Hauptkomponentenanalyse
Die Hauptkomponentenanalyse (kurz: HKA, englisch Principal Component Analysis, kurz: PCA; das mathematische Verfahren ist auch als Hauptachsentransformation oder Singulärwertzerlegung bekannt) ist ein Verfahren der multivariaten Statistik. Sie dient dazu, umfangreiche Datensätze zu strukturieren, zu vereinfachen und zu veranschaulichen, indem eine Vielzahl statistischer Variablen durch eine geringere Zahl möglichst aussagekräftiger Linearkombinationen (die Hauptkomponenten) genähert wird. Speziell in der Bildverarbeitung wird die Hauptkomponentenanalyse, auch Karhunen-Loève-Transformation genannt, benutzt. Sie ist von der Faktorenanalyse zu unterscheiden, mit der sie formale Ähnlichkeit hat und in der sie als Näherungsmethode zur Faktorenextraktion verwendet werden kann (der Unterschied der beiden Verfahren wird im Artikel Faktorenanalyse erläutert).
Es gibt verschiedene Verallgemeinerungen der Hauptkomponentenanalyse, z.B. die Principal Curves, die Principal Surfaces oder die Kernbasierte Hauptkomponentenanalyse (kernel principal component analysis, kurz: kernel PCA).
Geschichte
Die Hauptkomponentenanalyse wurde von Karl Pearson 1901 eingeführt und in den 1930er Jahren von Harold Hotelling weiterentwickelt. Wie andere statistische Analysemethoden erlangte sie weite Verbreitung erst mit der zunehmenden Verfügbarkeit von Computern im dritten Viertel des 20. Jahrhunderts. Die ersten Anwendungen entstammten der Biologie.
Konzeption der Hauptkomponentenanalyse
Der zugrundeliegende Datensatz hat typischerweise die Struktur einer Matrix:
An  Versuchspersonen oder Gegenständen wurden jeweils
Versuchspersonen oder Gegenständen wurden jeweils  Merkmale gemessen. Ein solcher Datensatz kann als Menge von
Punkten im -dimensionalen
Raum
Merkmale gemessen. Ein solcher Datensatz kann als Menge von
Punkten im -dimensionalen
Raum  veranschaulicht werden. Ziel der Hauptkomponentenanalyse ist es, diese
Datenpunkte so in einen
veranschaulicht werden. Ziel der Hauptkomponentenanalyse ist es, diese
Datenpunkte so in einen  -dimensionalen
Unterraum
-dimensionalen
Unterraum  (
( )
zu projizieren, dass dabei möglichst wenig Information verloren geht und
vorliegende Redundanz
in Form von Korrelation
in den Datenpunkten zusammengefasst wird.
)
zu projizieren, dass dabei möglichst wenig Information verloren geht und
vorliegende Redundanz
in Form von Korrelation
in den Datenpunkten zusammengefasst wird.
Mathematisch wird eine Hauptachsentransformation durchgeführt: Man minimiert die Korrelation mehrdimensionaler Merkmale durch Überführung in einen Vektorraum mit neuer Basis. Die Hauptachsentransformation lässt sich durch eine orthogonale Matrix angeben, die aus den Eigenvektoren der Kovarianzmatrix gebildet wird. Die Hauptkomponentenanalyse ist damit problemabhängig, weil für jeden Datensatz eine eigene Transformationsmatrix berechnet werden muss. Die Rotation des Koordinatensystems wird so ausgeführt, dass die Kovarianzmatrix diagonalisiert wird, d.h. die Daten werden dekorreliert (die Korrelationen sind die Außerdiagonaleinträge der Kovarianzmatrix). Für normalverteilte Datensätze bedeutet dies, dass die einzelnen Komponenten jedes Datensatzes nach der PCA voneinander statistisch unabhängig sind, da die Normalverteilung durch das nullte (Normierung), erste (Erwartungswert) und zweite Moment (Kovarianzen) vollständig charakterisiert wird. Sind die Datensätze nicht normalverteilt, werden die Daten auch nach der PCA – obwohl nun dekorreliert – noch immer statistisch abhängig sein. Die PCA ist also nur für normalverteilte Datensätze eine „optimale“ Methode.
