Methode der kleinsten Quadrate
Die Methode der kleinsten Quadrate (kurz KQ-Methode) ist das mathematische Standardverfahren zur Ausgleichungsrechnung. Dabei wird zu einer Datenpunktwolke eine Kurve gesucht, die möglichst nahe an den Datenpunkten verläuft. Die Daten können physikalische Messwerte, wirtschaftliche Größen oder Ähnliches repräsentieren, während die Kurve aus einer parameterabhängigen problemangepassten Familie von Funktionen stammt. Die Methode der kleinsten Quadrate besteht dann darin, die Kurvenparameter so zu bestimmen, dass die Summe der quadratischen Abweichungen der Kurve von den beobachteten Punkten minimiert wird. Die Abweichungen werden Residuen genannt.
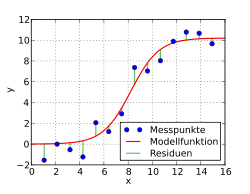
In der Beispielgrafik sind Datenpunkte eingetragen. In einem ersten Schritt
wird eine Funktionenklasse ausgewählt, die zu dem Problem und den Daten passen
sollte, hier eine logistische Funktion. Deren Parameter werden nun so bestimmt, dass die Summe der
Quadrate der Abweichungen  der Beobachtungen
der Beobachtungen  zu den Werten der Funktion minimiert
wird. In der Grafik ist die Abweichung
an der Stelle
zu den Werten der Funktion minimiert
wird. In der Grafik ist die Abweichung
an der Stelle  als senkrechter Abstand der Beobachtung
von der Kurve zu erkennen.
als senkrechter Abstand der Beobachtung
von der Kurve zu erkennen.
In der Stochastik wird die Methode der kleinsten Quadrate meistens als Schätzmethode in der Regressionsanalyse benutzt, wo sie auch als Kleinste-Quadrate-Schätzung bezeichnet wird. Angewandt als Systemidentifikation ist die Methode der kleinsten Quadrate in Verbindung mit Modellversuchen z.B. für Ingenieure ein Ausweg aus der paradoxen Situation, Modellparameter für unbekannte Gesetzmäßigkeiten zu bestimmen.
Geschichte
Am Neujahrstag 1801 entdeckte der italienische Astronom Giuseppe Piazzi den Zwergplaneten Ceres. 40 Tage lang konnte er die Bahn verfolgen, dann verschwand Ceres hinter der Sonne. Im Laufe des Jahres versuchten viele Wissenschaftler erfolglos, anhand von Piazzis Beobachtungen die Bahn zu berechnen – unter der Annahme einer Kreisbahn, denn nur für solche konnten damals die Bahnelemente aus beobachteten Himmelspositionen mathematisch ermittelt werden. Der 24-jährige Gauß hingegen konnte auch elliptische Bahnen aus drei Einzelbeobachtungen berechnen. Seine ersten Berechnungen waren noch ohne die Methode der kleinsten Quadrate, erst als nach der Wiederentdeckung von Ceres viele neue Daten vorlagen, benutzte er diese für eine genauere Bestimmung der Bahnelemente, ohne aber Details seiner Methode offenzulegen. Als Franz Xaver von Zach und Heinrich Wilhelm Olbers im Dezember 1801 den Kleinplaneten genau an dem von Gauß vorhergesagten Ort wiederfanden, war das nicht nur ein großer Erfolg für Gauß: Piazzis Ruf, der aufgrund seiner nicht zu einer Kreisbahn passen wollenden Bahnpunkte stark gelitten hatte, war ebenfalls wiederhergestellt.
Die Grundlagen der Methode derkleinsten Quadrate hatte Gauß schon 1795 im Alter von 18 Jahren entwickelt. Basis war eine Idee von Pierre-Simon Laplace, die Beträge von Fehlern aufzusummieren, so dass sich die Fehler zu Null addieren. Gauß nahm stattdessen die Fehlerquadrate und konnte die Nullsummen-Anforderung an die Fehler weglassen. Unabhängig davon entwickelte der Franzose Adrien-Marie Legendre dieselbe Methode und veröffentlichte darüber als Erster im Jahr 1805 am Schluss eines kleinen Werkes über die Berechnung der Kometenbahnen und veröffentlichte eine zweite Abhandlung darüber im Jahr 1810. Seine Darstellung war überaus klar und einfach. Von ihm stammt der Name Méthode des moindres carrés (Methode der kleinsten Quadrate).
1809 publizierte Gauß dann im zweiten Band seines himmelsmechanischen Werkes Theoria motus corporum coelestium in sectionibus conicis solem ambientium (Theorie der Bewegung der Himmelskörper, welche in Kegelschnitten die Sonne umlaufen) das Verfahren, inklusive der Normalgleichungen und des Gaußschen Eliminationsverfahrens sowie dem Gauß-Newton-Verfahren, womit er weit über Legendre hinausging. Dabei bezeichnete er es als sein Verfahren und erwähnte, dass er es schon im Jahr 1795 (also vor Legendre) entdeckt und benutzt habe, was Legendre nachhaltig verärgerte. Er beschwerte sich in einem langen Brief an Gauß über dessen Vorgehen, worauf Gauß nie antwortete. Gauß verwies nur gelegentlich auf einen Eintrag in seinem mathematischen Tagebuch vom 17. Juni 1798 (dort findet sich der kryptische Satz in Latein: Calculus probabilitatis contra La Place defensus (Kalkül der Wahrscheinlichkeit gegen Laplace verteidigt) und sonst nichts). Laplace beurteilte die Sache so, dass Legendre die Erstveröffentlichung tätigte, Gauß die Methode aber zweifelsfrei schon vorher kannte, selbst nutzte und auch anderen Astronomen brieflich mitteilte. Die Methode der kleinsten Quadrate wurde nun schnell das Standardverfahren zur Behandlung von astronomischen oder geodätischen Datensätzen.
