Stichprobenkovarianz
Die Stichprobenkovarianz oder empirische Kovarianz (oft auch einfach Kovarianz (von lateinisch con- = „mit-“ und Varianz von variare = „(ver)ändern, verschieden sein“)) ist in der Statistik eine nichtstandardisierte Maßzahl für den (linearen) Zusammenhang zweier statistischer Variablen. Die korrigierte Stichprobenkovarianz ist eine erwartungstreue Schätzung der Kovarianz einer Grundgesamtheit mittels einer Stichprobe.
Ist die Kovarianz positiv, dann gehen kleine Werte der einen Variable überwiegend einher mit kleinen Werten der anderen Variable und gleichfalls für große Werte. Für eine negative Kovarianz ist das genau umgekehrt.
Definition
Ist  eine Datenreihe (Stichprobe)
zweier statistischer Variablen
eine Datenreihe (Stichprobe)
zweier statistischer Variablen  und
und  ,
dann ist die Stichprobenkovarianz definiert als „durchschnittliches
Abweichungsprodukt“
,
dann ist die Stichprobenkovarianz definiert als „durchschnittliches
Abweichungsprodukt“

mit  und
und  die arithmetischen
Mittel der Daten.
die arithmetischen
Mittel der Daten.
Die Stichprobenkovarianz misst die gemeinsame Streuung („Mitstreuung“) der
Beobachtungsdaten einer Stichprobe. Dabei wird die mittlere Abweichung der
Beobachtungsdaten von den Mittelwerten  berechnet.
berechnet.
Oft wird auch die korrigierte Stichprobenkovarianz genutzt:

Konstruktion der Kovarianz
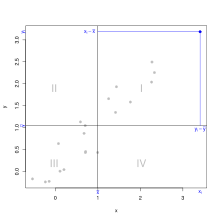
Der blaue Datenpunkt rechts oben in der Grafik hat einen positiven Beitrag zur Kovarianz:
 .
.
Dies gilt für alle Datenpunkte im Quadranten I, mit  und
und  .
Diese Betrachtungen kann man analog für die Datenpunkte in den anderen
Quadranten fortsetzen:
.
Diese Betrachtungen kann man analog für die Datenpunkte in den anderen
Quadranten fortsetzen:
- Datenpunkte in Quadrant I: positiver Beitrag zur Kovarianz,
- Datenpunkte in Quadrant II: negativer Beitrag zur Kovarianz,
- Datenpunkte in Quadrant III: positiver Beitrag zur Kovarianz und
- Datenpunkte in Quadrant IV: negativer Beitrag zur Kovarianz.
Gibt es einen "positiven" Zusammenhang zwischen den Datenpunkten, dann werden die meisten Datenpunkte (wie im rechten Beispiel) im Quadranten I und III liegen und viele positive Beiträge zur Kovarianz liefern. Die wenigen Datenpunkte in den Quadranten II und IV liefern zwar negative Beiträge, aber die positiven Beiträge werden überwiegen, d.h. die Kovarianz ist positiv. Gibt es einen "negativen" Zusammenhang, dann folgt mit der gleichen Argumentation, dass die Kovarianz negativ ist.
Korrigierte Stichprobenkovarianz
Um aus einer Stichprobe eine Schätzung der unbekannten Kovarianz  der Grundgesamtheit
zu erhalten wird die korrigierte Stichprobenkovarianz genutzt:
der Grundgesamtheit
zu erhalten wird die korrigierte Stichprobenkovarianz genutzt:

Bei einer einfachen Zufallsstichprobe
haben die Stichprobenvariablen
 und
und  die Kovarianz
die Kovarianz  .
Unter Annahme einer zweidimensionalen
Normalverteilung der Stichprobenvariablen
.
Unter Annahme einer zweidimensionalen
Normalverteilung der Stichprobenvariablen  und mit Hilfe der Maximum-Likelihood-Methode
ergibt sich die Schätzfunktion
und mit Hilfe der Maximum-Likelihood-Methode
ergibt sich die Schätzfunktion
 .
.
Es stellt sich jedoch heraus, dass der Erwartungswert
 ist, d.h. die Schätzfunktion
ist, d.h. die Schätzfunktion  ist nicht erwartungstreu
(also verzerrt)
für .
ist nicht erwartungstreu
(also verzerrt)
für .
Die korrigierte Stichprobenkovarianz ist jedoch unverzerrt. Im Rahmen der induktiven Statistik wird daher immer die korrigierte Stichprobenkovarianz verwendet.
Stichprobenkovarianz vs. Korrigierte Stichprobenkovarianz
Im Rahmen der deskriptiven
Statistik stellt sich die Frage, ob man besser den Faktor  oder
oder  verwenden soll. Allgemein hängt es vom Ziel der Analyse (bzw. den Eigenschaften
der Stichprobe) ab.
verwenden soll. Allgemein hängt es vom Ziel der Analyse (bzw. den Eigenschaften
der Stichprobe) ab.
- Ist es das Ziel die Kovarianz einer Grundgesamtheit zu schätzen, dann ist
wegen der Eigenschaft der Erwartungstreue
 ,
also der Faktor
zu verwenden. Dafür sollte aber der Rückschluss auf die Grundgesamtheit
möglich sein, z.B. die Stichprobe eine einfache Zufallsstichprobe
sein.
,
also der Faktor
zu verwenden. Dafür sollte aber der Rückschluss auf die Grundgesamtheit
möglich sein, z.B. die Stichprobe eine einfache Zufallsstichprobe
sein. - Ist es das Ziel die Daten nur deskriptiv zu beschreiben, dann kann man
oder
 verwenden. Dies ist z.B. der Fall, wenn der Rückschluss auf die
Grundgesamtheit nicht gewollt oder möglich ist. Dann muss der Anwender
entscheiden, welche Eigenschaft ihm wichtiger ist: der mögliche Rückschluss
auf die Grundgesamtheit (mit )
oder die Interpretation als mittlere Abweichung von
(mit ).
verwenden. Dies ist z.B. der Fall, wenn der Rückschluss auf die
Grundgesamtheit nicht gewollt oder möglich ist. Dann muss der Anwender
entscheiden, welche Eigenschaft ihm wichtiger ist: der mögliche Rückschluss
auf die Grundgesamtheit (mit )
oder die Interpretation als mittlere Abweichung von
(mit ).
Bei großen Stichprobenumfängen ist der Unterschied zwischen
und
ohnehin klein, so dass die obige Überlegung nur bei kleinen Stichprobenumfängen
angestellt werden muss.
Eigenschaften
Die folgenden Eigenschaften gelten sowohl für die Stichprobenkovarianz als auch für die korrigierte Stichprobenkovarianz.
Interpretation der Kovarianz
- Die Kovarianz ist positiv, wenn
und
tendenziell einen gleichsinnigen linearen Zusammenhang besitzen, d.h.
hohe Werte von
gehen mit hohen Werten von
einher und niedrige mit niedrigen.
- Die Kovarianz ist hingegen negativ, wenn
und
einen gegensinnigen linearen Zusammenhang aufweisen, d.h. hohe Werte der
einen Variablen gehen mit niedrigen Werten der anderen Variablen einher.
- Ist das Ergebnis 0, so besteht kein linearer Zusammenhang zwischen den
beiden Variablen
und
(nichtlineare Beziehungen sind möglich).
Die Kovarianz gibt zwar die Richtung eines Zusammenhangs zwischen zwei Variablen an, über die Stärke des Zusammenhangs kann aber, aufgrund der Linearität der Kovarianz, keine Aussage getroffen werden. Um einen Zusammenhang vergleichbar zu machen, muss die Kovarianz normiert werden. Die gebräuchlichste Normierung mittels der Standardabweichung führt zum Korrelationskoeffizienten.
Beziehung zur Varianz
Die Kovarianz ist eine Erweiterung der Varianz, denn es gilt
-
 bzw.
bzw. .
.
Dabei ist  und
und  die empirischen
Varianzen mit passendem Vorfaktor. Das heißt, die Varianz ist die Kovarianz
einer Variable mit sich selbst.
die empirischen
Varianzen mit passendem Vorfaktor. Das heißt, die Varianz ist die Kovarianz
einer Variable mit sich selbst.
Verschiebungssatz
Der Verschiebungssatz liefert eine alternative Darstellung der Kovarianz