Anwendungsbeispiel
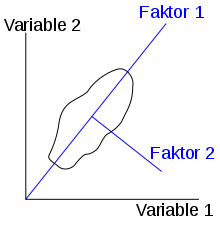
Betrachtet werden Artillerieschiffe des Zweiten Weltkriegs. Sie sind eingeteilt in die Klassen Schlachtschiffe, schwere Kreuzer, leichte Kreuzer und Zerstörer. Es liegen Daten für ca. 200 Schiffe vor. Es wurden die Merkmale Länge, Breite, Wasserverdrängung, Tiefgang, Leistung der Maschinen, Geschwindigkeit (längerfristig mögliche Höchstgeschwindigkeit), Aktionsradius und Mannschaftsstärke erfasst. Die Merkmale Länge, Breite, Wasserverdrängung und Tiefgang können so aufgefasst werden, dass sie alle einen ähnlichen Sachverhalt messen, den man als den Faktor „Größe“ beschreiben könnte. Die Frage ist, ob noch andere Faktoren die Daten bestimmen. Es gibt tatsächlich noch einen zweiten deutlichen Faktor, der vor allem durch die Leistung der Maschinen und die Höchstgeschwindigkeit bestimmt wird. Man könnte ihn zu einem Faktor „Geschwindigkeit“ zusammenfassen.
Andere Beispiele für Anwendungen der Hauptkomponentenanalyse sind:
- Wendet man die Hauptkomponentenanalyse auf das Kaufverhalten von Konsumenten an, gibt es möglicherweise latente Faktoren wie sozialer Status, Alter oder Familienstand, die bestimmte Käufe motivieren. Hier könnte man durch gezielte Werbung die Kauflust entsprechend kanalisieren.
- Hat man ein statistisches Modell mit sehr vielen Merkmalen, könnte mit Hilfe der Hauptkomponentenanalyse gegebenenfalls die Zahl der Variablen im Modell reduziert werden, was meistens die Modellqualität steigert.
- Anwendung findet die Hauptkomponentenanalyse auch in der Bildverarbeitung – insbesondere bei der Fernerkundung. Dabei kann man Satellitenbilder analysieren und Rückschlüsse daraus ziehen.
- Ein weiteres Gebiet ist die Künstliche Intelligenz, zusammen mit den Neuronalen Netzen. Dort dient die PCA zur Merkmalstrennung im Rahmen der automatischen Klassifizierung bzw. in der Mustererkennung.
Verfahren
Idee
Die Daten liegen als Punktwolke in einem -dimensionalen
kartesischen Koordinatensystem
vor.
Beste lineare Approximation an den Datensatz
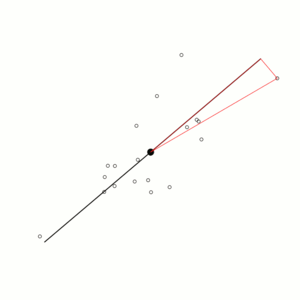
Das Berechnen der Hauptkomponenten kann man als iterativen Prozess auffassen. In der rechten Grafik wird für die Datenpunkte (nicht ausgefüllte Kreise) diejenige Gerade gesucht, die die Daten am besten approximiert. Der Fehler eines Datenpunktes ist der euklidische Abstand zwischen der Geraden und den Datenpunkten. Für den Datenpunkt rechts oben ist der Fehler die rote Linie, die senkrecht auf der schwarzen Geraden steht. Die erste Hauptkomponente ist die Gerade, bei der die Summe der Quadrate dieser Fehler minimal ist.