Gauß benutzte dann das Verfahren intensiv bei seiner Vermessung des Königreichs Hannover durch Triangulation. 1821 und 1823 erschien die zweiteilige Arbeit sowie 1826 eine Ergänzung zur Theoria combinationis observationum erroribus minimis obnoxiae (Theorie der den kleinsten Fehlern unterworfenen Kombination der Beobachtungen), in denen Gauß eine Begründung liefern konnte, weshalb sein Verfahren im Vergleich zu den anderen so erfolgreich war: Die Methode der kleinsten Quadrate ist in einer breiten Hinsicht optimal, also besser als andere Methoden. Die genaue Aussage ist als der Satz von Gauß-Markow bekannt, da dieser Teil der Arbeit von Gauß wenig Beachtung fand und schließlich im 20. Jahrhundert von Andrei Andrejewitsch Markow wiederentdeckt und bekannt gemacht wurde. Die Theoria Combinationis enthält ferner wesentliche Fortschritte beim effizienten Lösen der auftretenden linearen Gleichungssysteme, wie das Gauß-Seidel-Verfahren und die LR-Zerlegung.
Der französische Vermessungsoffizier André-Louis Cholesky entwickelte während des Ersten Weltkriegs die Cholesky-Zerlegung, die gegenüber den Lösungsverfahren von Gauß nochmal einen erheblichen Effizienzgewinn darstellte. In den 1960er Jahren entwickelte Gene Golub die Idee, die auftretenden linearen Gleichungssysteme mittels QR-Zerlegung zu lösen.
Das Verfahren
Voraussetzungen
Man betrachtet eine abhängige Größe ,
die von einer Variablen
oder auch von mehreren Variablen beeinflusst wird. So hängt die Dehnung einer
Feder nur von der aufgebrachten Kraft ab, der Gewinn eines Unternehmens jedoch
von mehreren Faktoren wie Umsatz,
den verschiedenen Kosten oder dem Eigenkapital. Zur
Vereinfachung der Notation wird im Folgenden die Darstellung auf eine Variable
beschränkt. Der Zusammenhang zwischen
und den Variablen wird über eine Modellfunktion  ,
beispielsweise einer Parabel
oder einer Exponentialfunktion
,
beispielsweise einer Parabel
oder einer Exponentialfunktion
 ,
,
die von
sowie von  Funktionsparametern
Funktionsparametern  abhängt, modelliert. Diese Funktion entstammt entweder der Kenntnis des
Anwenders oder einer mehr oder weniger aufwendigen Suche nach einem Modell,
eventuell müssen dazu verschiedene Modellfunktionen angesetzt und die Ergebnisse
verglichen werden. Ein einfacher Fall auf Basis bereits vorhandener Kenntnis ist
beispielsweise die Feder, denn hier ist das Hooksche
Gesetz und damit eine lineare
Funktion mit der Federkonstanten
als einzigem Parameter Modellvoraussetzung. In schwierigeren Fällen, wie dem des
Unternehmens muss der Wahl des Funktionstyps jedoch ein komplexer Modellierungsprozess
vorausgehen.
abhängt, modelliert. Diese Funktion entstammt entweder der Kenntnis des
Anwenders oder einer mehr oder weniger aufwendigen Suche nach einem Modell,
eventuell müssen dazu verschiedene Modellfunktionen angesetzt und die Ergebnisse
verglichen werden. Ein einfacher Fall auf Basis bereits vorhandener Kenntnis ist
beispielsweise die Feder, denn hier ist das Hooksche
Gesetz und damit eine lineare
Funktion mit der Federkonstanten
als einzigem Parameter Modellvoraussetzung. In schwierigeren Fällen, wie dem des
Unternehmens muss der Wahl des Funktionstyps jedoch ein komplexer Modellierungsprozess
vorausgehen.
Um Informationen über die Parameter und damit die konkrete Art des
Zusammenhangs zu erhalten, werden zu jeweils  gegebenen Werten
gegebenen Werten  der unabhängigen Variablen
entsprechende Beobachtungswerte
der unabhängigen Variablen
entsprechende Beobachtungswerte 
 erhoben. Die Parameter
dienen zur Anpassung des gewählten Funktionstyps an diese beobachteten Werte
.
Ziel ist es nun, die Parameter
so zu wählen, dass die Modellfunktion die Daten bestmöglich approximiert.
erhoben. Die Parameter
dienen zur Anpassung des gewählten Funktionstyps an diese beobachteten Werte
.
Ziel ist es nun, die Parameter
so zu wählen, dass die Modellfunktion die Daten bestmöglich approximiert.
Gauß und Legendre hatten die Idee, Verteilungsannahmen
über die Messfehler dieser Beobachtungswerte zu machen. Sie sollten im
Durchschnitt Null sein, eine gleichbleibende Varianz haben und
von jedem anderen Messfehler stochastisch
unabhängig sein. Man verlangt damit, dass in den Messfehlern keinerlei
systematische Information mehr steckt, sie also rein zufällig um Null schwanken.
Außerdem sollten die Messfehler normalverteilt
sein, was zum einen wahrscheinlichkeitstheoretische
Vorteile hat und zum anderen garantiert, dass Ausreißer
in
so gut wie ausgeschlossen sind.
Um unter diesen Annahmen die Parameter
zu bestimmen, ist es im Allgemeinen notwendig, dass deutlich mehr Datenpunkte
als Parameter vorliegen, es muss also  gelten.
gelten.
Minimierung der Summe der Fehlerquadrate
Das Kriterium zur Bestimmung der Approximation sollte so gewählt werden, dass große Abweichungen der Modellfunktion von den Daten stärker gewichtet werden als kleine. Sofern keine Lösung ganz ohne Abweichungen möglich ist, dann ist der Kompromiss mit der insgesamt geringsten Abweichung das beste allgemein gültige Kriterium.
Dazu wird die Summe der Fehlerquadrate, die auch als Fehlerquadratsumme
bezeichnet wird, als die Summe der quadrierten Differenzen zwischen den Werten
der Modellkurve  und den Daten
definiert. In Formelschreibweise mit
und den Daten
definiert. In Formelschreibweise mit  und
und  ergibt sich
ergibt sich

