Chomsky-Hierarchie
Chomsky-Hierarchie, gelegentlich Chomsky-Schützenberger-Hierarchie (benannt nach dem Linguisten Noam Chomsky und dem Mathematiker Marcel Schützenberger), ist ein Begriff aus der Theoretischen Informatik. Sie ist eine Hierarchie von Klassen formaler Grammatiken, die formale Sprachen erzeugen, und wurde 1956 erstmals von Noam Chomsky beschrieben. Die Hierarchiestufen unterscheiden sich darin, wie rigide die Einschränkungen für die Form zulässiger Produktionsregeln auf der jeweiligen Stufe sind; bei Typ-0-Grammatiken sind sie uneingeschränkt, bei höheren Stufen fortschreitend stärker beschränkt.
Grammatiken niedrigeren Typs sind erzeugungsmächtiger als die höherer Typen. Eine Sprache, die von einer Grammatik des Typs k erzeugt wird, heißt eine Sprache des Typs k. Neben die Chomsky-Hierarchie der Grammatiken tritt in diesem Sinne eine Chomsky-Hierarchie der Sprachen.
Hintergründe
Formale Sprachen haben den Vorzug, mathematisch exakt analysiert werden zu
können. Formalen Sprachen liegt ein vorgegebenes Alphabet (ein
Zeichensatz) zugrunde, das häufig mit  bezeichnet wird. Beliebig lange, endliche Folgen von Elementen des Alphabets
werden als Wörter
über dem Alphabet bezeichnet. Mengen solcher Wörter sind schließlich formale
Sprachen. Die umfassendste formale Sprache über einem vorgegebenen Alphabet
ist unendlich groß; sie enthält sämtliche Wörter, die durch beliebiges
Zusammenfügen von Zeichen des Alphabets gebildet werden können. Sie lässt sich
durch die Kleenesche
Hülle des Alphabets beschreiben, also
bezeichnet wird. Beliebig lange, endliche Folgen von Elementen des Alphabets
werden als Wörter
über dem Alphabet bezeichnet. Mengen solcher Wörter sind schließlich formale
Sprachen. Die umfassendste formale Sprache über einem vorgegebenen Alphabet
ist unendlich groß; sie enthält sämtliche Wörter, die durch beliebiges
Zusammenfügen von Zeichen des Alphabets gebildet werden können. Sie lässt sich
durch die Kleenesche
Hülle des Alphabets beschreiben, also  .
Die kleinste formale Sprache enthält gar keine Wörter. Andere formale Sprachen
bestehen nur aus wenigen Wörtern und lassen sich somit als endliche Menge
notieren; beispielsweise für das Alphabet
.
Die kleinste formale Sprache enthält gar keine Wörter. Andere formale Sprachen
bestehen nur aus wenigen Wörtern und lassen sich somit als endliche Menge
notieren; beispielsweise für das Alphabet  die Sprache aller Wörter der Länge zwei:
die Sprache aller Wörter der Länge zwei:  .
.
Unendliche Sprachen lassen sich begreiflicherweise nicht durch Aufzählen notieren. Um sie exakt zu beschreiben, ist ein Konzept nötig, das auch unendliche Mengen definieren kann. Hierzu werden im Rahmen der formalen Sprachen vor allem Erzeugungsverfahren benutzt.
Geht man von einem vorhandenen Wort über einem Alphabet aus, lassen sich
durch Semi-Thue-Systeme
Wortmengen spezifizieren, die sich durch beliebig wiederholtes Anwenden von
Ersetzungsregeln ergeben. Ersetzungsregeln der Form  schreiben vor, dass in einem Wort, das ein Segment
schreiben vor, dass in einem Wort, das ein Segment  enthält, dieses Segment durch
enthält, dieses Segment durch  ersetzt wird. Semi-Thue-Systeme geben daher eine Ableitungsrelation
zwischen Wörtern formaler Sprachen an: Zwei Wörter stehen in Relation, wenn das
eine Wort durch eine Ersetzungsregel vom anderen Wort abgeleitet werden kann.
ersetzt wird. Semi-Thue-Systeme geben daher eine Ableitungsrelation
zwischen Wörtern formaler Sprachen an: Zwei Wörter stehen in Relation, wenn das
eine Wort durch eine Ersetzungsregel vom anderen Wort abgeleitet werden kann.
