Lineare Optimierung
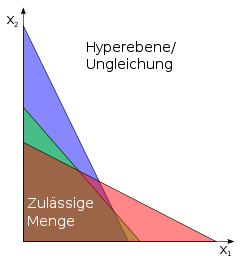
Die lineare Optimierung oder lineare Programmierung ist eines der Hauptverfahren des Operations Research und beschäftigt sich mit der Optimierung linearer Zielfunktionen über einer Menge, die durch lineare Gleichungen und Ungleichungen eingeschränkt ist. Häufig lassen sich lineare Programme (LPs) zur Lösung von Problemen einsetzen, für die keine speziell entwickelten Lösungsverfahren bekannt sind, beispielsweise bei der Planung von Verkehrs- oder Telekommunikationsnetzen oder in der Produktionsplanung. Die lineare Optimierung ist ein Spezialfall der konvexen Optimierung und Grundlage mehrerer Lösungsverfahren in der ganzzahligen linearen und der nichtlinearen Optimierung. Viele Eigenschaften linearer Programme lassen sich als Eigenschaften von Polyedern interpretieren und auf diese Art geometrisch modellieren und beweisen.
Der Begriff „Programmierung“ ist eher im Sinne von „Planung“ zu verstehen als im Sinne der Erstellung eines Computerprogramms. Er wurde schon Mitte der 1940er-Jahre von George Dantzig, einem der Begründer der linearen Optimierung, geprägt, bevor Computer zur Lösung linearer Optimierungsprobleme eingesetzt wurden.
Aus komplexitätstheoretischer Sicht ist die lineare Optimierung ein einfaches Problem, da es sich beispielsweise mit einigen Innere-Punkte-Verfahren in polynomialer Zeit lösen lässt. In der Praxis hat sich allerdings das Simplex-Verfahren als einer der schnellsten Algorithmen herausgestellt, obwohl es im schlechtesten Fall exponentielle Laufzeit besitzt. Neben dem eigentlichen Problem löst es immer auch das sogenannte duale Problem mit, was unter anderem in mehreren Verfahren zur Lösung ganzzahliger linearer Programme ausgenutzt wird.
Geschichte
Die Methode der linearen Optimierung wurde 1939 von dem sowjetischen Mathematiker Leonid Witaljewitsch Kantorowitsch in seinem Aufsatz „Mathematische Methoden für die Organisation und Planung der Produktion“ eingeführt. Kurz danach veröffentlichte der Amerikaner Frank L. Hitchcock eine Arbeit zu einem Transportproblem. Damals erkannte man noch nicht die Bedeutung dieser Arbeiten. Unter anderem für seinen Beitrag zur linearen Optimierung bekam Kantorowitsch aber 1975 den Nobelpreis für Wirtschaftswissenschaften.
Mitte der 1940er-Jahre erkannte George Dantzig, dass sich viele praktische Beschränkungen durch lineare Ungleichungen beschreiben ließen, und ersetzte erstmals die bis dahin vorherrschenden Faustregeln zur Lösung von Planungsproblemen durch eine (lineare) Zielfunktion. Insbesondere etablierte er damit eine klare Trennung zwischen dem Ziel der Optimierung und den Mitteln zur Lösung des Planungsproblems.
Den Durchbruch für die lineare Optimierung schaffte Dantzig 1947, als er eine Arbeit über das Simplex-Verfahren veröffentlichte, das heute eines der meistgenutzten Verfahren zur Lösung linearer Programme ist. Interesse an dieser Arbeit zeigten zunächst die amerikanischen Militärs, speziell die US Air Force, die militärische Einsätze optimieren wollten. In den Folgejahren entwickelten Dantzig, John von Neumann, Oskar Morgenstern, Tjalling Koopmans und andere das Verfahren und die zugehörige Theorie weiter und stellten Zusammenhänge zur Spieltheorie her. Mit dem Aufkommen von Computern Mitte der 1950er-Jahre konnte man auch größere Probleme lösen. Etwa ab 1950 entdeckte die Wirtschaft, insbesondere Ölraffinerien, die Anwendungsmöglichkeiten der linearen Optimierung. Ab den 1970er-Jahren profitierte der Simplex-Algorithmus von algorithmischen Fortschritten der numerischen linearen Algebra. Insbesondere die Entwicklung numerisch stabiler LR-Zerlegungen zur Lösung großer linearer Gleichungssysteme trugen maßgeblich zum Erfolg und der Verbreitung des Simplex-Verfahrens bei.
Im Jahre 1979 veröffentlichte Leonid Khachiyan die Ellipsoidmethode, mit der lineare Programme erstmals – zumindest theoretisch – in Polynomialzeit gelöst werden konnten. 1984 begannen Narendra Karmarkar und andere mit der Entwicklung von Innere-Punkte-Verfahren zur Lösung linearer Programme. Diese Algorithmen, die als erste polynomiale Lösungsmethoden auch das Potential zum praktischen Einsatz hatten, wurden innerhalb des nachfolgenden Jahrzehnts noch wesentlich verbessert. Parallel dazu wuchs die Bedeutung des Simplex-Verfahrens zur Lösung von Unterproblemen in der ganzzahligen linearen Optimierung. Anfang der 1990er-Jahre wurden hier noch einmal große Fortschritte durch die Entwicklung neuer Pivotstrategien für den dualen Simplex-Algorithmus erzielt, insbesondere durch das dual steepest edge pricing von John Forrest und Donald Goldfarb.
Sowohl das Simplex-Verfahren als auch verschiedene Innere-Punkte-Verfahren sind nach wie vor Gegenstand aktueller Forschung. Die lineare Optimierung wird heute in sehr vielen Bereichen zur Lösung praktischer Probleme eingesetzt. Unter der in praktischen Anwendungen fast immer erfüllten Voraussetzung, dass die auftretenden LP-Matrizen dünnbesetzt sind (also nur wenige Nicht-Null-Einträge besitzen), können heute lineare Programme mit mehreren hunderttausend Variablen oder Ungleichungen innerhalb weniger Minuten bis Stunden optimal gelöst werden. Die tatsächliche Lösungszeit hängt dabei neben dem verwendeten Lösungsverfahren auch stark von der Anzahl und Anordnung der Nicht-Null-Einträge in der beteiligten Matrix und von der Wahl der Startlösung ab.
Problemdefinition
Mathematische Formulierung
Bei einem linearen Programm (LP) sind eine Matrix  und zwei Vektoren
und zwei Vektoren  und
und  gegeben. Eine zulässige Lösung ist ein Vektor
gegeben. Eine zulässige Lösung ist ein Vektor  mit nichtnegativen Einträgen, der die linearen Bedingungen
mit nichtnegativen Einträgen, der die linearen Bedingungen

