Haar-Wavelet
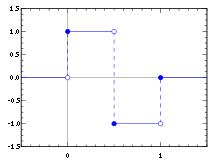
Das Haar-Wavelet ist das erste in der Literatur bekannt gewordene Wavelet und wurde 1909 von Alfréd Haar eingeführt. Es ist außerdem das einfachste bekannte Wavelet und kann aus der Kombination zweier Rechteckfunktionen gebildet werden.
Vorteilhaft am Haar-Wavelet ist die einfache Implementierbarkeit der zugehörigen Wavelet-Transformation als schnelle Wavelet-Transformation (FWT). Der Nachteil des Haar-Wavelets ist, dass es unstetig und daher auch nicht differenzierbar ist.
Die Funktionen der Haar-Wavelet-Basis
Skalierungsfunktion
Die Skalierungsfunktion bzw. „Vater-Wavelet“-Funktion der Haar-Wavelet-Basis
ist die Indikatorfunktion
des Intervalls  .
.

Sie erfüllt die Funktionalgleichung
 mit
mit  .
.
Waveletfunktion
Die Waveletfunktion ist die „zusammengeschobene“ Differenz zweier aufeinanderfolgender Skalierungsfunktionen:
 ,
,
wobei  .
.
Die Schreibweise mit Vorfaktor sorgt dafür, dass die Matrix

eine orthogonale Matrix ist. Dies ist Teil der Bedingungen, die orthogonale Wavelets erfordern.
Multiskalenanalyse
Diese Funktion erzeugt die Multiskalenanalyse
der Stufenfunktionen. In dieser wird jeder Funktion  mit „endlicher Energie“ auf jeder Skala
mit „endlicher Energie“ auf jeder Skala  die folgende Projektion zugewiesen:
die folgende Projektion zugewiesen:
 mit
mit  .
.
Die Differenz zwischen zwei Skalen lässt sich dann durch das „Mutter-Wavelet“ bzw. die eigentliche Waveletfunktion ausdrücken:
 .
.
Mit  und
und  als Funktionen im Hilbertraum
als Funktionen im Hilbertraum
 gilt
gilt
- alle diese Funktionen haben
 -Norm
1,
-Norm
1,  ist senkrecht zu
ist senkrecht zu  falls
falls  ,
, ist senkrecht zu
ist senkrecht zu  falls
falls  oder ,
oder ,- die
bilden eine Hilbertbasis
von .
Schnelle Haar-Wavelet-Transformation
Gegeben sei ein diskretes Signal f, welches durch eine endliche oder quadratsummierbare Folge

dargestellt ist. Ihm ist als kontinuierliches Signal die Treppenfunktion

zugeordnet.
Vorwärtstransformation
Aus dem diskreten Signal wird durch paarweises „Senkrechtstellen“ ein vektorwertiges Signal, die sogenannte Polyphasenzerlegung, erzeugt:
 .
.
Dieser wird nun gliedweise mit der Haar-Transformationsmatrix  multipliziert
multipliziert
 ,
,
dabei ist  und
und  .
.
Rücktransformation
Wir erhalten ein Mittelwertsignal  und ein Differenzsignal
und ein Differenzsignal  ,
aus denen durch einfache Umkehr der vorgenommenen Schritte das Ausgangssignal
zurückgewonnen werden kann:
,
aus denen durch einfache Umkehr der vorgenommenen Schritte das Ausgangssignal
zurückgewonnen werden kann:
 und
und 
Ist die Schwankung von Glied zu Glied im Ausgangssignal durch ein kleines
 beschränkt, so ist die Schwankung in
durch
beschränkt, so ist die Schwankung in
durch  beschränkt, also immer noch klein, die Größe der Glieder in
jedoch durch
beschränkt, also immer noch klein, die Größe der Glieder in
jedoch durch  .
Ein glattes Signal wird also in ein immer noch glattes Signal halber
Abtastfrequenz und in ein kleines Differenzsignal zerlegt. Dies ist der
Ausgangspunkt für die Wavelet-Kompression.
.
Ein glattes Signal wird also in ein immer noch glattes Signal halber
Abtastfrequenz und in ein kleines Differenzsignal zerlegt. Dies ist der
Ausgangspunkt für die Wavelet-Kompression.
Rekursive Filterbank
Wir können den Vorgang wiederholen, indem wir s zum Ausgangssignal
erklären und mit obigem Vorgehen zerlegen, wir erhalten eine Folge von
Zerlegungen  ,
,
 hat ein
hat ein  -tel
der ursprünglichen Abtastfrequenz und eine durch
-tel
der ursprünglichen Abtastfrequenz und eine durch  beschränkte Schwankung,
beschränkte Schwankung,  hat ebenfalls ein -tel
der ursprünglichen Abtastfrequenz und durch
hat ebenfalls ein -tel
der ursprünglichen Abtastfrequenz und durch  beschränkte Glieder.
beschränkte Glieder.
Interpretation
Als diskretes
Signal  wird meist eine reelle Folge
wird meist eine reelle Folge  über
über  mit endlicher Energie betrachtet,
mit endlicher Energie betrachtet,
 .
.
Unter diesen gibt es einige sehr einfache Folgen δn,
Kronecker- oder Dirac-Delta genannt, eine für jedes  .
Für deren Folgenglieder gilt, dass das jeweils
.
Für deren Folgenglieder gilt, dass das jeweils  -te
den Wert
-te
den Wert  hat,
hat,  ,
und alle anderen den Wert
,
und alle anderen den Wert  ,
,
 falls
falls  .
.
Jetzt können wir jedes Signal trivial als Reihe im Signalraum schreiben