Es sollen dann diejenigen Parameter
ausgewählt werden, bei denen die Summe der Fehlerquadrate minimal wird:

Wie genau dieses Minimierungsproblem gelöst wird, hängt von der Art der Modellfunktion ab.
Wird die Fehlerquadratsumme für einen externen Datensatz vorhergesagt, so spricht man von der PRESS-Statistik (predictive residual sum of squares).
Lineare Modellfunktion
Lineare Modellfunktionen sind Linearkombinationen aus beliebigen, im Allgemeinen nicht-linearen Basisfunktionen. Für solche Modellfunktionen lässt sich das Minimierungsproblem auch analytisch über einen Extremwertansatz ohne iterative Annäherungsschritte lösen. Zunächst werden einige einfache Spezialfälle und Beispiele gezeigt.
Spezialfall einer einfachen linearen Ausgleichsgeraden
Herleitung und Verfahren
Eine einfache Modellfunktion mit zwei linearen Parametern stellt das Polynom erster Ordnung

dar. Gesucht werden zu
gegebenen Messwerten  die Koeffizienten
die Koeffizienten  und
und  der bestangepassten Geraden. Die Abweichungen
der bestangepassten Geraden. Die Abweichungen  zwischen der gesuchten Geraden und den jeweiligen Messwerten
zwischen der gesuchten Geraden und den jeweiligen Messwerten

nennt man Anpassungsfehler oder Residuen.
Gesucht sind nun die Koeffizienten
und
mit der kleinsten Summe der Fehlerquadrate

Der große Vorteil des Ansatzes mit diesem Quadrat der Fehler wird sichtbar,
wenn man diese Minimierung mathematisch durchführt: Die Summenfunktion wird als
Funktion der beiden Variablen
und
aufgefasst (die eingehenden Messwerte sind dabei numerische Konstanten), dann
die Ableitung
(genauer: partielle
Ableitungen) der Funktion nach diesen Variablen gebildet und von dieser
Ableitung schließlich die Nullstelle
gesucht. Es ergibt sich das lineare
Gleichungssystem

mit der Lösung
 und
und  ,
,
wobei  die empirische
Kovarianz und
die empirische
Kovarianz und  die empirische
Varianz darstellt. Dabei ist
die empirische
Varianz darstellt. Dabei ist  das arithmetische
Mittel der -Werte,
das arithmetische
Mittel der -Werte,
 entsprechend. Die Lösung für
kann mit Hilfe des Verschiebungssatzes
auch in nicht-zentrierter Form
entsprechend. Die Lösung für
kann mit Hilfe des Verschiebungssatzes
auch in nicht-zentrierter Form