erfüllt. Ziel ist es, unter allen zulässigen Vektoren  einen zu finden, der das Standardskalarprodukt
einen zu finden, der das Standardskalarprodukt

maximiert. Dieses Optimierungsproblem in der sogenannten Standardform wird oft abkürzend als

geschrieben, wobei die Bedingungen  und
und  komponentenweise zu verstehen sind.
komponentenweise zu verstehen sind.
Darüber hinaus gibt es noch weitere äquivalente Formulierungen, die sich durch einfache Operationen in diese Standardform bringen lassen:
- Minimierungsproblem statt Maximierungsproblem: Multiplikation des
Zielfunktionsvektors
 mit
mit 
- Größer-gleich- statt Kleiner-gleich-Bedingungen: Multiplikation der
entsprechenden Ungleichungen mit
- Gleichheitsbedingungen statt Ungleichheitsbedingungen: Ersetzung von
 durch
durch  und
und 
- Variablen ohne Nichtnegativitätsbedingung: Ersetzung von
durch
 mit
mit 
Die lineare Optimierung behandelt nur Probleme, bei denen die Variablen beliebige reelle Zahlen annehmen dürfen. Ein (gemischt-)ganzzahliges lineares Programm, bei dem einige Variablen nur ganzzahlige Werte annehmen dürfen, ist kein Spezialfall, sondern – im Gegenteil – eine Verallgemeinerung. Solche Optimierungsprobleme sind im Allgemeinen NP-äquivalent, d.h. vermutlich nicht effizient lösbar. Dieser Fall wird von der ganzzahligen linearen Optimierung behandelt.
Geometrische Interpretation
Ein lineares Programm lässt sich geometrisch interpretieren. Wenn
die i. Zeile eines linearen Programms in Standardform ist, dann beschreibt die
Menge  aller Punkte ,
die die zugehörige lineare Gleichung
erfüllen, eine Hyperebene
im
aller Punkte ,
die die zugehörige lineare Gleichung
erfüllen, eine Hyperebene
im  -dimensionalen
Raum. Die Menge der Punkte, die die lineare Ungleichung
erfüllen, besteht aus allen Punkten auf der einen Seite der Hyperebene
(inklusive der Hyperebene selbst), bildet also einen Halbraum.
Jede Zeile
teilt daher den -dimensionalen
Raum in zwei Hälften, wobei die Punkte in der einen Hälfte zulässig sind und in
der anderen nicht. Die Menge
-dimensionalen
Raum. Die Menge der Punkte, die die lineare Ungleichung
erfüllen, besteht aus allen Punkten auf der einen Seite der Hyperebene
(inklusive der Hyperebene selbst), bildet also einen Halbraum.
Jede Zeile
teilt daher den -dimensionalen
Raum in zwei Hälften, wobei die Punkte in der einen Hälfte zulässig sind und in
der anderen nicht. Die Menge

