Gauß-Newton-Verfahren
Das Gauß-Newton-Verfahren (nach Carl Friedrich Gauß und Isaac Newton) ist ein numerisches Verfahren zur Lösung nichtlinearer Minimierungsprobleme nach der Methode der kleinsten Quadrate. Das Verfahren ist verwandt mit dem Newton-Verfahren zur Lösung nichtlinearer Optimierungsprobleme, hat jedoch den Vorteil, dass die für das Newton-Verfahren notwendige Berechnung der 2. Ableitung entfällt. Speziell für große Probleme mit mehreren zehntausend Parametern ist die Berechnung der 2. Ableitung oft ein limitierender Faktor.
Das Optimierungsproblem
Das Gauß-Newton-Verfahren löst Probleme, bei denen das Minimum einer Summe
von Quadraten stetig
differenzierbarer Funktionen  gesucht ist, also
gesucht ist, also

mit  .
Mit der euklidischen
Norm
.
Mit der euklidischen
Norm  lässt sich das auch schreiben als
lässt sich das auch schreiben als

mit  .
Probleme dieser Form kommen in der Praxis häufig vor, insbesondere ist das
nichtlineare Problem
.
Probleme dieser Form kommen in der Praxis häufig vor, insbesondere ist das
nichtlineare Problem  äquivalent zur Minimierung von
äquivalent zur Minimierung von  unter der Voraussetzung, dass
unter der Voraussetzung, dass  eine Nullstelle besitzt. Ist
eine lineare
Abbildung, ergibt sich der Standardfall der Methode
der kleinsten Quadrate mit linearer Modellfunktion.
eine Nullstelle besitzt. Ist
eine lineare
Abbildung, ergibt sich der Standardfall der Methode
der kleinsten Quadrate mit linearer Modellfunktion.
Die Methode
Die Grundidee des Gauß-Newton-Verfahrens besteht darin, die Zielfunktion
zu linearisieren und die
Linearisierung im Sinne der kleinsten Quadrate zu optimieren. Die
Linearisierung, also die Taylorentwicklung
1. Ordnung, von
im Punkt  lautet
lautet
 .
.
Die Matrix  ist die Jacobi-Matrix
und wird oft mit
ist die Jacobi-Matrix
und wird oft mit  bezeichnet. Man erhält das lineare kleinste-Quadrate Problem
bezeichnet. Man erhält das lineare kleinste-Quadrate Problem
 ,
,
mit Gradient  .
.
Nullsetzen des Gradienten liefert die sogenannten Normalgleichungen

mit der expliziten Lösung
 .
.
Daraus ergibt sich direkt der Gauß-Newton-Iterationsschritt
-
 ,
,
wobei  deutlich macht, dass die Jacobi-Matrix an der Stelle
deutlich macht, dass die Jacobi-Matrix an der Stelle  ausgewertet wird und
ausgewertet wird und  eine Schrittweite
ist.
eine Schrittweite
ist.
Um das lineare Gleichungssystem im Gauß-Newton-Iterationsschritt zu lösen gibt es verschiedene Möglichkeiten abhängig von der Problemgröße und der Struktur:
- Kleine Probleme (
 )
werden am besten mit der QR-Zerlegung
gelöst
)
werden am besten mit der QR-Zerlegung
gelöst - Für große Probleme bietet sich die Cholesky-Zerlegung
an, da die Matrix
 per Konstruktion symmetrisch
ist. Für dünnbesetzte
gibt es speziell angepasste Cholesky-Varianten
per Konstruktion symmetrisch
ist. Für dünnbesetzte
gibt es speziell angepasste Cholesky-Varianten - Als allgemeine Möglichkeit kann das CG-Verfahren verwendet werden, wobei hier üblicherweise eine Vorkonditionierung notwendig ist
Konvergenz
Der Update-Vektor im Gauß-Newton-Iterationsschritt hat die Form  ,
wobei
,
wobei  .
Wenn
vollen
Rang hat, so ist
und damit auch
.
Wenn
vollen
Rang hat, so ist
und damit auch  positiv
definit. Andererseits ist
positiv
definit. Andererseits ist  der Gradient
des quadratischen Problems
der Gradient
des quadratischen Problems  ,
somit ist
,
somit ist  eine Abstiegsrichtung, d.h. es gilt
eine Abstiegsrichtung, d.h. es gilt  .
Daraus folgt (bei geeigneter Wahl der Schrittweite
.
Daraus folgt (bei geeigneter Wahl der Schrittweite  )
die Konvergenz der Gauß-Newton-Methode zu einem stationären
Punkt. Aus dieser Darstellung lässt sich auch erkennen, dass die Gauß-Newton
Methode im Wesentlichen ein skaliertes Gradientenverfahren
mit der positiv definiten Skalierungsmatrix
ist.
)
die Konvergenz der Gauß-Newton-Methode zu einem stationären
Punkt. Aus dieser Darstellung lässt sich auch erkennen, dass die Gauß-Newton
Methode im Wesentlichen ein skaliertes Gradientenverfahren
mit der positiv definiten Skalierungsmatrix
ist.
Über die Konvergenzgeschwindigkeit
kann im Allgemeinen keine Aussage getroffen werden. Falls der Startpunkt  sehr weit vom Optimum entfernt ist oder die Matrix
schlecht konditioniert
ist, so konvergiert die Gauß-Newton-Methode beliebig langsam. Ist der Startpunkt
hingegen genügend nahe am Optimum, so kann man zeigen, dass die
Gauß-Newton-Methode quadratisch konvergiert.
sehr weit vom Optimum entfernt ist oder die Matrix
schlecht konditioniert
ist, so konvergiert die Gauß-Newton-Methode beliebig langsam. Ist der Startpunkt
hingegen genügend nahe am Optimum, so kann man zeigen, dass die
Gauß-Newton-Methode quadratisch konvergiert.
Erweiterung
Um das Verhalten im Fall von schlecht konditionierten bzw. singulären
zu verbessern, kann der Gauß-Newton-Iterationsschritt folgendermaßen modifiziert
werden
 ,
,
wobei die Diagonalmatrix
 so gewählt wird, dass
so gewählt wird, dass  positiv definit ist. Mit der Wahl
positiv definit ist. Mit der Wahl  ,
also einem skalaren Vielfachen der Identitätsmatrix,
erhält man den Levenberg-Marquardt-Algorithmus.
,
also einem skalaren Vielfachen der Identitätsmatrix,
erhält man den Levenberg-Marquardt-Algorithmus.
Beispiel
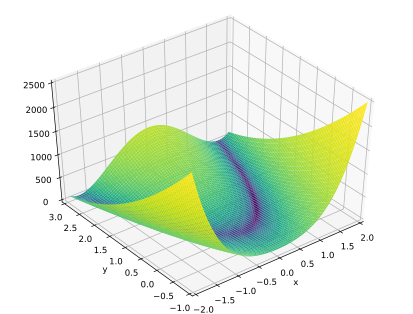
 .
.Die Rosenbrock-Funktion

