiel ist die Exponentialverteilung
mit
der reellen Zahlen annimmt, kann so gewählt werden, dass sie außerhalb des
Intervalls den Wert
hat. Ein Beispiel ist die Exponentialverteilung
mit  .
Alternativ kann die Wahrscheinlichkeitsdichte als eine Funktion
.
Alternativ kann die Wahrscheinlichkeitsdichte als eine Funktion  betrachtet werden, d.h. als eine Dichte der Verteilung auf
bezüglich des Lebesgue-Maßes auf .
betrachtet werden, d.h. als eine Dichte der Verteilung auf
bezüglich des Lebesgue-Maßes auf .
Nichtlineare Transformation
Im Falle der nichtlinearen Transformation  gilt
gilt
 .
.
Faltung und Summe von Zufallsvariablen
Für Wahrscheinlichkeitsverteilungen mit Wahrscheinlichkeitsdichtefunktionen
kann die Faltung
(von Wahrscheinlichkeitsverteilungen) auf die Faltung (von
Funktionen) der entsprechenden Wahrscheinlichkeitsdichtefunktionen
zurückgeführt werden. Sind  Wahrscheinlichkeitsverteilungen mit Wahrscheinlichkeitsdichtefunktionen
und
Wahrscheinlichkeitsverteilungen mit Wahrscheinlichkeitsdichtefunktionen
und  ,
so ist
,
so ist
 .
.
Hierbei bezeichnet  die Faltung von
und
die Faltung von
und  und
und  die Faltung der Funktionen
und
die Faltung der Funktionen
und  .
Die Wahrscheinlichkeitsdichtefunktion der Faltung zweier
Wahrscheinlichkeitsverteilungen ist somit genau die Faltung der
Wahrscheinlichkeitsdichtefunktionen der Wahrscheinlichkeitsverteilungen.
.
Die Wahrscheinlichkeitsdichtefunktion der Faltung zweier
Wahrscheinlichkeitsverteilungen ist somit genau die Faltung der
Wahrscheinlichkeitsdichtefunktionen der Wahrscheinlichkeitsverteilungen.
Diese Eigenschaft überträgt sich direkt auf die Summe von
stochastisch
unabhängigen Zufallsvariablen. Sind zwei stochastisch unabhängige
Zufallsvariablen  mit Wahrscheinlichkeitsdichtefunktionen
und
mit Wahrscheinlichkeitsdichtefunktionen
und  gegeben, so ist
gegeben, so ist
 .
.
Die Wahrscheinlichkeitsdichtefunktion der Summe ist somit die Faltung der Wahrscheinlichkeitsdichtefunktionen der einzelnen Zufallsvariablen.
Bestimmung von Kennzahlen durch Wahrscheinlichkeitsdichtefunktionen
Viele der typischen Kennzahlen einer Zufallsvariablen beziehungsweise einer Wahrscheinlichkeitsverteilung lassen sich bei Existenz der Wahrscheinlichkeitsdichtefunktionen direkt aus dieser herleiten.
Modus
Der Modus
einer Wahrscheinlichkeitsverteilung bzw. Zufallsvariablen wird direkt über die
Wahrscheinlichkeitsdichtefunktion definiert. Ein  heißt ein Modus, wenn die Wahrscheinlichkeitsdichtefunktion
an der Stelle
heißt ein Modus, wenn die Wahrscheinlichkeitsdichtefunktion
an der Stelle  ein lokales
Maximum besitzt.
Das bedeutet, es ist
ein lokales
Maximum besitzt.
Das bedeutet, es ist
 für alle
für alle 
für ein  .
.
Selbstverständlich kann eine Wahrscheinlichkeitsdichtefunktion auch zwei oder mehrere lokale Maxima besitzen (bimodale Verteilungen und multimodale Verteilungen). Im Falle der Gleichverteilung im obigen Beispielabschnitt besitzt die Wahrscheinlichkeitsdichtefunktion sogar unendlich viele lokale Maxima.
Median
Der Median
wird gewöhnlicherweise über die Verteilungsfunktion
oder spezieller über die Quantilfunktion
definiert. Existiert eine Wahrscheinlichkeitsdichtefunktion, so ist ein
Median gegeben durch dasjenige  ,
für das
,
für das

und

gilt. Aufgrund der Stetigkeit der zugehörigen Verteilungsfunktion existiert
in diesem Fall
immer, ist aber im Allgemeinen nicht eindeutig.
Erwartungswert
Der Erwartungswert
einer Zufallsvariablen
mit Wahrscheinlichkeitsdichtefunktion
ist gegeben durch
 ,
,
falls das Integral existiert.
Varianz und Standardabweichung
Ist eine Zufallsvariable
mit Wahrscheinlichkeitsdichtefunktion
gegeben, und bezeichnet

den Erwartungswert der Zufallsvariablen, so ist die Varianz der Zufallsvariablen gegeben durch
 .
.
Alternativ gilt auch nach dem Verschiebungssatz
 .
.
Auch hier gelten die Aussagen wieder nur, wenn alle vorkommenden Integrale existieren. Die Standardabweichung lässt sich dann direkt als die Wurzel aus der Varianz berechnen.
Höhere Momente, Schiefe und Wölbung
Mittels der oben
angegebenen Vorschrift für nichtlineare Transformationen lassen sich auch
höhere Momente
direkt berechnen. So gilt für das k-te Moment einer Zufallsvariablen mit
Wahrscheinlichkeitsdichtefunktion

und für das k-te absolute Moment
 .
.
Bezeichnet  den Erwartungswert von ,
so ergibt sich für die zentralen
Momente
den Erwartungswert von ,
so ergibt sich für die zentralen
Momente