Zur Beschreibung von formalen Sprachen eignen sich formale
Grammatiken, ein gegenüber Semi-Thue-Systemen erweitertes und mächtigeres
Konzept. Sie unterscheiden sich von Semi-Thue-Systemen darin, dass sie
sogenannte Terminalsymbole
und Nichtterminalsymbole
kennen. Terminalsymbole einer Grammatik sind gerade alle Zeichen ihres
Zeichensatzes .
Die erste anwendbare Regel geht immer von einem nichtterminalen Startsymbol aus,
und das Ergebnis eines Ersetzungsvorgangs gilt nur dann als Wort ihrer formalen
Sprache, wenn es keine Nichtterminalsymbole enthält.
Das folgende Beispiel beschreibt eine Sprache, mit der sich beliebig lange
Summen der Ziffern 1, 2 und 3 ausdrücken lassen. Das dafür angemessene Alphabet
ist  .
Die entsprechenden Terminalsymbole sind unterstrichen dargestellt,
Nicht-Terminale kursiv. Die folgenden Zeilen stellen die Regeln dar.
.
Die entsprechenden Terminalsymbole sind unterstrichen dargestellt,
Nicht-Terminale kursiv. Die folgenden Zeilen stellen die Regeln dar.

Das Startsymbol dieser Sprache ist Summe. Davon ausgehend kann man nun beliebige Regeln nacheinander anwenden, um einen gültigen Ausdruck zu erzeugen:

Nicht alle unendlichen Sprachen lassen sich als formale Sprachen mit diesem Erzeugungsprinzip beschreiben, es ist aber kein tauglicheres Konzept bekannt. Ein anderer gängiger Formalismus zur Beschreibung von Sprachen sind Automatenmodelle, vor allem Turingmaschinen. Uneingeschränkte formale Grammatiken und Turingmaschinen sind bei der Beschreibung von formalen Sprachen gleichmächtig, d.h. zu jeder von einer formalen Grammatik erzeugten Sprache gibt es eine Turingmaschine, die genau diese akzeptiert, und umgekehrt.
Ebenso wie verschiedene Automatenmodelle definiert wurden, definierte Chomsky in seiner Arbeit verschiedene Grammatiktypen. Durch drei fortlaufend schärfere Einschränkungen an die jeweils darin zulässigen Ersetzungsregeln stellte er eine Hierarchie aus vier Klassen von formalen Grammatiken auf, wodurch die weniger eingeschränkten Klassen die stärker regulierten Klassen jeweils echt umfassen. Das Gleiche gilt für die von den jeweiligen Grammatikklassen beschriebenen Sprachklassen: auch sie bilden eine Hierarchie.
Sprachen eingeschränkteren Grammatiktyps sind üblicherweise einfacher algorithmisch zu verarbeiten – um den Preis, weniger ausdrucksmächtig zu sein. Reguläre Ausdrücke mit denen man etwa Muster für die Suche in Texten definiert, entsprechen zum Beispiel den sehr eingeschränkten Chomsky-Grammatiken des Typs 3 (reguläre Grammatiken) und solche Textsuchen sind effektiv und schnell. Dagegen taugen Grammatiken des Typs 3 wegen ihrer Einfachheit nicht zur Beschreibung von Programmiersprachen, für die man meist weniger eingeschränkte Typ-2-Grammatiken benutzt.
Die Hierarchie
Die Chomsky-Hierarchie umfasst vier Typen formaler Grammatiken, gezählt von 0 bis 3. Typ 0 umfasst alle formalen Grammatiken überhaupt, also ohne Einschränkung an die Gestalt zulässiger Erzeugungsregeln. Grammatiken des Typs 1 bis Typ 3 sind dann zunehmend stärker eingeschränkt. Allein nach Definition ist eine Grammatik vom Typ 1 auch vom Typ 0, eine Grammatik vom Typ 2 auch vom Typ 1, eine Grammatik vom Typ 3 auch vom Typ 2; die Umkehrungen gelten nicht. Deshalb bilden diese Klassen eine echte Hierarchie. Bei den entsprechenden Sprachklassen zeigen Gegenbeispiele, dass ebenfalls die Umkehrungen nicht gelten, weshalb auch sie eine echte Hierarchie bilden.