Danach wird eine weitere Gerade gesucht, die auch durch den Mittelwert der
Datenpunkte geht und orthogonal zur ersten Geraden ist: die zweite
Hauptkomponente. Im Falle zweidimensionaler Daten ist dies einfach die senkrecht
auf der ersten Hauptkomponente stehende Gerade. Ansonsten ist die jeweils
nächste Hauptkomponente senkrecht zu allen bisherigen Hauptkomponenten; mit
dieser Bedingung wird wieder die Gerade bestimmt, bei der die Quadratsumme
der Abstände minimal ist. So können die weiteren Geraden bis zur -ten
Hauptkomponente bestimmt werden.
Maximierung der Varianz
Die Distanz zwischen dem Zentrum der Daten und einem Datenpunkt ist
unabhängig davon, welche Gerade durch das Zentrum als „Referenz“ betrachtet wird
(siehe die rote Line vom Zentrum der Daten zum Datenpunkt rechts oben). Mittels
des Satzes von Pythagoras können wir aber den Abstand zerlegen in den Anteil in
Richtung der schwarzen Geraden und einen weiteren Anteil rechtwinklig dazu. Eine
Minimierung der Abstände rechtwinklig zur Geraden (unter Beibehaltung des
Abstands zum Datenzentrum, Länge der roten Linie) bedeutet also eine Maximierung
der Abstände in Richtung der schwarzen Geraden ( muss erhalten bleiben). Die aufsummierten Quadrate der Abstände in Richtung der
schwarzen Geraden bilden die Varianz der Daten in dieser Richtung.
muss erhalten bleiben). Die aufsummierten Quadrate der Abstände in Richtung der
schwarzen Geraden bilden die Varianz der Daten in dieser Richtung.
Dies führt zum folgenden Algorithmus: Die erste Achse soll so durch die Punktwolke gelegt werden, dass die Varianz der Daten in dieser Richtung maximal wird. Die zweite Achse steht auf der ersten Achse senkrecht. In ihrer Richtung ist die Varianz am zweitgrößten usw.
Für die -dimensionalen
Daten gibt es also grundsätzlich
Achsen, die aufeinander senkrecht stehen, sie sind orthogonal. Die totale Varianz der Daten
ist die Summe dieser „Achsenvarianzen“. Mit den
Achsen wird nun ein neues Koordinatensystem in die Punktwolke gelegt. Das neue
Koordinatensystem kann als Rotation der Variablenachsen dargestellt werden.
Wird nun durch die ersten  (
( )
Achsen ein hinreichend großer Prozentsatz der totalen Varianz abgedeckt,
erscheinen die Hauptkomponenten, die durch die neuen Achsen repräsentiert
werden, ausreichend für den Informationsgehalt der Daten. Die totale Varianz der Daten
ist also ein Maß für ihren Informationsgehalt.
)
Achsen ein hinreichend großer Prozentsatz der totalen Varianz abgedeckt,
erscheinen die Hauptkomponenten, die durch die neuen Achsen repräsentiert
werden, ausreichend für den Informationsgehalt der Daten. Die totale Varianz der Daten
ist also ein Maß für ihren Informationsgehalt.
Häufig können die Hauptkomponenten inhaltlich nicht interpretiert werden. In der Statistik spricht man davon, dass ihnen keine verständliche Hypothese zugeschrieben werden kann (siehe Faktorenanalyse).