der Punkte, die alle Ungleichungen des LPs erfüllen, ist genau der Schnitt
dieser Halbräume, also die Menge aller Punkte, die für jede Ungleichung in der
jeweiligen zulässigen Hälfte des Raumes liegen. Diese Lösungsmenge  des linearen Programms bildet ein konvexes
Polyeder,
also ein -dimensionales
Vieleck, in dem die Verbindungslinie zwischen zwei beliebigen Punkten von
vollständig in
enthalten ist. Ziel der Optimierung ist es, unter allen Punkten des Polyeders
einen zu finden, der die lineare Funktion
des linearen Programms bildet ein konvexes
Polyeder,
also ein -dimensionales
Vieleck, in dem die Verbindungslinie zwischen zwei beliebigen Punkten von
vollständig in
enthalten ist. Ziel der Optimierung ist es, unter allen Punkten des Polyeders
einen zu finden, der die lineare Funktion  maximiert. Geometrisch entspricht dies der Verschiebung der Hyperebene
maximiert. Geometrisch entspricht dies der Verschiebung der Hyperebene  in Richtung des Vektors ,
bis die verschobene Hyperebene das Polyeder gerade noch berührt.
Die Menge aller Berührungspunkte ist genau die Menge der Optimallösungen des
linearen Programms.
in Richtung des Vektors ,
bis die verschobene Hyperebene das Polyeder gerade noch berührt.
Die Menge aller Berührungspunkte ist genau die Menge der Optimallösungen des
linearen Programms.
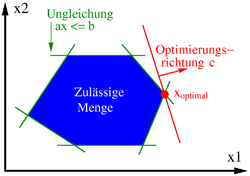
Im nebenstehenden Bild ist diese Anordnung für den Fall von nur zwei
Variablen dargestellt. Eine Hyperebene im zweidimensionalen Raum ist eine Gerade, im Bild
grün dargestellt. Jede dieser Geraden teilt den Raum in eine zulässige und eine
unzulässige Hälfte. Die Menge der Punkte, die auf der zulässigen Seite jeder
Geraden liegen, bilden das blau dargestellte Polyeder (Vieleck). Die rote Gerade
stellt die Zielfunktion dar. Ziel ist es, sie so weit wie möglich in Richtung
des roten Vektors
zu verschieben, ohne das Polyeder zu verlassen. Im nebenstehenden Bild ist der
rote Berührungspunkt der Zielfunktionsgeraden mit dem Polyeder die einzige
Optimallösung.
Beispiel aus der Produktionsplanung (zweidimensional)
Ein Unternehmen stellt zwei verschiedene Produkte her, für deren Fertigung drei Maschinen A, B, C zur Verfügung stehen. Diese Maschinen haben eine maximale monatliche Laufzeit (Kapazität) von 170 Stunden (A), 150 Stunden (B) bzw. 180 Stunden (C). Eine Mengeneinheit (ME) von Produkt 1 liefert einen Deckungsbeitrag von 300 Euro, eine ME von Produkt 2 dagegen 500 Euro. Fertigt man eine ME von Produkt 1, dann benötigt man dafür eine Stunde die Maschine A und eine Stunde die Maschine B. Eine Einheit von Produkt 2 belegt zwei Stunden lang Maschine A, eine Stunde Maschine B und drei Stunden Maschine C. Ziel ist es, Produktionsmengen zu bestimmen, die den Deckungsbeitrag des Unternehmens maximieren, ohne die Maschinenkapazitäten zu überschreiten. Fixkosten können in dem Optimierungsproblem ignoriert und anschließend dazuaddiert werden, da sie per Definition unabhängig von den zu bestimmenden Produktionsmengen sind.
Mathematische Modellierung
Angenommen, der Betrieb fertigt pro Monat  ME von Produkt 1 und
ME von Produkt 1 und  ME von Produkt 2. Dann beträgt der Gesamtdeckungsbeitrag
ME von Produkt 2. Dann beträgt der Gesamtdeckungsbeitrag

Diesen Wert möchte das Unternehmen maximieren. Da die Maschinenkapazitäten eingehalten werden müssen, ergeben sich die Nebenbedingungen:

Da außerdem keine negativen Produktionsmengen möglich sind, muss  gelten (Nichtnegativitätsbedingung).
gelten (Nichtnegativitätsbedingung).
Geometrische Interpretation als Polyeder
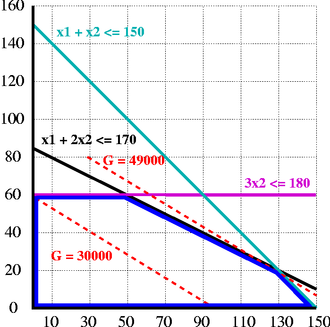
Im nebenstehenden Bild sind die Ungleichungen aus dem obigen Beispiel als türkise, schwarze und violette Beschränkungen eingezeichnet. Zusammen definieren sie das (blau umrandete) Polyeder der zulässigen Punkte. Die rotgestrichelten Linien stellen Iso-Gewinnfunktionen dar, d.h., alle Punkte auf einer solchen Linie haben denselben Zielfunktionswert. Da das Unternehmen möglichst viel Gewinn erzielen will, ist das Ziel der Optimierung, solch eine rot gestrichelte Linie so weit nach rechts oben zu schieben, dass sie gerade noch das Polyeder berührt. Alle Berührungspunkte sind dann optimal. In diesem Fall ist der Punkt (130,20) die eindeutige optimale Ecke, und der optimale Zielfunktionswert beträgt 49.000 Euro.
Im Allgemeinen ist die Optimallösung eines linearen Optimierungsproblems
allerdings weder eindeutig noch ganzzahlig. Wenn beispielsweise beide Produkte
den gleichen Deckungsbeitrag hätten, wären die roten Iso-Gewinnfunktionen
parallel zur Ungleichung  .
In diesem Fall wäre jeder Punkt auf der Strecke zwischen (130,20) und (150,0)
optimal, es gäbe also unendlich viele Optimallösungen.
.
In diesem Fall wäre jeder Punkt auf der Strecke zwischen (130,20) und (150,0)
optimal, es gäbe also unendlich viele Optimallösungen.
Anwendungen
Die lineare Optimierung hat viele Anwendungen in der Praxis, von denen hier einige beispielhaft vorgestellt werden sollen.
Produktionsplanung
Wie in dem obigen Beispiel kann ein Unternehmen eine Reihe von Produkten mit bekanntem Deckungsbeitrag herstellen. Die Herstellung einer Einheit jedes dieser Produkte benötigt eine bekannte Menge an beschränkten Ressourcen (Produktionskapazität, Rohmaterialien, Arbeitszeit etc). Die Aufgabe ist die Erstellung eines Produktionsprogramms, d.h. die Festlegung, wie viel von jedem Produkt produziert werden soll, so dass der Gewinn des Unternehmens maximiert wird, ohne die Ressourcenbeschränkungen zu verletzen. Ein weiteres Beispiel sind Zuschnittsprobleme.
Mischungsprobleme
Eine ähnliche Anwendung sind Mischungsprobleme, bei denen es darum geht, Zutaten zu einem Endprodukt zusammenzustellen, wobei die Menge der jeweiligen Zutaten innerhalb eines bestimmten Bereichs variiert werden kann. Ein Beispiel hierfür ist das 1947 von George Dantzig untersuchte Diät-Problem: Gegeben sind eine Reihe von Rohmaterialien (z.B. Hafer, Schweinefleisch, Sonnenblumenöl etc.) zusammen mit ihrem Gehalt an bestimmten Nährwerten (z.B. Eiweiß, Fett, Vitamin A etc.) und ihrem Preis pro Kilogramm. Die Aufgabe besteht darin, eines oder mehrere Endprodukte mit minimalen Kosten aus den Rohmaterialien zu mischen, unter der Nebenbedingung, dass bestimmte Mindest- und Höchstgrenzen für die einzelnen Nährwerte eingehalten werden. Auch bei Schmelzvorgängen treten solche Mischungsprobleme auf, wie z.B. in der Stahlherstellung.
Routing in Telekommunikations- oder Verkehrsnetzen
Ein klassisches Anwendungsgebiet der linearen Optimierung ist die Bestimmung eines Routings für Verkehrsanforderungen in Telekommunikations- oder Verkehrsnetzen, oft in Verbindung mit Kapazitätsplanung. Dabei müssen Verkehrsflüsse so durch ein Netz geroutet werden, dass alle Verkehrsanforderungen erfüllt werden, ohne die Kapazitätsbedingungen zu verletzen. Diese sogenannten Mehrgüterflüsse (englisch multicommodity flow) sind ein Beispiel für ein Problem, das mit linearer Optimierung gut lösbar ist, für das aber im allgemeinen Fall kein exakter Algorithmus bekannt ist, der nicht auf LP-Theorie basiert.
Spieltheorie
Innerhalb der mathematischen Spieltheorie kann die lineare Optimierung dazu verwendet werden, optimale Strategien in Zwei-Personen-Nullsummenspielen zu berechnen. Dabei wird für jeden Spieler eine Wahrscheinlichkeitsverteilung berechnet, bei der es sich um ein zufälliges Mischungsverhältnis seiner Strategien handelt. „Würfelt“ ein Spieler seine Strategie gemäß dieser Wahrscheinlichkeitsverteilung zufällig aus, ist ihm die bestmögliche Gewinnerwartung sicher, die er haben kann, wenn er seine Strategie unabhängig von der seines Gegners wählt.
Nichtlineare und ganzzahlige Optimierung