angegeben werden. Diese Ergebnisse können auch mit Funktionen einer reellen Variablen, also ohne partielle Ableitungen, hergeleitet werden.
Beispiel mit einer Ausgleichsgeraden
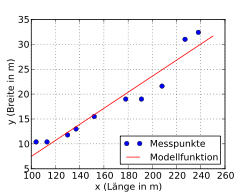
Folgendes Beispiel soll das Approximieren der linearen Funktion  zeigen. Es wurden zufällig 10 Kriegsschiffe ausgewählt und bezüglich mehrerer
Merkmale, darunter Länge (m) und Breite (m), analysiert. Es soll untersucht
werden, ob die Breite eines Kriegsschiffs möglicherweise in einem festen Bezug
zur Länge steht.
zeigen. Es wurden zufällig 10 Kriegsschiffe ausgewählt und bezüglich mehrerer
Merkmale, darunter Länge (m) und Breite (m), analysiert. Es soll untersucht
werden, ob die Breite eines Kriegsschiffs möglicherweise in einem festen Bezug
zur Länge steht.
Das Streudiagramm zeigt, dass zwischen Länge und Breite eines Schiffs ein ausgeprägter linearer Zusammenhang besteht. Es wird also als Modellfunktion eine Ausgleichsgerade genommen und mit Hilfe der Methode der kleinsten Quadrate errechnet. Man erhält nun analog zum oben angegebenen Fall zunächst

und entsprechend

In der folgenden Tabelle sind die Daten zusammen mit den Zwischenergebnissen aufgeführt.
| Nummer | Länge (m) | Breite (m) |  |
 |
||
|---|---|---|---|---|---|---|
 > > |
|
|
 |
 |
 |
 |
| 1 | 208 | 21,6 | 40,2 | 3,19 | 128,238 | 1616,04 |
| 2 | 152 | 15,5 | −15,8 | −2,91 | 45,978 | 249,64 |
| 3 | 113 | 10,4 | −54,8 | −8,01 | 438,948 | 3003,04 |
| 4 | 227 | 31,0 | 59,2 | 12,59 | 745,328 | 3504,64 |
| 5 | 137 | 13,0 | −30,8 | −5,41 | 166,628 | 948,64 |
| 6 | 238 | 32,4 | 70,2 | 13,99 | 982,098 | 4928,04 |
| 7 | 178 | 19,0 | 10,2 | 0,59 | 6,018 | 104,04 |
| 8 | 104 | 10,4 | −63,8 | −8,01 | 511,038 | 4070,44 |
| 9 | 191 | 19,0 | 23,2 | 0,59 | 13,688 | 538,24 |
| 10 | 130 | 11,8 | −37,8 | −6,61 | 249,858 | 1428,84 |
| Σ | 1678 | 184,1 | 0,0 | 0,00 | 3287,820 | 20391,60 |
Damit bestimmt man
als

so dass man sagen könnte, mit jedem Meter Länge wächst ein Kriegsschiff im
Durchschnitt etwa 16 Zentimeter in die Breite. Das Absolutglied
ergibt sich als

Die Anpassung der Punkte ist recht gut. Im Mittel beträgt die Abweichung zwischen der vorhergesagten Breite mit Hilfe des Merkmals Länge und der beobachteten Breite 2,1 m. Auch das Bestimmtheitsmaß, als normierter Koeffizient, ergibt einen Wert von ca. 92 % (100 % würde einer mittleren Abweichung von 0 m entsprechen); zur Berechnung siehe das Beispiel zum Bestimmtheitsmaß.
Einfache polynomiale Ausgleichskurven
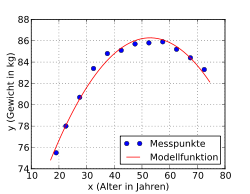
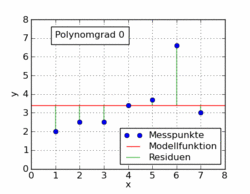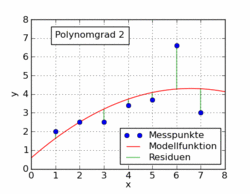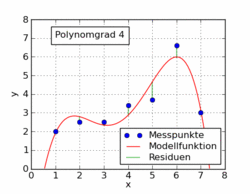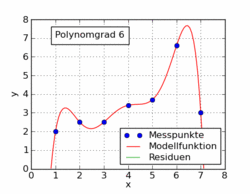
Allgemeiner als eine lineare Ausgleichsgerade sind Ausgleichspolynome