Statistisches Modell
Man betrachtet Zufallsvariablen  ,
die bezüglich ihrer Erwartungswerte
zentriert sind. Das heißt, ihre Erwartungswerte wurden von der Zufallsvariablen
subtrahiert. Diese Zufallsvariablen werden in einem -dimensionalen
Zufallsvektor
,
die bezüglich ihrer Erwartungswerte
zentriert sind. Das heißt, ihre Erwartungswerte wurden von der Zufallsvariablen
subtrahiert. Diese Zufallsvariablen werden in einem -dimensionalen
Zufallsvektor  zusammengefasst. Dieser hat als Erwartungswertvektor
den Nullvektor und die
zusammengefasst. Dieser hat als Erwartungswertvektor
den Nullvektor und die  -Kovarianzmatrix
-Kovarianzmatrix  ,
die symmetrisch
und positiv
semidefinit ist. Die Eigenwerte
,
die symmetrisch
und positiv
semidefinit ist. Die Eigenwerte  ,
,
 ,
der Matrix
sind absteigend der Größe nach geordnet. Sie werden als Diagonalelemente in der
Diagonalmatrix
,
der Matrix
sind absteigend der Größe nach geordnet. Sie werden als Diagonalelemente in der
Diagonalmatrix  aufgeführt. Die zu ihnen gehörenden Eigenvektoren bilden die orthogonale
Matrix
aufgeführt. Die zu ihnen gehörenden Eigenvektoren bilden die orthogonale
Matrix  .
Es gilt dann
.
Es gilt dann 
Wird der Zufallsvektor
linear
transformiert zu  ,
dann
ist die Kovarianzmatrix von
,
dann
ist die Kovarianzmatrix von  gerade die Diagonalmatrix .
gerade die Diagonalmatrix .
Zur Verdeutlichung betrachten wir einen dreidimensionalen Zufallsvektor
 .
.
Die Matrix der Eigenwerte der Kovarianzmatrix
von
ist

wobei  ist.
ist.
Die normierten  -Eigenvektoren
-Eigenvektoren
 lassen sich als Spalten der Matrix
zusammenfassen:
lassen sich als Spalten der Matrix
zusammenfassen:

 .
.
Die Matrix-Vektor-Multiplikation

ergibt die Gleichungen


 .
.
Die Varianz von  ist
ist

Also hat die Hauptkomponente
den größten Anteil an der Gesamtvarianz der Daten,  den zweitgrößten Anteil usw. Die Elemente
den zweitgrößten Anteil usw. Die Elemente  ,
,
 ;
;
 ,
könnte man als Beitrag der Variablen
am Faktor
,
könnte man als Beitrag der Variablen
am Faktor  bezeichnen. Die Matrix
bezeichnet man in diesem Zusammenhang als Ladungsmatrix, sie gibt an, „wie hoch
eine Variable
bezeichnen. Die Matrix
bezeichnet man in diesem Zusammenhang als Ladungsmatrix, sie gibt an, „wie hoch
eine Variable  auf einen Faktor
auf einen Faktor  lädt“.
lädt“.
Schätzung der Modellparameter
Liegen konkret erhobene Daten mit
Merkmalen vor (d.h. jeder Datenpunkt ist ein -dimensionaler
Vektor), wird
aus den Merkmalswerten die Stichproben-Korrelationsmatrix
errechnet. Aus dieser Matrix bestimmt man dann die Eigenwerte und Eigenvektoren
für die Hauptkomponentenanalyse. Da die Kovarianzmatrix
eine symmetrische  -Matrix
ist, sind für ihre Berechnung insgesamt
-Matrix
ist, sind für ihre Berechnung insgesamt  Parameter zu schätzen. Dies ist nur dann sinnvoll, wenn die Anzahl
Parameter zu schätzen. Dies ist nur dann sinnvoll, wenn die Anzahl  der Datenpunkte im Datensatz deutlich größer ist, d.h. wenn
der Datenpunkte im Datensatz deutlich größer ist, d.h. wenn  .
Anderenfalls ist die Bestimmung der Kovarianzmatrix stark fehlerbehaftet, und
diese Methode sollte nicht angewandt werden.
.
Anderenfalls ist die Bestimmung der Kovarianzmatrix stark fehlerbehaftet, und
diese Methode sollte nicht angewandt werden.
Beispiel mit drei Variablen
Das oben genannte Anwendungsbeispiel wird jetzt in Zahlen verdeutlicht:
Wir betrachten die Variablen Länge, Breite und Geschwindigkeit. Die Streudiagramme geben einen Eindruck über die gemeinsame Verteilung der Variablen wieder.