Viele Anwendungsprobleme lassen sich mit kontinuierlichen Variablen nicht sinnvoll modellieren, sondern erfordern die Ganzzahligkeit einiger Variablen. Beispielsweise können keine 3,7 Flugzeuge gekauft werden, sondern nur eine ganze Anzahl, und ein Bus kann nur ganz oder gar nicht fahren, aber nicht zu zwei Dritteln. Bei der Verwendung von Branch-and-Cut zur Lösung eines solchen ganzzahligen linearen Optimierungsproblems müssen sehr viele ähnliche lineare Programme hintereinander als Unterproblem gelöst werden. Eine optimale ganzzahlige Lösung eines linearen Programms zu finden ist NP-vollständig, aber parametrisierbar in der Anzahl der Variablen. Es ist sogar NP-vollständig, irgendeine ganzzahlige Lösung eines linearen Programms zu finden. Eine Ausnahme ist hier, wenn die Restriktionsmenge durch eine total unimodulare Matrix gegeben ist, dann sind alle Ecken des Polyeders ganzzahlig. Auch zur Lösung nichtlinearer Optimierungsprobleme gibt es Algorithmen, in denen lineare Programme als Unterproblem gelöst werden müssen (z.B. Sequential Linear Programming).
Lösbarkeit aus theoretischer Sicht
Ein lineares Programm hat nicht immer eine Optimallösung. Drei Fälle sind zu unterscheiden:
- Das LP ist unzulässig, weil sich Ungleichungen widersprechen
(z.B.
 und
und  ).
In diesem Fall gibt es keine Lösung, die alle Ungleichungen erfüllt,
d.h. das zugehörige Polyeder ist die leere Menge.
).
In diesem Fall gibt es keine Lösung, die alle Ungleichungen erfüllt,
d.h. das zugehörige Polyeder ist die leere Menge. - Das LP ist unbeschränkt, d.h. es gibt unendlich viele zulässige
Lösungen mit beliebig hohen Zielfunktionswerten (z.B.
 )
gegeben, falls das zugehörige Polyeder beschränkt, also ein Polytop, und
nichtleer ist.
)
gegeben, falls das zugehörige Polyeder beschränkt, also ein Polytop, und
nichtleer ist.
Die Menge der Optimallösungen bildet eine Seitenfläche (Ecke, Kante,…) des Polyeders, so dass es entweder keine, genau eine oder unendlich viele Optimallösungen gibt. Wenn das LP lösbar und beschränkt ist, gibt es immer eine optimale Ecke, also einen optimalen Punkt, der nicht aus anderen Punkten des Polyeders konvex kombiniert werden kann. Diese Eigenschaft macht sich unter anderem das primale Simplex-Verfahren zunutze.
Komplexität und Lösungsverfahren
Das Finden einer Optimallösung bzw. die Feststellung, dass ein LP keine Lösung besitzt, ist mit Hilfe von Innere-Punkte-Verfahren oder der Ellipsoidmethode in Polynomialzeit möglich, so dass die Lineare Optimierung aus Sicht der Komplexitätstheorie ein leicht lösbares Problem ist. Aus praktischer Sicht ist jedoch oft das Simplex-Verfahren schneller, obwohl es theoretisch exponentielle Laufzeit besitzt. Es ist bis heute unbekannt, ob es einen streng polynomialen Algorithmus zur Lösung allgemeiner linearer Programme gibt, also einen Algorithmus, dessen Laufzeit nicht von der Größe der auftretenden Zahlen abhängt.
Simplex-Verfahren
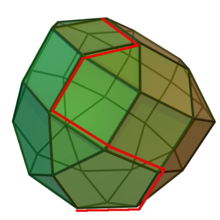
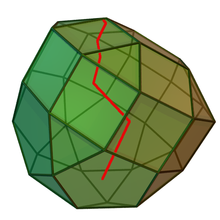
Das Simplex-Verfahren ist ein Basisaustauschverfahren, das im Jahre 1947 von George Dantzig entwickelt und seitdem wesentlich verbessert wurde; es ist der wichtigste Algorithmus zur Lösung linearer Programme in der Praxis. Die Grundidee besteht darin, von einer Ecke des Polyeders zu einer benachbarten Ecke mit besserem Zielfunktionswert zu laufen, bis dies nicht mehr möglich ist. Da es sich bei der linearen Optimierung um ein konvexes Optimierungsproblem handelt, ist die damit erreichte lokal optimale Ecke auch global optimal. Das Verfahren ist im nebenstehenden Bild illustriert: Ziel ist es, einen möglichst weit oben liegenden Punkt des Polyeders zu finden. In roter Farbe ist ein möglicher Pfad des Simplex-Verfahrens entlang der Ecken des Polyeders dargestellt, wobei sich der Zielfunktionswert mit jedem Schritt verbessert.
Aus komplexitätstheoretischer Sicht benötigt der Simplex-Algorithmus im schlechtesten Fall exponentielle Laufzeit. Für jede Variante des Algorithmus konnte bisher ein Beispiel konstruiert werden, bei dem der Algorithmus alle Ecken des Polyeders abläuft, meist basierend auf dem Klee-Minty-Würfel. Aus praktischer Sicht sind solche Fälle allerdings sehr selten. Bei sogenannten entarteten linearen Programmen, bei denen eine Ecke durch mehr Ungleichungen definiert wird als unbedingt nötig (beispielsweise durch drei Ungleichungen im zweidimensionalen Raum), kann es allerdings passieren, dass der Algorithmus, wie in diesem Beispiel, immer wieder dieselbe Ecke betrachtet, anstatt zur nächsten Ecke zu wechseln. Dieses Problem tritt bei praktischen Planungsproblemen häufig auf und kann dazu führen, dass der Algorithmus nicht terminiert oder der Zielfunktionswert sich über viele Iterationen hinweg nicht verbessert. Gute Simplex-Implementierungen entdecken solche Fälle und behandeln sie beispielsweise durch eine leichte Perturbation (absichtliche numerische Störung) des Problems, die später wieder rückgängig gemacht wird.
Unter der Voraussetzung, dass die Matrix  dünnbesetzt
ist (d.h. nur wenige Koeffizienten ungleich Null enthält), was in der
Praxis fast immer der Fall ist, können mit dem Simplex-Verfahren heute sehr
große LPs in annehmbarer Zeit optimal gelöst werden. Ein großer Vorteil des