wird häufig als Test für Optimierungsmethoden verwendet, da sie wegen des
schmalen und flachen Tals, in welchem iterative Methoden nur kleine Schritte
machen können, eine Herausforderung darstellt. Die Konstanten werden
üblicherweise mit
gewählt, das globale Optimum liegt in diesem Fall bei  mit dem Funktionswert
mit dem Funktionswert  .
.
Um die Gauß-Newton-Methode anzuwenden, muss die Rosenbrock-Funktion zunächst in die Form "Summe von Quadraten von Funktionen" gebracht werden. Da die Rosenbrock-Funktion bereits aus einer Summe von zwei Termen besteht wählt man den Ansatz

und
 .
.
Das Gauß-Newton-Problem für die Rosenbrock-Funktion lautet somit
 wobei
wobei  .
.
Die Jacobi-Matrix ergibt sich als  und damit ist
und damit ist  .
Da
vollen Rang
hat ist
positiv definit und die Inverse
.
Da
vollen Rang
hat ist
positiv definit und die Inverse  existiert.
Zur Bestimmung der Schrittweite
kommt folgende einfache Liniensuche
zum Einsatz:
existiert.
Zur Bestimmung der Schrittweite
kommt folgende einfache Liniensuche
zum Einsatz:
- Starte mit

- Berechne den neuen Punkt
 mit
mit 
- Wenn
 setze
setze  und gehe zur nächsten Iteration
und gehe zur nächsten Iteration - Ansonsten halbiere
und gehe zu 2.
Die Liniensuche erzwingt dass der neue Funktionswert kleiner als der
vorherige ist, sie terminiert garantiert (mit ev. sehr kleinem )
da
eine Abstiegsrichtung ist.
Als Startpunkt wird  gewählt. Die Gauß-Newton-Methode konvergiert in wenigen Iterationen zum globalen
Optimum:
gewählt. Die Gauß-Newton-Methode konvergiert in wenigen Iterationen zum globalen
Optimum:
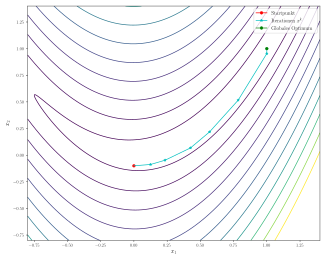
 |
|

|
|---|---|---|
| 0 | (0, -0.1) | 2 |
| 1 | (0.1250, -0.0875) | 1.8291 |
| 2 | (0.2344, -0.0473) | 1.6306 |
| 3 | (0.4258, 0.0680) | 1.6131 |
| 4 | (0.5693, 0.2186) | 1.3000 |
| 5 | (0.7847, 0.5166) | 1.0300 |
| 6 | (1.0, 0.9536) | 0.2150 |
| 7 | (1.0, 1.0) | 1.1212e-27 |
Das Gradientenverfahren (mit derselben Liniensuche) liefert im Vergleich dazu folgendes Ergebnis, es findet selbst nach 500 Iterationen nicht zum Optimum:
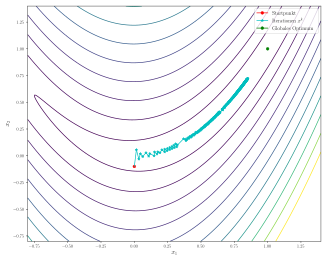
|
|
|
|
|---|---|---|
| 0 | (0, -0.1) | 2 |
| 1 | (0.0156, 0.0562) | 1.2827 |
| 2 | (0.0337, -0.0313) | 1.0386 |
| 3 | (0.0454, 0.0194) | 0.9411 |
| 4 | (0.0628, -0.0077) | 0.8918 |
| 5 | (0.0875, 0.0286) | 0.8765 |

|
|
|
| 500 | (0.8513, 0.7233) | 0.0223 |


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 11.02. 2023