die nun anhand eines Beispiels illustriert werden (auch solche Ausgleichspolynomansätze lassen sich – zusätzlich zur iterativen Lösung – analytisch über einen Extremwertansatz lösen).
Als Ergebnisse der Mikrozensus-Befragung
durch das statistische
Bundesamt sind die durchschnittlichen
Gewichte von Männern nach Altersklassen gegeben (Quelle: Statistisches
Bundesamt, Wiesbaden 2009). Für die Analyse wurden die Altersklassen durch die
Klassenmitten ersetzt. Es soll die Abhängigkeit der Variablen Gewicht ()
von der Variablen Alter ()
analysiert werden.
Das Streudiagramm lässt auf eine annähernd parabolische Beziehung zwischen
und
schließen, welche sich häufig gut durch ein Polynom annähern lässt. Es wird ein
polynomialer Ansatz der Form

versucht. Als Lösung ergibt sich das Polynom 4. Grades
 .
.
Die Messpunkte weichen im Mittel (Standardabweichung) 0,19 kg von der Modellfunktion ab. Reduziert man den Grad des Polynoms auf 3, erhält man die Lösung

mit einer mittleren Abweichung von 0,22 kg und beim Polynomgrad 2 die Lösung

mit einer mittleren Abweichung von 0,42 kg. Wie zu erkennen ist, ändern sich beim Wegfallen der höheren Terme die Koeffizienten der niedrigeren Terme. Die Methode versucht, das Beste aus jeder Situation herauszuholen. Entsprechend werden die fehlenden höheren Terme mit Hilfe der niedrigeren Terme so gut wie möglich ausgeglichen, bis das mathematische Optimum erreicht ist. Mit dem Polynom zweiten Grades (Parabel) wird der Verlauf der Messpunkte noch sehr gut beschrieben (siehe Abbildung).
Spezialfall einer linearen Ausgleichsfunktion mit mehreren Variablen
Ist die Modellfunktion ein mehrdimensionales Polynom erster Ordnung, besitzt
also statt nur einer Variablen
mehrere unabhängige Modellvariablen  ,
erhält man eine lineare Funktion der Form
,
erhält man eine lineare Funktion der Form

die auf die Residuen

führt und über den Minimierungsansatz

gelöst werden kann.
Der allgemeine lineare Fall
f(x1, x2) =
 0
+ 1x11
+ 2x12
+ 3x21
+ 4x11x21
+ 5x12x21
+ 6x22
+ 7x11x22
+ 8x12x22
0
+ 1x11
+ 2x12
+ 3x21
+ 4x11x21
+ 5x12x21
+ 6x22
+ 7x11x22
+ 8x12x22Im Folgenden soll der allgemeine Fall von beliebigen linearen
Modellfunktionen mit beliebiger Dimension gezeigt werden. Zu einer gegebenen
 -dimensionalen
Messwertfunktion
-dimensionalen
Messwertfunktion

mit
unabhängigen Variablen sei eine optimal angepasste lineare Modellfunktion

gesucht, deren quadratische Abweichung dazu minimal sein soll.
sind dabei die Funktionskoordinaten,
die zu bestimmenden linear eingehenden Parameter und  beliebige zur Anpassung an das Problem gewählte linear unabhängige
Funktionen.
beliebige zur Anpassung an das Problem gewählte linear unabhängige
Funktionen.
Bei
gegebenen Messpunkten

erhält man die Anpassungsfehler

oder in Matrixschreibweise

wobei der Vektor  die
zusammenfasst, die Matrix
die
zusammenfasst, die Matrix
 die Basisfunktionswerte
die Basisfunktionswerte  ,
der Parametervektor
die Parameter
und der Vektor
die Beobachtungen .
,
der Parametervektor
die Parameter
und der Vektor
die Beobachtungen .
Das Minimierungsproblem kann dann mithilfe der euklidischen Norm wie folgt formuliert werden:
 .
.
Lösung des Minimierungsproblems
Herleitung und Verfahren
Das Minimierungsproblem ergibt sich wie im allgemeinen linearen Fall gezeigt als

Dieses Problem ist immer lösbar. Hat die Matrix
vollen Rang,
so ist die Lösung sogar eindeutig. Die partiellen
Ableitungen bezüglich der
und Nullsetzen derselben zum Bestimmen eines Extremums ergeben ein lineares
System von Normalgleichungen (auch Normalengleichungen)

das die Lösung des Minimierungsproblems liefert und im Allgemeinen numerisch
gelöst werden muss. Die Matrix  ist positiv definit, so dass es sich beim gefundenen Extremum um ein Minimum
handelt.
Damit kann das Lösen des Minimierungsproblems der linearen Modellfunktionen auf
das Lösen eines Gleichungssystems reduziert werden. Im einfachen Fall einer
Ausgleichsgeraden kann dessen Lösung, wie gezeigt wurde, sogar direkt als
einfache Formel angegeben werden.
ist positiv definit, so dass es sich beim gefundenen Extremum um ein Minimum
handelt.
Damit kann das Lösen des Minimierungsproblems der linearen Modellfunktionen auf
das Lösen eines Gleichungssystems reduziert werden. Im einfachen Fall einer
Ausgleichsgeraden kann dessen Lösung, wie gezeigt wurde, sogar direkt als
einfache Formel angegeben werden.
Alternativ lassen sich die Normalgleichungen in der Darstellung