Chomsky forderte für Typ-1-, Typ-2- und Typ-3-Grammatiken, dass die rechte Seite von Produktionsregeln nicht kürzer als die linke Seite sein darf, was auch das leere Wort auf jeder rechten Seite einer Produktionsregel ausschließt. Heute ist man oft weniger restriktiv; die Definitionen sind oft so gefasst, dass die Hierarchie der Sprachen nicht gestört wird, sie es aber auch Grammatiken des Typs 1 (kontextsensitive Grammatiken) durch eine Ausnahmeregel erlauben, das leere Wort zu erzeugen, und den Typen 2 (kontextfreien Grammatiken) und 3 (regulären Grammatiken) sogar ohne Einschränkung das leere Wort als rechte Seite von Ersetzungsregeln gestatten.
Typ-0-Grammatik (allgemeine Chomsky-Grammatik oder Phrasenstrukturgrammatik)
Definition
Typ-0-Grammatiken werden auch unbeschränkte Grammatiken genannt. Es
handelt sich dabei um die Klasse aller formalen Grammatiken der Form 
 ,
wobei
,
wobei  ein Vokabular ist, bestehend aus der disjunkten
Vereinigung eines endlichen Alphabets
ein Vokabular ist, bestehend aus der disjunkten
Vereinigung eines endlichen Alphabets  (Terminalsymbole) und einer Menge von Nichtterminalen (Variablen)
(Terminalsymbole) und einer Menge von Nichtterminalen (Variablen)  .[1]
Das ausgezeichnete Symbol
.[1]
Das ausgezeichnete Symbol  wird als Startsymbol bezeichnet und
wird als Startsymbol bezeichnet und  ist eine Menge von Produktionsregeln
ist eine Menge von Produktionsregeln 




 ,
d.h. auf der linken Seite jeder Produktionsregel steht wenigstens ein
Nicht-Terminalsymbol. Für einzelne Regeln schreibt man anstelle von
,
d.h. auf der linken Seite jeder Produktionsregel steht wenigstens ein
Nicht-Terminalsymbol. Für einzelne Regeln schreibt man anstelle von  meistens ,
für die Menge der Regeln mit
auf der linken Seite
meistens ,
für die Menge der Regeln mit
auf der linken Seite  auch
auch  .
.
Um die Zugehörigkeit zur Klasse der Typ-0-Grammatiken auszudrücken, schreibt
man 
Von Typ-0-Grammatiken erzeugte Sprachen
Jede Typ-0-Grammatik erzeugt eine Sprache, die von einer Turingmaschine akzeptiert werden kann, und umgekehrt existiert für jede Sprache, die von einer Turingmaschine akzeptiert werden kann, eine Typ-0-Grammatik, die diese Sprache erzeugt. Diese Sprachen sind auch bekannt als die rekursiv aufzählbaren Sprachen (oft auch semi-entscheidbare Sprachen genannt), d.h. die zugehörige Turingmaschine akzeptiert jedes Wort, das in der Sprache liegt. Bei einem Wort, das nicht in der Sprache liegt, kann es sein, dass die Turingmaschine nicht terminiert, d.h. keinerlei Auskunft über die Zugehörigkeit des Worts zur Sprache liefert.
Man beachte, dass sich diese Menge von Sprachen von der Menge der rekursiven Sprachen (oft auch entscheidbare Sprachen genannt) unterscheidet, welche durch Turingmaschinen entschieden werden können.
Typ-1-Grammatik (kontextsensitive Grammatik)
Definition
Typ-1-Grammatiken werden auch kontextsensitive Grammatiken genannt. Es
handelt sich dabei um Typ-0-Grammatiken, bei denen alle Produktionsregeln die
Form  oder
oder  haben, wobei
haben, wobei  ein Nichtterminal und
ein Nichtterminal und  Wörter bestehend aus Terminalen ()
und Nichtterminalen ()
sind.
Wörter bestehend aus Terminalen ()
und Nichtterminalen ()
sind.  bezeichnet das leere Wort. Die Wörter
und
können leer sein, aber
bezeichnet das leere Wort. Die Wörter
und
können leer sein, aber  muss mindestens ein Symbol (also ein Terminal oder ein Nichtterminal) enthalten.