und die absoluten zentralen Momente
 .
.
Über die zentralen Momente können die Schiefe und die Wölbung der Verteilung direkt bestimmt werden, siehe die entsprechenden Hauptartikel.
Beispiel
Gegeben sei wieder die Wahrscheinlichkeitsdichtefunktion der
Exponentialverteilung zum Parameter ,
also
Ein Modus des Exponentialverteilung ist immer  .
Denn auf dem Intervall
.
Denn auf dem Intervall  ist die Wahrscheinlichkeitsdichtefunktion konstant gleich null, und auf dem
Intervall
ist die Wahrscheinlichkeitsdichtefunktion konstant gleich null, und auf dem
Intervall  ist sie streng
monoton fallend, somit ist an der Stelle 0 ein lokales Maximum. Aus der
Monotonie folgt dann auch direkt, dass es sich um das einzige lokale Maximum
handelt, der Modus ist also eindeutig bestimmt.
ist sie streng
monoton fallend, somit ist an der Stelle 0 ein lokales Maximum. Aus der
Monotonie folgt dann auch direkt, dass es sich um das einzige lokale Maximum
handelt, der Modus ist also eindeutig bestimmt.
Zur Bestimmung des Medians bildet man (da die Wahrscheinlichkeitsdichtefunktion links der Null verschwindet)
 .
.
Durch kurze Rechnung erhält man
 .
.
Dieses  erfüllt auch die zweite der beiden Gleichungen im obigen Abschnitt
Median und ist somit ein Median.
erfüllt auch die zweite der beiden Gleichungen im obigen Abschnitt
Median und ist somit ein Median.
Für den Erwartungswert erhält man unter Zuhilfenahme der partiellen Integration
 .
.
Analog lässt sich durch zweimaliges Anwenden der partiellen Integration die Varianz bestimmen.
Weitere Beispiele
Durch  für
für ![x \in [0,1]](/svg/64a15936df283add394ab909aa7a5e24e7fb6bb2.svg) sowie
sowie  für
für  und
für
und
für  ist eine Dichtefunktion
gegeben, denn
ist auf ganz
ist eine Dichtefunktion
gegeben, denn
ist auf ganz  nichtnegativ und es gilt
nichtnegativ und es gilt
 .
.
Für
gilt:

Die Verteilungsfunktion lässt sich schreiben als

Ist
eine Zufallsvariable mit der Dichte ,
so folgt daher beispielsweise
 .
.
Für den Erwartungswert von
ergibt sich
 .
.
Mehrdimensionale Zufallsvariablen
Wahrscheinlichkeitsdichten kann man auch für mehrdimensionale
Zufallsvariablen, also für Zufallsvektoren
definieren. Ist
eine  -wertige
Zufallsvariable, so
heißt eine Funktion
-wertige
Zufallsvariable, so
heißt eine Funktion  Wahrscheinlichkeitsdichte (bezüglich des Lebesgue-Maßes) der
Zufallsvariablen ,
falls gilt
Wahrscheinlichkeitsdichte (bezüglich des Lebesgue-Maßes) der
Zufallsvariablen ,
falls gilt

für alle Borelmengen
 .
.
Speziell folgt dann für  -dimensionale
Intervalle
-dimensionale
Intervalle ![I = [a_1,b_1] \times \dotsb \times [a_n,b_n]](/svg/c3e3c9526b37a5adcf397d440741549171f97235.svg) mit reellen Zahlen
mit reellen Zahlen  :
:
 .
.
Der Begriff der Verteilungsfunktion lässt sich ebenfalls auf mehrdimensionale
Zufallsvariablen erweitern. Hier ist in der Notation  das
das  ein Vektor und das
ein Vektor und das  -Zeichen
komponentenweise zu lesen.
ist also hierbei eine Abbildung von
in das Intervall [0,1] und es gilt
-Zeichen
komponentenweise zu lesen.
ist also hierbei eine Abbildung von
in das Intervall [0,1] und es gilt
 .
.
Wenn
n-mal stetig differenzierbar ist, erhält man eine Wahrscheinlichkeitsdichte
durch partielle Differentiation:

Die Dichten  der Komponentenvariablen
der Komponentenvariablen  lassen sich als Dichten der Randverteilungen
durch Integration über die übrigen Variablen berechnen.
lassen sich als Dichten der Randverteilungen
durch Integration über die übrigen Variablen berechnen.
Des Weiteren gilt: Ist  eine -wertige
Zufallsvariable mit Dichte, so sind äquivalent:
eine -wertige
Zufallsvariable mit Dichte, so sind äquivalent:
-
besitzt eine Dichte der Form
 ,
wobei
die reelle Wahrscheinlichkeitsdichte von
ist.
,
wobei
die reelle Wahrscheinlichkeitsdichte von
ist.
- Die Zufallsvariablen
 sind unabhängig.
sind unabhängig.
Schätzung einer Wahrscheinlichkeitsdichte anhand diskreter Daten
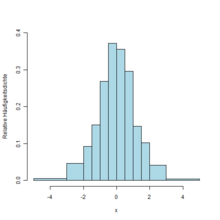
Diskret erfasste, aber eigentlich stetige Daten (beispielsweise die Körpergröße in Zentimetern) können als Häufigkeitsdichte repräsentiert werden. Das so erhaltene Histogramm ist eine stückweise konstante Schätzung der Dichtefunktion. Alternativ kann beispielsweise mit sogenannten Kerndichteschätzern die Dichtefunktion durch eine stetige Funktion geschätzt werden. Der dazu verwendete Kern sollte dem erwarteten Messfehler entsprechen.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 28.04. 2022