ausschreiben, wobei  das Standardskalarprodukt
symbolisiert. Die Basisfunktionen
das Standardskalarprodukt
symbolisiert. Die Basisfunktionen  sind als Vektoren
sind als Vektoren  zu lesen mit den
diskreten Stützstellen am Ort der Beobachtungen
zu lesen mit den
diskreten Stützstellen am Ort der Beobachtungen  .
.
Ferner lässt sich das Minimierungsproblem mit einer Singulärwertzerlegung gut analysieren. Diese motivierte auch den Ausdruck der Pseudoinversen, einer Verallgemeinerung der normalen Inversen einer Matrix. Diese liefert dann eine Sichtweise auf nichtquadratische lineare Gleichungssysteme, die einen nicht stochastisch, sondern algebraisch motivierten Lösungsbegriff erlaubt.
Numerische Behandlung der Lösung
Zur numerischen Lösung des Problems gibt es zwei Wege. Zum einen können die Normalgleichungen

gelöst werden, die eindeutig lösbar sind, falls die Matrix
vollen Rang hat. Ferner hat die Systemmatrix
die Eigenschaft, positiv
definit zu sein, ihre Eigenwerte
sind also alle positiv. Zusammen mit der Symmetrie
von
kann dies beim Einsatz von numerischen
Verfahren zur Lösung ausgenutzt werden: beispielsweise mit der Cholesky-Zerlegung
oder dem CG-Verfahren.
Da beide Methoden von der Kondition
der Matrix stark beeinflusst werden, ist dies manchmal keine empfehlenswerte
Herangehensweise: Ist schon A schlecht konditioniert, so ist
quadratisch schlecht konditioniert. Dies führt dazu, dass Rundungsfehler so weit
verstärkt werden können, dass sie das Ergebnis unbrauchbar machen.
Zum anderen liefert das ursprüngliche Minimierungsproblem eine stabilere Alternative, da es bei kleinem Wert des Minimums eine Kondition in der Größenordnung der Kondition von A, bei großen Werten des Quadrats der Kondition von A hat. Um die Lösung zu berechnen wird eine QR-Zerlegung verwendet, die mit Householdertransformationen oder Givens-Rotationen erzeugt wird. Grundidee ist, dass orthogonale Transformationen die euklidische Norm eines Vektors nicht verändern. Damit ist

für jede orthogonale
Matrix  .
Zur Lösung des Problems kann also eine QR-Zerlegung von
berechnet werden, wobei man die rechte Seite direkt mittransformiert. Dies führt
auf eine Form
.
Zur Lösung des Problems kann also eine QR-Zerlegung von
berechnet werden, wobei man die rechte Seite direkt mittransformiert. Dies führt
auf eine Form

mit  wobei
wobei  eine rechte obere Dreiecksmatrix
ist. Die Lösung des Problems ergibt sich somit durch die Lösung des
Gleichungssystems
eine rechte obere Dreiecksmatrix
ist. Die Lösung des Problems ergibt sich somit durch die Lösung des
Gleichungssystems