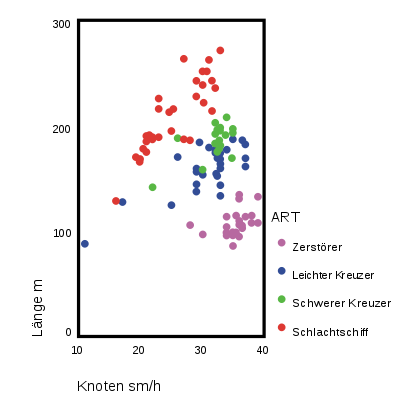
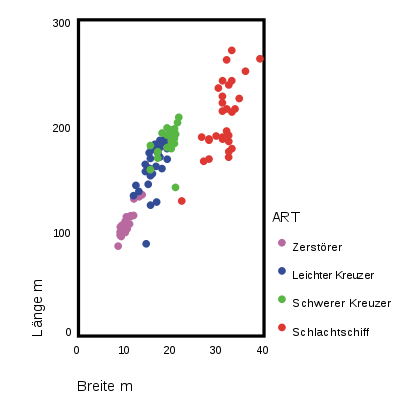
Mit diesen drei Variablen wurde mithilfe eines Statistikprogramms
eine Hauptkomponentenanalyse durchgeführt. Die Ladungsmatrix  ist
ist
| Faktor | A | B | C |
| Länge | 0,862 | 0,481 | −0,159 |
| Breite | 0,977 | 0,083 | 0,198 |
| Geschwindigkeit | −0,679 | 0,730 | 0,082 |
Der Faktor  setzt sich also zusammen aus
setzt sich also zusammen aus
 .
.
Vor allem die Beiträge von Länge und Breite zum ersten Faktor sind groß. Beim zweiten Faktor ist vor allem der Beitrag der Geschwindigkeit groß. Der dritte Faktor ist unklar und wohl auch unerheblich.
Die Gesamtvarianz der Daten verteilt sich wie folgt auf die Hauptkomponenten:
| Faktor | Eigenwert
|
Prozent der Gesamtvarianz | Prozentualer Anteil der Kumulierten Varianz an Gesamtvarianz |
| A | 2,16 | 71,97 | 71,97 |
| B | 0,77 | 25,67 | 97,64 |
| C | 0,07 | 2,36 | 100,00 |
Es werden also durch die ersten zwei Hauptkomponenten bereits 97,64 % der gesamten Varianz der Daten abgedeckt. Der dritte Faktor trägt nichts Nennenswertes zum Informationsgehalt bei.
Beispiel mit acht Variablen
Es wurden nun acht Merkmale der Artillerieschiffe einer Hauptkomponentenanalyse unterzogen. Die Tabelle der Ladungsmatrix, hier „Komponentenmatrix“ genannt, zeigt, dass vor allem die Variablen Länge, Breite, Tiefgang, Wasserverdrängung und Mannschaftsstärke hoch auf die erste Hauptkomponente laden. Diese Komponente könnte man als „Größe“ bezeichnen. Die zweite Komponente wird zum größten Teil durch PS und Knoten erklärt. Sie könnte „Geschwindigkeit“ genannt werden. Eine dritte Komponente lädt noch hoch auf Aktionsradius.
Die beiden ersten Faktoren decken bereits ca. 84 % der Information der Schiffsdaten ab, der dritte Faktor erfasst noch einmal ca. 10 %. Der zusätzliche Beitrag der restlichen Komponenten ist unerheblich.