oder als Summe zweier Reihen
 .
.
In vielen praktisch relevanten Signalklassen, z.B. bei überabgetasteten bandbeschränkten
kontinuierlichen Signalen, sind Werte benachbarter Folgenglieder auch
benachbart, d. h. im Allgemeinen liegen  und
und  dicht beisammen, relativ zu ihrem Absolutbetrag. Dies wird in der obigen Reihen
aber überhaupt nicht berücksichtigt. In Mittelwert und Differenz von
und
käme deren Ähnlichkeit stärker zum Ausdruck, der Mittelwert ist beiden Werten
ähnlich und die Differenz klein. Benutzen wir die Identität
dicht beisammen, relativ zu ihrem Absolutbetrag. Dies wird in der obigen Reihen
aber überhaupt nicht berücksichtigt. In Mittelwert und Differenz von
und
käme deren Ähnlichkeit stärker zum Ausdruck, der Mittelwert ist beiden Werten
ähnlich und die Differenz klein. Benutzen wir die Identität

um benachbarte Glieder der ersten Reihe bzw. korrespondierende Glieder in der zweiten Zerlegung zusammenzufassen in (skalierten) Mittelwerten und Differenzen:

Jetzt führen wir neue Bezeichnungen ein:
- die neuen Basisfolgen
-
 und
und 
- mit den neuen transformierten Koeffizienten
-
 und
und  .
.
Wir erhalten somit die Zerlegung der Haar-Wavelet-Transformation
 .
.
und mittels des unendlichen euklidischen Skalarproduktes können wir schreiben
 und
und  .
.
Die letzten drei Identitäten beschreiben eine „Conjugate Quadrature
Filterbank (CQF)“, welche so auch für allgemeinere Basisfolgen  und
und  definiert werden kann. Die Basisfolgen
entstehen alle durch Verschiebung um das jeweilige
definiert werden kann. Die Basisfolgen
entstehen alle durch Verschiebung um das jeweilige  aus
aus  ,
die
durch Verschiebung aus
,
die
durch Verschiebung aus  .
Weiteres dazu im Artikel Daubechies-Wavelets.
.
Weiteres dazu im Artikel Daubechies-Wavelets.
Nun enthält die Folge  eine geglättete Version des Ausgangssignals bei halber Abtastrate, man kann also
auch
nach dieser Vorschrift zerlegen und dieses Vorgehen über eine bestimmte Tiefe
rekursiv fortsetzen. Aus einem Ausgangssignal
eine geglättete Version des Ausgangssignals bei halber Abtastrate, man kann also
auch
nach dieser Vorschrift zerlegen und dieses Vorgehen über eine bestimmte Tiefe
rekursiv fortsetzen. Aus einem Ausgangssignal  werden also nacheinander die Tupel
werden also nacheinander die Tupel
 ,
,
 ,
,
 ,
…
,
…
Ist
endlich, also fast überall Null, mit Länge  ,
dann haben die Folgen in der Zerlegung im Wesentlichen, d.h. bis auf
additive Konstanten, die Längen
,
dann haben die Folgen in der Zerlegung im Wesentlichen, d.h. bis auf
additive Konstanten, die Längen
 ,
,
 ,
,
 ,
…
,
…
so dass die Gesamtzahl wesentlicher Koeffizienten erhalten bleibt. Die Folgen in der Zerlegung eignen sich meist besser zur Weiterverarbeitung wie Kompression oder Suche nach bestimmtem Merkmalen als das rohe Ausgangssignal.
Modifikationen
Die Polyphasenzerlegung des Ausgangssignals kann auch zu einer anderen
Blockgröße s als 2 erfolgen, von der entsprechenden Haar-Matrix ist zu
fordern, dass sie eine orthogonale
Matrix ist und ihre erste Zeile nur aus Einträgen  besteht. Diese Anforderung erfüllen die Matrizen der
diskreten
Kosinustransformation und die der Walsh-Hadamard-Transformation.
besteht. Diese Anforderung erfüllen die Matrizen der
diskreten
Kosinustransformation und die der Walsh-Hadamard-Transformation.
Die Haar-Wavelet-Transformation entspricht einer
diskreten
Kosinustransformation zur Blockgröße  ,
welche im Bild=Pixelrechteck nacheinander in horizontaler und vertikaler
Richtung angewandt wird.
,
welche im Bild=Pixelrechteck nacheinander in horizontaler und vertikaler
Richtung angewandt wird.
Literatur
- Alfréd Haar: Zur Theorie der orthogonalen Funktionensysteme, Mathematische Annalen 69, 331–371, 1910.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 31.01. 2021