Diese Eigenschaft wird Längenbeschränktheit genannt.
muss mindestens ein Symbol (also ein Terminal oder ein Nichtterminal) enthalten.
Diese Eigenschaft wird Längenbeschränktheit genannt.
Als einzige Ausnahme von dieser Forderung lässt man
zu, wenn das Startsymbol nirgends auf der rechten Seite einer Produktion
auftritt. Damit erreicht man, dass die kontextsensitiven Sprachen auch das oft
erwünschte leere Wort enthalten können, das dann aber immer nur in einer
einschrittigen Ableitung aus dem Startsymbol selbst entsteht, und ohne für alle
anderen Ableitungen die Eigenschaft zu stören, dass in jedem Teilschritt die Satzform
länger wird oder gleich lang bleibt.
Ist eine Grammatik  kontextsensitiv, so schreibt man
kontextsensitiv, so schreibt man  .
.
Anders als bei kontextfreien Grammatiken können auf der linken Seite der Produktionen kontextsensitiver Grammatiken durchaus statt einzelner Symbole ganze Symbolfolgen stehen, sofern sie mindestens ein Nichtterminalsymbol enthalten.
Von Typ-1-Grammatiken erzeugte Sprachen
Die kontextsensitiven Grammatiken erzeugen genau die kontextsensitiven Sprachen. Das heißt: Jede Typ-1-Grammatik erzeugt eine kontextsensitive Sprache und zu jeder kontextsensitiven Sprache existiert eine Typ-1-Grammatik, die diese erzeugt.
Die kontextsensitiven Sprachen sind genau die Sprachen, die von einer nichtdeterministischen,
linear
beschränkten Turingmaschine erkannt werden können; das heißt von einer
nichtdeterministischen Turingmaschine, deren Band linear durch die Länge der
Eingabe beschränkt ist (das bedeutet, es gibt eine konstante Zahl  ,
sodass das Band der Turingmaschine höchstens
,
sodass das Band der Turingmaschine höchstens  Felder besitzt, wobei
Felder besitzt, wobei  die Länge des Eingabewortes ist).
die Länge des Eingabewortes ist).
Monotone Grammatiken
Einige Autoren bezeichnen eine Grammatik schon dann als kontextsensitiv, wenn
bis auf die Ausnahme
(s.o.) alle Produktionsregeln  nur die Bedingung
nur die Bedingung  erfüllen, d.h., dass die rechte Seite einer solchen Produktion nicht
kürzer als deren linke Seite ist. Häufiger findet man dafür jedoch den Begriff
der monotonen
Grammatik oder der nichtverkürzenden Grammatik.
erfüllen, d.h., dass die rechte Seite einer solchen Produktion nicht
kürzer als deren linke Seite ist. Häufiger findet man dafür jedoch den Begriff
der monotonen
Grammatik oder der nichtverkürzenden Grammatik.
Es erweist sich, dass die monotonen Grammatiken genau wieder die kontextsensitiven Sprachen erzeugen, weshalb die beiden Klassen von Grammatiken als äquivalent betrachtet werden und manche Autoren nur die eine oder die andere Grammatikklasse überhaupt behandeln. Aber nicht jede monotone Ersetzungsregel ist auch eine kontextsensitive, deshalb ist auch nicht jede monotone Grammatik eine kontextsensitive.
Typ-2-Grammatik (kontextfreie Grammatik)
Definition
Typ-2-Grammatiken werden auch kontextfreie Grammatiken genannt. Es
sind Grammatiken, für die gelten muss:  In jeder Regel der Grammatik muss also auf der linken Seite genau ein
nicht-terminales Symbol stehen und auf der rechten Seite kann eine beliebige
nicht-leere Folge von terminalen und nichtterminalen Symbolen aus dem gesamten
Vokabular
In jeder Regel der Grammatik muss also auf der linken Seite genau ein
nicht-terminales Symbol stehen und auf der rechten Seite kann eine beliebige
nicht-leere Folge von terminalen und nichtterminalen Symbolen aus dem gesamten
Vokabular  stehen.
stehen.
Außerdem kann wie bei Typ-1-Grammatiken die Ausnahmeregel
zugelassen werden, wenn  auf keiner rechten Seite einer Regel vorkommt.
auf keiner rechten Seite einer Regel vorkommt.