Die Norm des Minimums ergibt sich dann aus den restlichen Komponenten der
transformierten rechten Seite  da die dazugehörigen Gleichungen aufgrund der Nullzeilen in
da die dazugehörigen Gleichungen aufgrund der Nullzeilen in  nie erfüllt werden können.
nie erfüllt werden können.
In der statistischen Regressionsanalyse
spricht man bei mehreren gegebenen Variablen  von multipler Regression. Der Ansatz ist auch als OLS (ordinary least
squares) bekannt, im Gegensatz zu GLS (generalised least squares),
dem multiplen linearen Regressionsmodell bei Fehlertermen, die von der
Verteilungsannahme wie Unkorreliertheit und Homoskedastie abweichen.
Dagegen liegen bei multivariater
Regression für jede Beobachtung
von multipler Regression. Der Ansatz ist auch als OLS (ordinary least
squares) bekannt, im Gegensatz zu GLS (generalised least squares),
dem multiplen linearen Regressionsmodell bei Fehlertermen, die von der
Verteilungsannahme wie Unkorreliertheit und Homoskedastie abweichen.
Dagegen liegen bei multivariater
Regression für jede Beobachtung
 viele -Werte
vor, so dass statt eines Vektors eine
viele -Werte
vor, so dass statt eines Vektors eine  -Matrix
-Matrix
 vorliegt. Die linearen Regressionsmodelle sind in der Statistik
wahrscheinlichkeitstheoretisch intensiv erforscht worden. Besonders in der Ökonometrie werden
beispielsweise komplexe rekursiv
definierte lineare Strukturgleichungen
analysiert, um volkswirtschaftliche
Systeme zu modellieren.
vorliegt. Die linearen Regressionsmodelle sind in der Statistik
wahrscheinlichkeitstheoretisch intensiv erforscht worden. Besonders in der Ökonometrie werden
beispielsweise komplexe rekursiv
definierte lineare Strukturgleichungen
analysiert, um volkswirtschaftliche
Systeme zu modellieren.
Probleme mit Nebenbedingungen
Häufig sind Zusatzinformationen an die Parameter bekannt, die durch Nebenbedingungen formuliert werden, die dann in Gleichungs- oder Ungleichungsform vorliegen. Gleichungen tauchen beispielsweise auf, wenn bestimmte Datenpunkte interpoliert werden sollen. Ungleichungen tauchen häufiger auf, in der Regel in der Form von Intervallen für einzelne Parameter. Im Einführungsbeispiel wurde die Federkonstante erwähnt, diese ist immer größer Null und kann für den konkret betrachteten Fall immer nach oben abgeschätzt werden.
Im Gleichungsfall können diese bei einem sinnvoll gestellten Problem genutzt werden, um das ursprüngliche Minimierungsproblem in eines einer niedrigereren Dimension umzuformen, dessen Lösung die Nebenbedingungen automatisch erfüllt.
Schwieriger ist der Ungleichungsfall. Hier ergibt sich bei linearen Ungleichungen das Problem
 mit
mit  ,
,

wobei die Ungleichungen komponentenweise gemeint sind. Dieses Problem ist als konvexes und quadratisches Optimierungsproblem eindeutig lösbar und kann beispielsweise mit Methoden zur Lösung solcher angegangen werden.
Quadratische Ungleichungen ergeben sich beispielsweise bei der Nutzung einer Tychonow-Regularisierung zur Lösung von Integralgleichungen. Die Lösbarkeit ist hier nicht immer gegeben. Die numerische Lösung kann beispielsweise mit speziellen QR-Zerlegungen erfolgen.
Nichtlineare Modellfunktionen
Grundgedanke und Verfahren
Mit dem Aufkommen leistungsfähiger Rechner gewinnt insbesondere die
nichtlineare Regression an Bedeutung. Hierbei gehen die Parameter nichtlinear in
die Funktion ein. Nichtlineare Modellierung ermöglicht im Prinzip die Anpassung
von Daten an jede Gleichung der Form  .
Da diese Gleichungen Kurven
definieren, werden die Begriffe nichtlineare Regression und „curve fitting“
zumeist synonym gebraucht.
.
Da diese Gleichungen Kurven
definieren, werden die Begriffe nichtlineare Regression und „curve fitting“
zumeist synonym gebraucht.
Manche nichtlineare Probleme lassen sich durch geeignete Substitution in lineare überführen und sich dann wie oben lösen. Ein multiplikatives Modell von der Form

lässt sich beispielsweise durch Logarithmieren in ein additives System überführen. Dieser Ansatz findet unter Anderem in der Wachstumstheorie Anwendung.
Im Allgemeinen ergibt sich bei nichtlinearen Modellfunktionen ein Problem der Form