| Komponentenmatrix | ||||||||
|---|---|---|---|---|---|---|---|---|
| Komponente | ||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Wasserverdrängung BRT | 0,948 | −0,094 | −0,129 | 0,228 | 0,040 | 0,036 | 0,136 | 0,055 |
| Länge m | 0,906 | 0,302 | −0,064 | −0,209 | 0,128 | −0,144 | −0,007 | −0,050 |
| Breite m | 0,977 | −0,128 | −0,031 | 0,032 | 0,103 | −0,017 | −0,014 | 0,129 |
| Tiefgang m | 0,934 | −0,276 | −0,061 | 0,014 | 0,074 | 0,129 | 0,154 | −0,038 |
| 1000 PS | 0,552 | 0,779 | −0,196 | −0,133 | −0,099 | 0,143 | −0,038 | 0,018 |
| Knoten sm/h | −0,520 | 0,798 | −0,157 | 0,222 | 0,109 | −0,038 | 0,071 | 0,004 |
| Aktionsradius 100 sm | 0,398 | 0,311 | 0,862 | 0,038 | 0,008 | 0,022 | −0,002 | −0,005 |
| Mannschaftsstärke | 0,955 | 0,063 | −0,052 | 0,108 | −0,226 | −0,121 | 0,067 | 0,002 |
| Extraktionsmethode: Hauptkomponentenanalyse | ||||||||
| Acht Komponenten extrahiert | ||||||||
| Varianz der Komponenten | |||
|---|---|---|---|
| Komponente | Eigenwerte | ||
| Total | % der Varianz | Kumulativ | |
| 1 | 5,19 | 64,88 | 64,88 |
| 2 | 1,54 | 19,22 | 84,10 |
| 3 | 0,83 | 10,43 | 94,53 |
| 4 | 0,18 | 2,22 | 96,74 |
| 5 | 0,11 | 1,34 | 98,08 |
| 6 | 0,08 | 0,95 | 99,03 |
| 7 | 0,05 | 0,67 | 99,70 |
| 8 | 0,02 | 0,30 | 100,00 |
Anwendung in der Clusteranalyse und Dimensionsreduktion
Die Hauptkomponentenanalyse (PCA) wird auch häufig in der Clusteranalyse und zur Reduzierung der Dimension des Parameterraums verwendet, insbesondere dann, wenn man noch keinerlei Vorstellung (Modell) von der Struktur der Daten hat. Dabei macht man sich zunutze, dass die PCA das (orthogonale) Koordinatensystem so dreht, dass die Kovarianzmatrix diagonalisiert wird. Außerdem sortiert die PCA die Reihenfolge der Koordinatenachsen (die Hauptkomponenten) so um, dass die erste Hauptkomponente den größten Anteil der Gesamtstreuung (Totale Varianz) im Datensatz enthält, die zweite Hauptkomponente den zweitgrößten Anteil usw. Wie an den Beispielen im vorigen Abschnitt illustriert wurde, kann man meist die hinteren Hauptkomponenten (also diejenigen, welche nur einen geringen Anteil an der Gesamtstreuung enthalten) ersatzlos streichen, ohne dass dadurch ein nennenswerter Informationsverlust entsteht.
Die Grundannahme für die Verwendung der PCA zur Clusteranalyse und Dimensionsreduktion lautet: Die Richtungen mit der größten Streuung (Varianz) beinhalten die meiste Information.
In diesem Zusammenhang ist sehr wichtig, dass diese Grundannahme lediglich eine Arbeitshypothese ist, welche nicht immer zutreffen muss. Um diesen Sachverhalt zu veranschaulichen, folgen zwei Beispiele:
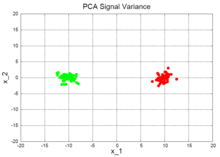
- Signal Variance (deutsch Signalvarianz): Die Grafik rechts mit dem Titel PCA Signal Variance zeigt ein Beispiel, bei dem die Annahme zutrifft. Der Datensatz besteht aus zwei Clustern (rot und grün), die klar voneinander getrennt sind. Die Streuung der Datenpunkte innerhalb jedes Clusters ist sehr klein verglichen mit dem „Abstand“ der beiden Cluster. Entsprechend wird die erste Hauptkomponente x_1 sein. Außerdem ist klar ersichtlich, dass die erste Hauptkomponente x_1 völlig ausreichend ist, um die beiden Cluster voneinander zu trennen, während die zweite Hauptkomponente x_2 dazu keinerlei nützliche Information enthält. Die Anzahl der Dimensionen kann also von 2 auf 1 reduziert werden (durch Vernachlässigung von x_2), ohne dass man dabei wesentliche Informationen über die beiden Cluster verlieren würde. Die Gesamtvarianz des Datensatzes wird also vom Signal dominiert (zwei getrennte Cluster).