Man schreibt 
Kontextfreie Grammatiken werden oft so definiert, dass die rechte Seite auch
leer sein darf, also  .
Solche Grammatiken erfüllen nicht mehr alle Eigenschaften von Typ-2-Grammatiken
und stünden nicht mehr in der von Chomsky definierten Hierarchie. Sie erfüllen
aber die Bedingungen von monotonen Grammatiken.
.
Solche Grammatiken erfüllen nicht mehr alle Eigenschaften von Typ-2-Grammatiken
und stünden nicht mehr in der von Chomsky definierten Hierarchie. Sie erfüllen
aber die Bedingungen von monotonen Grammatiken.
Von Typ-2-Grammatiken erzeugte Sprachen
Kontextfreie Grammatiken (mit -Ausnahmeregel)
erzeugen genau die kontextfreien
Sprachen, jede Typ-2-Grammatik erzeugt also eine kontextfreie Sprache und zu
jeder kontextfreien Sprache existiert eine Typ-2-Grammatik, die diese erzeugt.
Die kontextfreien Sprachen sind genau die Sprachen, die von einem nichtdeterministischen Kellerautomaten (NPDA) erkannt werden können. Eine Teilmenge dieser Sprachen bildet die theoretische Basis für die Syntax der meisten Programmiersprachen.
Siehe auch: Backus-Naur-Form (BNF): ein anderes, äquivalentes Schema der Bezeichnungsweisen.
Typ-3-Grammatik (reguläre Grammatik)
Definition
Typ-3-Grammatiken werden auch reguläre Grammatiken genannt. Es handelt sich um Typ-2-Grammatiken, bei denen auf der rechten Seite von Produktionen genau ein Terminalsymbol auftreten darf und maximal ein weiteres Nichtterminalsymbol. Die erlaubte Stellung solcher Nichtterminalsymbole muss außerdem über alle Produktionen hinweg einheitlich immer vor oder immer hinter dem Terminalsymbol sein, je nachdem spricht man auch genauer von linksregulären und rechtsregulären Grammatiken. Sie stimmen mit den links- beziehungsweise rechts-linearen Grammatiken überein, wohingegen lineare Grammatiken nicht den regulären Grammatiken entsprechen.
Für linksreguläre Typ-3-Grammatiken muss also die Bedingung erfüllt sein, dass

 .
.
Sie dürfen also nur linksreguläre Produktionen (Nichtterminalsymbol auf der rechten Seite in Vorderstellung) enthalten.
Üblicherweise gestattet man für reguläre Grammatiken, wie auch für
kontextfreie Grammatiken Regeln mit leerer rechter Seite, also .
Rechtsreguläre Grammatiken erfüllen dagegen die analoge Bedingung
 .
.
Diese enthalten also nur rechtsreguläre Produktionen (Nichtterminalsymbol auf der rechten Seite allenfalls in Hinterstellung). Diese Bedingung drückt auch schon die Erlaubnis leerer rechter Seiten aus.
Linksreguläre und rechtsreguläre Grammatiken erzeugen genau dieselbe Sprachklasse, es gibt also zu jeder linksregulären Grammatik auch eine rechtsreguläre, die dieselbe Sprache erzeugt, und umgekehrt.
Man beachte, dass beim Auftreten von linksregulären und rechtsregulären Produktionen in ein und derselben Chomsky-Grammatik diese nicht regulär ist. Die Grammatiken mit sowohl linksregulären als auch rechtsregulären Produktionen erzeugen nämlich eine echt größere Sprachklasse.
Manche Autoren erlauben in den Definitionen für reguläre / linksreguläre / rechtsreguläre Grammatiken überall dort, wo hier in Produktionen nur ein einzelnes Nichtterminalzeichen stehen darf, auch eine beliebige nichtleere terminale Zeichenkette. An der Erzeugungsmächtigkeit der Klassen ändert sich dadurch nichts.
Man schreibt  für reguläre Grammatiken .
für reguläre Grammatiken .
Von Typ-3-Grammatiken erzeugte Sprachen
Reguläre Grammatiken erzeugen genau die regulären Sprachen, das heißt, jede Typ-3-Grammatik erzeugt eine reguläre Sprache und zu jeder regulären Sprache existiert eine Typ-3-Grammatik, die diese erzeugt.