. Diese Formeln ermöglichen in vielen Fällen eine einfachere Berechnung der Kovarianz. Bei numerischer Rechnung muss dabei allerdings auf unerwünschte Stellenauslöschung bei der Subtraktion großer Zahlen geachtet werden.
Symmetrie und Linearität
Die Kovarianz ist linear und symmetrisch, d.h. es gilt:
- Symmetrie
- Beim Vertauschen der Rollen von
 und
und  ergibt sich der gleiche Wert für die Kovarianz:
ergibt sich der gleiche Wert für die Kovarianz:
 bzw.
bzw.
- Linearität
- Wird eine der Variablen einer linearen Transformation unterzogen,
z.B.
 ,
so gilt
,
so gilt
 bzw.
bzw.
- Wegen der Symmetrie ist die Kovarianz auch im zweiten Argument linear.
Die Linearität der Kovarianz hat zur Folge, dass die Kovarianz von der
Maßeinheit der Variablen abhängt. So erhält man beispielsweise die zehnfache
Kovarianz, wenn man anstatt
die Variable  betrachtet. Da diese Eigenschaft die absoluten Werte der Kovarianz schwer
interpretierbar macht, betrachtet man häufig stattdessen den
maßstabsunabhängigen Korrelationskoeffizienten.
betrachtet. Da diese Eigenschaft die absoluten Werte der Kovarianz schwer
interpretierbar macht, betrachtet man häufig stattdessen den
maßstabsunabhängigen Korrelationskoeffizienten.
Beispiele
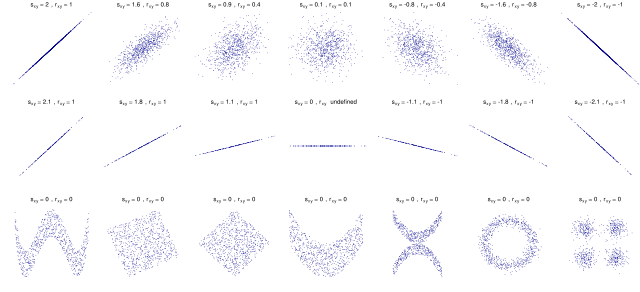
1.) Die folgende Grafik zeigt für 21 verschiedene Datensätze jeweils
das Streudiagramm zusammen
mit der Kovarianz
und der Korrelation
 des Datensatzes. Die erste Reihe zeigt sieben Datensätze mit unterschiedlich
starkem linearen Zusammenhang, wobei die Korrelation
von +1 über 0 nach −1 geht. Da die Kovarianz ein nicht-standardisiertes Maß
ist, geht sie von +2 auf Null bis auf −2. D.h., wenn es keinen linearen
Zusammenhang gibt, dann ist die Kovarianz genauso Null wie die Korrelation. Das
Vorzeichen
der Kovarianz zeigt die Richtung des Zusammenhangs an; jedoch zeigt sie nicht
die Stärke des Zusammenhangs.
des Datensatzes. Die erste Reihe zeigt sieben Datensätze mit unterschiedlich
starkem linearen Zusammenhang, wobei die Korrelation
von +1 über 0 nach −1 geht. Da die Kovarianz ein nicht-standardisiertes Maß
ist, geht sie von +2 auf Null bis auf −2. D.h., wenn es keinen linearen
Zusammenhang gibt, dann ist die Kovarianz genauso Null wie die Korrelation. Das
Vorzeichen
der Kovarianz zeigt die Richtung des Zusammenhangs an; jedoch zeigt sie nicht
die Stärke des Zusammenhangs.
Noch deutlicher wird es in der zweiten Zeile, wo alle sieben Datensätze einen
perfekten linearen Zusammenhang haben. Doch die Kovarianz
nimmt ab auf Null und wird dann negativ. Die Korrelation
ist für diese Datensätze entweder +1 oder −1 (bzw. undefiniert). Die dritte
Zeile zeigt schließlich, dass sowohl die Kovarianz als auch die Korrelation Null
ist, obwohl ein deutlicher Zusammenhang zwischen beiden Variablen sichtbar ist.
D.h. die Kovarianz misst nur den linearen Zusammenhang und nicht-lineare
Zusammenhänge werden nicht erkannt.
2.) In einer Schule soll überprüft werden, ob es einen Zusammenhang gibt zwischen der Anzahl der unterrichteten Stunden der Lehrer am Tag und der Anzahl der getrunkenen Tassen Kaffee. Es wurden zehn Datenpaare erhoben und ausgewertet (so nicht durchgeführt, nur der Anschauung halber!):
| Nummer | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Anzahl Stunden () |
5 | 6 | 8 | 4 | 6 | 6 | 5 | 7 | 5 | 4 |
| Anzahl Tassen () |
2 | 1 | 4 | 1 | 2 | 0 | 2 | 3 | 3 | 1 |
Die Kovarianz wird nun folgendermaßen berechnet:
a.) Zunächst wird das
arithmetische Mittel beider Variablen ermittelt:  und
und 
b.) Die Kovarianz wird nun berechnet über: 


Da die Kovarianz größer als null ist, ist für diese Stichprobe ein positiver Zusammenhang zwischen der Anzahl der Unterrichtsstunden und der Anzahl der Tassen Kaffee ersichtlich. Ob dies auf die Grundgesamtheit, hier das Lehrerkollegium, generalisierbar ist, hängt von der Qualität der Stichprobe ab.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 17.05. 2020