mit einer nichtlinearen Funktion .
Partielle Differentiation ergibt dann ein System von Normalgleichungen, das
nicht mehr analytisch gelöst werden kann. Eine numerische Lösung kann hier
iterativ mit dem Gauß-Newton-Verfahren
erfolgen. Jenes hat allerdings den Nachteil, dass die Konvergenz des Verfahrens
nicht gesichert ist.
Aktuelle Programme arbeiten häufig mit einer Variante, dem Levenberg-Marquardt-Algorithmus. Bei diesem Verfahren ist zwar die Konvergenz ebenfalls nicht gesichert, jedoch wird durch eine Regularisierung die Monotonie der Näherungsfolge garantiert. Zudem ist das Verfahren bei größerer Abweichung der Schätzwerte toleranter als die Ursprungsmethode. Beide Verfahren sind mit dem Newton-Verfahren verwandt und konvergieren meist quadratisch, in jedem Schritt verdoppelt sich also die Zahl der korrekten Nachkommastellen.
Wenn die Differentiation auf Grund der Komplexität der Zielfunktion zu aufwändig ist, stehen eine Reihe anderer Verfahren als Ausweichlösung zu Verfügung, die keine Ableitungen benötigen, siehe bei Methoden der lokalen nichtlinearen Optimierung.
Fehlverhalten bei Nichterfüllung der Voraussetzungen
Die Methode der kleinsten Quadrate erlaubt es, unter bestimmten Voraussetzungen die wahrscheinlichsten aller Modellparameter zu berechnen. Dazu muss ein korrektes Modell gewählt worden sein, eine ausreichende Menge Messwerte vorliegen und die Abweichungen der Messwerte gegenüber dem Modellsystem müssen eine Normalverteilung bilden. In der Praxis kann die Methode jedoch auch bei Nichterfüllung dieser Voraussetzungen für diverse Zwecke eingesetzt werden. Dennoch sollte beachtet werden, dass die Methode der kleinsten Quadrate unter bestimmten ungünstigen Bedingungen völlig unerwünschte Ergebnisse liefern kann. Beispielsweise sollten keineAusreißer in den Messwerten vorliegen, da diese das Schätzergebnis verzerren. Außerdem ist Multikollinearität zwischen den zu schätzenden Parametern ungünstig, da diese numerische Probleme verursacht. Im Übrigen können auch Regressoren, die weit von den anderen entfernt liegen, die Ergebnisse der Ausgleichsrechnung stark beeinflussen. Man spricht hier von Werten mit großer Hebelkraft (High Leverage Value).
Multikollinearität
Multikollinearität
entsteht, wenn die Messreihen zweier gegebener Variablen
und
sehr hoch korreliert
sind, also fast linear abhängig sind. Im linearen Fall bedeutet dies, dass die
Determinante der
Normalgleichungsmatrix
sehr klein und die Norm der Inversen umgekehrt sehr groß, die Kondition von
ist also stark beeinträchtigt. Die Normalgleichungen sind dann numerisch schwer
zu lösen. Die Lösungswerte können unplausibel groß werden und bereits kleine
Änderungen in den Beobachtungen bewirken große Änderungen in den
Schätzwerten.
Ausreißer
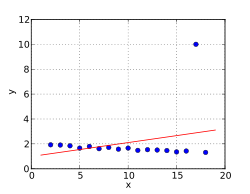
Der Wert zieht die Gerade nach oben
Als Ausreißer sind Datenwerte definiert, die „nicht in eine Messreihe passen“. Diese Werte beeinflussen die Berechnung der Parameter stark und verfälschen das Ergebnis. Um dies zu vermeiden, müssen die Daten auf fehlerhafte Beobachtungen untersucht werden. Die entdeckten Ausreißer können beispielsweise aus der Messreihe ausgeschieden werden oder es sind alternative ausreißerresistente Berechnungsverfahren wie gewichtete Regression oder das Drei-Gruppen-Verfahren anzuwenden.
Im ersten Fall wird nach der ersten Berechnung der Schätzwerte durch statistische Tests geprüft, ob Ausreißer in einzelnen Messwerten vorliegen. Diese Messwerte werden dann ausgeschieden und die Schätzwerte erneut berechnet. Dieses Verfahren eignet sich dann, wenn nur wenige Ausreißer vorliegen.
Bei der gewichteten Regression werden die abhängigen Variablen
in Abhängigkeit von ihren Residuen
gewichtet. Ausreißer, d.h. Beobachtungen mit großen Residuen, erhalten ein
geringes Gewicht, das je nach Größe des Residuums abgestuft sein kann. Beim
Algorithmus nach Frederick Mosteller und John W. Tukey (1977), der als
„biweighting“ bezeichnet wird, werden unproblematische Werte mit 1 und Ausreißer
mit 0 gewichtet, was die Unterdrückung des Ausreißers bedingt. Bei der
gewichteten Regression sind in der Regel mehrere Iterationsschritte
erforderlich, bis sich die Menge der erkannten Ausreißer nicht mehr ändert.
Verallgemeinerte Kleinste-Quadrate-Modelle
Weicht man die starken Anforderungen im Verfahren an die Residuen (Fehlerterme) auf, erhält man so genannte verallgemeinerte Kleinste-Quadrate-Ansätze. Wichtige Spezialfälle haben dann wieder eigene Namen, etwa die gewichteten kleinsten Quadrate (engl. weighted least squares (WLS)), bei denen die Fehler zwar weiter als unkorreliert angenommen werden, aber nicht mehr von gleicher Varianz. Dies führt auf ein Problem der Form

wobei D eine Diagonalmatrix ist. Variieren die Varianzen stark, so haben die entsprechenden Normalgleichungen eine sehr große Kondition, weswegen das Problem direkt gelöst werden sollte.
Nimmt man noch weiter an, dass die Fehler in den Messdaten auch in der Modellfunktion berücksichtigt werden sollten, ergeben sich die „totalen kleinsten Quadrate“ in der Form

wobei  der Fehler im Modell und
der Fehler in den Daten ist.
der Fehler im Modell und
der Fehler in den Daten ist.
Schließlich gibt es noch die Möglichkeit, keine Normalverteilung zugrunde zu legen. Dies entspricht beispielsweise der Minimierung nicht in der euklidischen Norm, sondern der Summennorm. Solche Modelle sind Thema der Regressionsanalyse.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 28.06. 2025