Simplex-Verfahrens besteht darin, dass es nach dem Hinzufügen einer Ungleichung
oder Variable im LP oder nach einer leichten Änderung der Koeffizienten einen
„Warmstart“ von einer vorher bereits erreichten Ecke aus durchführen kann, so
dass nur wenige Iterationen zum erneuten Finden einer Optimallösung notwendig
sind. Dies ist insbesondere im Zusammenhang mit Schnittebenenverfahren
oder Branch-and-Cut
zur Lösung ganzzahliger linearer Programme von großer Bedeutung, wo sehr viele
ähnliche LPs in Serie gelöst werden müssen.
dünnbesetzt
ist (d.h. nur wenige Koeffizienten ungleich Null enthält), was in der
Praxis fast immer der Fall ist, können mit dem Simplex-Verfahren heute sehr
große LPs in annehmbarer Zeit optimal gelöst werden. Ein großer Vorteil des
Simplex-Verfahrens besteht darin, dass es nach dem Hinzufügen einer Ungleichung
oder Variable im LP oder nach einer leichten Änderung der Koeffizienten einen
„Warmstart“ von einer vorher bereits erreichten Ecke aus durchführen kann, so
dass nur wenige Iterationen zum erneuten Finden einer Optimallösung notwendig
sind. Dies ist insbesondere im Zusammenhang mit Schnittebenenverfahren
oder Branch-and-Cut
zur Lösung ganzzahliger linearer Programme von großer Bedeutung, wo sehr viele
ähnliche LPs in Serie gelöst werden müssen.
Innere-Punkte-Verfahren
Innere-Punkte-Verfahren, auch Barrier-Verfahren genannt, nähern sich einer optimalen Ecke durch das Innere des Polyeders (siehe Bild). Der erste solche Algorithmus wurde 1984 von Narendra Karmarkar beschrieben. Seine Bedeutung lag vor allem darin, dass er der erste polynomiale Algorithmus zum Lösen linearer Programme war, der das Potential hatte, auch praktisch einsetzbar zu sein. Die entscheidenden Durchbrüche, die Innere-Punkte-Verfahren konkurrenzfähig zum Simplex-Algorithmus machten, wurden aber erst in den 1990er-Jahren erzielt. Ein Vorteil dieser Verfahren ist, dass sie, im Gegensatz zum Simplex-Verfahren, in leichter Abwandlung auch zum Lösen quadratischer oder bestimmter nichtlinearer Programme eingesetzt werden können. Des Weiteren sind sie für große, dünnbesetzte Probleme häufig dem Simplex-Verfahren überlegen. Ein Nachteil ist, dass sie sich nach dem Hinzufügen einer Nebenbedingung oder Variablen im LP bei weitem nicht so effizient „warmstarten“ lassen wie das Simplex-Verfahren.
Ellipsoidmethode
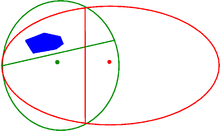
Die Ellipsoidmethode wurde ursprünglich in den Jahren 1976 und 1977 von David Yudin und Arkadi Nemirovski und unabhängig davon von Naum Schor zur Lösung konvexer Optimierungsprobleme entwickelt. Im Jahre 1979 modifizierte der sowjetische Mathematiker Leonid Khachiyan das Verfahren und entwickelte damit den ersten polynomialen Algorithmus zur Lösung linearer Programme. Für praktische Zwecke ist er allerdings nicht geeignet. Die Ellipsoidmethode dient dazu, einen beliebigen Punkt in einem volldimensionalen Polyeder zu finden oder festzustellen, dass das Polyeder leer ist. Da man zeigen kann, dass die Lösung eines LPs äquivalent ist zum Finden eines zulässigen Punktes in einem geeignet definierten Hilfspolyeder, lässt sich mit Hilfe der Ellipsoidmethode (theoretisch) auch ein LP lösen.
Die Grundidee des Verfahrens besteht darin, ein Ellipsoid (im Bild rot) zu definieren, das alle Ecken des Polyeders (blau) enthält. Anschließend wird festgestellt, ob der Mittelpunkt dieses Ellipsoids im Polyeder enthalten ist. Falls ja, hat man einen Punkt im Polyeder gefunden und kann aufhören. Andernfalls kann man das Halbellipsoid bestimmen, in dem das Polyeder enthalten sein muss, und ein neues, kleineres Ellipsoid um das Polyeder legen (im Bild grün). Nach einer Anzahl von Schritten, die polynomial von der Kodierungslänge des LPs abhängt, hat man entweder einen Punkt im Polyeder gefunden oder weiß, dass das Polyeder leer ist, weil es sonst größer sein müsste als das aktuelle Ellipsoid.
Weitere Methoden
Für einige Klassen von linearen Programmen gibt es spezielle Algorithmen, die theoretisch oder praktisch schneller laufen als z.B. der Simplexalgorithmus. Ein Beispiel hierfür ist die Ungarische Methode, die auf Zuordnungsprobleme angewandt werden kann. Lineare Programme mit zwei Variablen lassen sich näherungsweise zeichnerisch lösen (siehe obiges Beispiel). Diese Methode hat aber hauptsächlich didaktischen Wert, da in der Praxis auftretende LPs leicht mehrere Hunderttausende Variablen besitzen können.
Dualität
Obere Schranken
Um zu verifizieren, dass eine gültige Lösung  optimal für ein lineares Programm ist, versucht man, den Zielfunktionswert des
Programms nach oben abzuschätzen. Für das obige Beispiel gilt etwa
optimal für ein lineares Programm ist, versucht man, den Zielfunktionswert des
Programms nach oben abzuschätzen. Für das obige Beispiel gilt etwa