Reguläre Sprachen können alternativ auch durch reguläre Ausdrücke beschrieben werden und die regulären Sprachen sind genau die Sprachen, die von endlichen Automaten erkannt werden können. Sie werden häufig genutzt, um Suchmuster oder die lexikalische Struktur von Programmiersprachen zu definieren.
Übersicht>
Die folgende Tabelle führt für die vier Grammatiktypen auf, welche Form ihre Regeln haben, welchen Namen die erzeugten Sprachen haben und welche Automatentypen diese Sprachen erkennen, also das Wortproblem zumindest semi-entscheiden (Wort in Sprache: Maschine hält in akzeptierendem Endzustand, Wort nicht in Sprache: Maschine hält nie oder hält in nicht akzeptierendem Zustand → sicher hält die Maschine also nur, wenn das Wort in der Sprache ist). Da in der Chomsky-Hierarchie für die Sprachmengen aber eine echte Teilmengenbeziehung gilt (siehe nächster Abschnitt) entscheiden z.B. Turingmaschinen selbstverständlich ebenfalls das Wortproblem für Sprachen vom Typ 1 bis 3. (entscheiden heißt: Wort in Sprache: Maschine hält in akzeptierendem Endzustand, Wort nicht in Sprache: Maschine hält in nicht akzeptierendem Zustand → irgendwann hält die Maschine und das Problem (Wort in Sprache?) ist entschieden) Außerdem wird vermerkt, gegenüber welchen Operationen die erzeugten Sprachen abgeschlossen sind.
| Grammatik | Regeln | Sprachen | Entscheidbarkeit | Automaten | Abgeschlossenheit | Zeitabschätzung |
|---|---|---|---|---|---|---|
| Typ-0 Beliebige formale Grammatik |
|
rekursiv aufzählbar (nicht „nur“ rekursiv, die wären entscheidbar!) | – | Turingmaschine (egal ob deterministisch oder nicht-deterministisch) | 
|
unbeschränkt |
| Typ-1 Kontextsensitive Grammatik |
|
kontextsensitiv | Wortproblem | linear platzbeschränkte nichtdeterministische Turingmaschine | 
|

|
| Typ-2 Kontextfreie Grammatik |
 |
kontextfrei | Wortproblem,
Leerheitsproblem, Endlichkeitsproblem |
nichtdeterministischer Kellerautomat | 
|

|
| Typ-3 Reguläre Grammatik |
 (rechtsregulär) oder
(rechtsregulär) oder (linksregulär)
(linksregulär)   Nur links- oder nur rechtsreguläre Produktionen |
regulär | Wortproblem,
Leerheitsproblem, Endlichkeitsproblem, Äquivalenzproblem |
Endlicher Automat (egal ob deterministisch oder nicht-deterministisch) |
|

|


 in
in 
- Legende für die Spalte Regeln
-
… endliches Alphabet (Menge der Terminalsymbole, oft auch mit
bezeichnet, das aber auch
 bedeuten kann)
bedeuten kann) -
… die davon disjunkte Menge der
Nichtterminalsymbole (gelegentlich auch Variablen genannt und mit
 bezeichnet, statt
bezeichnet, statt  … gesamtes Vokabular)
… gesamtes Vokabular) -
… Startsymbol
-
… leeres Wort (oft auch mit
 bezeichnet)
bezeichnet) -
… Menge von Produktionsregeln
(als Teilmenge eines kartesischen
Produkts eine Relation)
 … Mengen-Differenzbildung
… Mengen-Differenzbildung … Kleenescher Abschluss (Hülle), siehe Kleenesche
und positive Hülle
… Kleenescher Abschluss (Hülle), siehe Kleenesche
und positive Hülle … positive Hülle, z.B. meint
… positive Hülle, z.B. meint  …
muss mindestens ein Symbol (Terminal oder ein Nichtterminal) enthalten
…
muss mindestens ein Symbol (Terminal oder ein Nichtterminal) enthalten
In der obigen Tabelle werden somit mit lateinischen Großbuchstaben
Nichtterminalsymbole dargestellt,  mit lateinischen Kleinbuchstaben Terminalsymbole
mit lateinischen Kleinbuchstaben Terminalsymbole  und griechische Kleinbuchstaben werden verwendet, wenn es sich sowohl um
Nichtterminal als auch um Terminalsymbole handeln kann.
und griechische Kleinbuchstaben werden verwendet, wenn es sich sowohl um
Nichtterminal als auch um Terminalsymbole handeln kann.