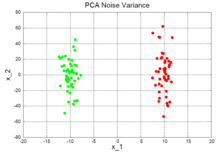
- Noise Variance (deutsch Rauschvarianz): Die Grafik rechts mit dem Titel PCA Noise Variance zeigt ein Beispiel, bei dem die Annahme nicht zutrifft und die PCA nicht zur Dimensionsreduktion verwendet werden kann. Die Streuung innerhalb der beiden Cluster ist nun deutlich größer und trägt den Hauptanteil an der Gesamtstreuung. Unter der Annahme, dass diese Streuung innerhalb der Cluster durch Rauschen verursacht wird, nennt man diesen Fall noise variance. Die erste Hauptkomponente wird x_2 sein, welche keinerlei Information über die Trennbarkeit beider Cluster beinhaltet.
Diese beiden Beispiele zeigen, wie man die PCA zur Reduzierung der Dimension und zur Clusteranalyse einsetzen kann bzw., dass dies nicht immer möglich ist. Ob die Grundannahme, dass die Richtungen der größten Streuung auch wirklich die interessantesten sind, zutrifft oder nicht, hängt vom jeweils gegebenen Datensatz ab und lässt sich oft nicht überprüfen – gerade dann, wenn die Anzahl der Dimensionen sehr hoch ist und sich die Daten demzufolge nicht mehr vollständig visualisieren lassen.
Zusammenhang mit der Multidimensionalen Skalierung
Sowohl die multidimensionale Skalierung als auch die Hauptkomponentenanalyse verdichten die Daten. Werden in der (metrischen) multidimensionalen Skalierung euklidische Distanzen verwendet und ist die Dimension der Konfiguration gleich der Zahl der Hauptkomponenten, so liefern beide Verfahren die gleiche Lösung. Dies liegt daran, dass die Diagonalisierung der Kovarianzmatrix (bzw. Korrelationsmatrix, falls mit standardisierten Daten gearbeitet wird) bei der Hauptkomponentenanalyse einer Rotation des Koordinatensystems entspricht. Dadurch bleiben die Distanzen zwischen den Beobachtungen, die den Ausgangspunkt in der multidimensionalen Skalierung bilden, gleich.
In der multidimensionalen Skalierung können jedoch auch andere Distanzen verwendet werden; insofern kann die Hauptkomponentenanalyse als Spezialfall der multidimensionalen Skalierung betrachtet werden.
Literatur
- G. H. Dunteman: Principal Component Analysis. Sage Publications, 1989
- L. Fahrmeir, A. Hamerle, G. Tutz (Hrsg.): Multivariate statistische Verfahren. New York 1996
- A. Handl, T. Kuhlenkasper: Multivariate Analysemethoden. Theorie und Praxis mit R. 3. Auflage. Springer, Berlin 2017, ISBN 978-3-662-54753-3.
- J. Hartung, B. Elpelt: Multivariate Statistik. München/Wien 1999
- T. Hastie, R. Tibshirani, J. Friedman: The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2001
- W. Kessler: Multivariate Datenanalyse. Weinheim 2007 (Eine Einführung in die PCA mit Beispiel-CD)
- W. J. Krzanowski: Principles of Multivariate Analysis. Rev. ed. Oxford University Press, Oxford 2000
- K. V. Mardia, J. T. Kent, J. M. Bibby: Multivariate Analysis. New York 1979


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 07.04. 2023