Da  und
und  folgt daraus, dass
folgt daraus, dass

Die Optimallösung kann somit keinen Zielfunktionswert größer als  haben. Eine bessere Abschätzung erhält man, indem man
haben. Eine bessere Abschätzung erhält man, indem man  Mal die zweite und
Mal die zweite und  Mal die dritte Ungleichung addiert:
Mal die dritte Ungleichung addiert:

Dieses Verfahren lässt sich leicht verallgemeinern: Wählt man für ein
gegebenes LP in Standardform Multiplikatoren  ,
so ist jeder Vektor
,
so ist jeder Vektor  eine obere Schranke, sofern
eine obere Schranke, sofern  .
Dies entspricht einer konischen
Kombination der Spalten von .
Die Bedingung
stellt sicher, dass sich die Koeffizienten von
.
Dies entspricht einer konischen
Kombination der Spalten von .
Die Bedingung
stellt sicher, dass sich die Koeffizienten von  für
gegen
abschätzen lassen. Der Zielfunktionswert der durch
für
gegen
abschätzen lassen. Der Zielfunktionswert der durch  gegebenen obere Schranke ist somit
gegebenen obere Schranke ist somit  .
Um die beste obere Schranke zu finden, kann man nun ein weiteres LP
aufstellen:
.
Um die beste obere Schranke zu finden, kann man nun ein weiteres LP
aufstellen:
Dieses LP nennt man das duale Problem zu dem primalen Problem
Die Einträge des Vektors
werden als Multiplikatoren oder Dualvariablen bezeichnet. Die Dualität
Linearer Programme ist ein Spezialfall der Lagrange-Dualität.
Falls ein lineares Programm aus einem kombinatorischen Optimierungsproblem entsteht, so hat das duale Programm oft eine anschauliche Interpretation; die nachfolgenden Sätze können dann auch benutzt werden, um Resultate wie das Max-Flow-Min-Cut-Theorem herzuleiten.
Dualisierung beliebiger linearer Programme
Für lineare Programme, welche nicht in Standardform vorliegen, gelten die folgenden Vorschriften zur Dualisierung:
| primales LP | duales LP |
|---|---|