Achtung: Bei
und
kann ein griechischer Kleinbuchstabe für Wörter aus mehreren Terminal- oder
Nichtterminalsymbolen stehen!
- Legende für die Spalte Abgeschlossenheit
 … Komplementbildung
… Komplementbildung … Konkatenation
… Konkatenation … Schnittmenge
… Schnittmenge … Vereinigungsmenge
… Vereinigungsmenge-
… Kleenescher
Abschluss (Hülle)
Chomsky-Hierarchie für formale Sprachen
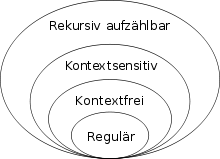
Eine formale Sprache ist vom Typ  entsprechend der Hierarchie für Grammatiken, wenn es von einer Typ--Grammatik
erzeugt wird. Formal ausgedrückt heißt das:
entsprechend der Hierarchie für Grammatiken, wenn es von einer Typ--Grammatik
erzeugt wird. Formal ausgedrückt heißt das:  ist vom Typ
ist vom Typ  falls es eine Grammatik
falls es eine Grammatik  mit
mit  gibt. Man schreibt dann
gibt. Man schreibt dann 
In der Chomsky-Hierarchie für formale Sprachen besteht zwischen den Sprachmengen benachbarter Ebenen eine echte Teilmengenbeziehung. Jede kontextsensitive Sprache ist rekursiv aufzählbar, aber es gibt rekursiv aufzählbare Sprachen, die nicht kontextsensitiv sind. Ebenso ist jede kontextfreie Sprache auch kontextsensitiv, aber nicht umgekehrt, und jede reguläre Sprache ist kontextfrei, aber nicht jede kontextfreie Sprache ist regulär.
Formal ausgedrückt bedeutet dies für die Klassen der durch die obigen
Grammatiken erzeugten Sprachen:  wobei gelegentlich auch folgende Symbole verwendet werden:
wobei gelegentlich auch folgende Symbole verwendet werden: 
Beispiele für Sprachen in den jeweiligen Differenzmengen sind:
 ist vom Typ 1, aber nicht vom Typ 2
ist vom Typ 1, aber nicht vom Typ 2 ist vom Typ 2, aber nicht vom Typ 3
ist vom Typ 2, aber nicht vom Typ 3
Beweise für die Nichtzugehörigkeit bestimmter Sprachen zu den Sprachklassen
 und
und  wie hier werden oft mit dem Schleifensatz
geführt.
wie hier werden oft mit dem Schleifensatz
geführt.
Natürliche Sprachen
Obwohl Chomsky seine Forschungen mit dem Ziel verfolgte, eine mathematische Beschreibung der natürlichen Sprachen zu finden, ist bis heute für keine natürliche Sprache der Nachweis einer korrekten und vollständigen formalen Grammatik gelungen. Das Problem besteht u.a. im Zusammenspiel der verschiedenen Grammatikteile, die jeweils einzelne sprachliche Phänomene modellieren. Aber auch beim praktischen Einsatz formaler Grammatiken in der Computerlinguistik kann es zu Mehrdeutigkeiten auf verschiedenen Ebenen der Sprachbetrachtung kommen; diese müssen (z.B. in der maschinellen Übersetzung) anhand des Kontextes aufgelöst werden.
Literatur
- Noam Chomsky: Three models for the description of language. In: IRE Transactions on Information Theory. Vol.2, 1956, S. 113–124
- Peter Sander, Wolffried Stucky, Rudolf Herschel: Automaten, Sprachen, Berechenbarkeit. Teubner, Stuttgart 1992, ISBN 3-519-02937-5.
Anmerkungen
- ↑
Im Zusammenhang mit formalen Grammatiken wird
hier für das ‚Zielalphabet’ der Terminalsymbole das Zeichen
statt - wie sonst -
verwendet. Achtung: Manche Autoren bezeichnen mit
abweichend das Gesamtvokabular
 (hier mit
bezeichnet).
(hier mit
bezeichnet).


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 24.09. 2023