|

|

|

|

|

|
Für Minimierungsprobleme gilt analog:
| primales LP | duales LP |
|---|---|

|

|

|

|

|

|
Im Allgemeinen gilt:
| primales LP | duales LP |
|---|---|
| nichtnegative Variable | Ungleichung |
| nicht vorzeichenbeschränkte Variable | Gleichung |
| Ungleichung | nichtnegative Variable |
| Gleichung | nicht vorzeichenbeschränkte Variable |
Dabei ist zu beachten, dass bei Maximierungsproblemen die Ungleichungen stets
in der Form
und bei Minimierungsproblemen in der Form  aufgeschrieben werden.
aufgeschrieben werden.
Eigenschaften des dualen Programms
Das primale und duale LP bilden ein duales Paar, es gilt also, dass aus der Dualisierung des dualen LP wieder das primale LP entsteht.
Des Weiteren gilt für beliebige zulässige primale bzw. duale Lösungen  :
:

Dabei gilt die erste Ungleichung, da
und
und die zweite, weil
und  .
Dieses Resultat ist als der schwache Dualitätssatz bekannt. Er entspricht
der schwachen
Dualität in der Lagrange-Dualität.
.
Dieses Resultat ist als der schwache Dualitätssatz bekannt. Er entspricht
der schwachen
Dualität in der Lagrange-Dualität.
Der starke Dualitätssatz
Der starke Dualitätssatz verschärft die obige Aussage: Wenn eines der
beiden LPs eine beschränkte Optimallösung besitzt, dann auch das andere, und die
optimalen Zielfunktionswerte sind in diesem Fall gleich. Für jede optimale
Lösung
des primalen und jede optimale Lösung  des dualen Problems gilt also
des dualen Problems gilt also
 .
.
Dies entspricht der starken Dualität in der Lagrange-Dualität. Man kann zeigen, dass folgende Zusammenhänge gelten:
- Das duale Problem hat genau dann eine beschränkte Optimallösung, wenn das primale Problem eine beschränkte Optimallösung besitzt.
- Wenn das primale Problem keine zulässige Lösung hat, ist das duale Problem unbeschränkt oder hat auch keine zulässige Lösung.
- Wenn das primale Problem unbeschränkt ist, hat das duale Problem keine zulässige Lösung.
Diese und weitere Sätze bilden die Grundlage für alle Verfahren, die mit primalen und dualen Schranken für den Wert einer Optimallösung arbeiten, wie beispielsweise Branch-and-Cut und Schnittebenenverfahren.
Der Satz vom komplementären Schlupf
Zusätzlich zu den obigen Zusammenhängen über die Lösbarkeit des primalen bzw. dualen Problems gilt die folgende Aussage:
Falls sowohl das primale als auch das duale Problem zulässige Lösungen haben,
so existiert ein Paar  von Lösungen mit der Eigenschaft, dass
von Lösungen mit der Eigenschaft, dass

Dies bedeutet, dass  und umgekehrt
und umgekehrt  .
Hierbei bezeichnet
.
Hierbei bezeichnet  die
die  -te
Komponente des Vektors
-te
Komponente des Vektors  .
.
Diese Lösungen sind auch optimal, da in diesem Fall die obigen Ungleichungen mit Gleichheit erfüllt sind:
 .
.
Diese zusätzliche Eigenschaft wird zum Beispiel bei primal-dualen Algorithmen ausgenutzt, um die Optimalität einer Lösung zu verifizieren.
Äquivalenz von Optimierungs- und Zulässigkeitsproblemen
Der starke Dualitätssatz ermöglicht es ebenfalls, Optimierungsprobleme auf
Zulässigkeitsprobleme zu reduzieren: Anstatt das Problem
zu lösen, kann man ebenso gut ein Paar von Lösungen finden, die den folgenden
Bedingungen gehorchen:

Dabei stellen die ersten beiden Bedingungen sicher, dass
eine zulässige Lösung des Problems ist, während die nächsten Bedingungen dafür
sorgen, dass
gültig für das duale Programm ist. Die letzte Ungleichung wird nur von solchen
Lösungspaaren
erfüllt, deren Zielfunktionswerte übereinstimmen. Dies ist genau dann der Fall,
wenn es sich bei
und
um die Optimallösungen der beiden Probleme handelt. Das obige
Optimierungsproblem hat damit eine Optimallösung genau dann wenn der obige
Polyeder nicht leer ist. Offensichtlich kann man die Zulässigkeit eines Problems
auch durch Lösung eines Optimierungsproblems entscheiden, man wählt dazu
beispielsweise den Nullvektor
als Zielfunktion. Damit sind lineare Optimierungsprobleme und
Zulässigkeitsprobleme von Polyedern äquivalent bezüglich ihrer Zeitkomplexität.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 01.10. 2025