Kanalkodierung
Als Kanalkodierung (auch Kanalcodierung) bezeichnet man in der Nachrichtentechnik das Verfahren, digitale Daten bei der Übertragung über gestörte Kanäle durch Hinzufügen von Redundanz gegen Übertragungsfehler zu schützen.
Die mathematischen Grundlagen für die Kanalkodierung stellt die Kodierungstheorie bereit.
Zu unterscheiden ist die Kanalkodierung von der Quellenkodierung, welche Redundanz vermindert, und von der Leitungskodierung, welche eine spektrale Anpassung an die Anforderungen des Übertragungskanals vornimmt.
Verfahren
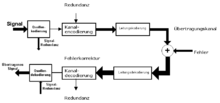
Die Kanalkodierung fügt den Daten am Eingang eines Übertragungskanals Redundanz hinzu und dekodiert die Daten an seinem Ausgang. Wenn die Zusatzinformationen lediglich auf einen Fehler hindeuten und eine Neuübertragung der Daten erfordern, spricht man von Rückwärtsfehlerkorrektur. Genügt die Redundanzinformation, den Fehler zu korrigieren, so handelt es sich um eine Vorwärtsfehlerkorrektur. Eine effiziente Kanalkodierung erhöht das Signal-Rausch-Verhältnis bei unveränderter Bitfehlerhäufigkeit. Je nach Kanalkodierungsverfahren beträgt der Codegewinn mehrere dB.
Eine wesentliche Eigenschaft eines Kanalkodes ist seine (Kode-) Coderate:

wobei
 die Anzahl der Symbole am Eingang des
Kodierers (Informationssymbole) ist und
die Anzahl der Symbole am Eingang des
Kodierers (Informationssymbole) ist und die Anzahl der Symbole am Ausgang des
Kodierers (Codesymbole).
die Anzahl der Symbole am Ausgang des
Kodierers (Codesymbole).
Es werden also Informationssymbole auf Codesymbole abgebildet. Eine kleine Rate
(großes ) bedeutet einen höheren Anteil der Codesymbole an
den übertragenden Symbolen, also eine kleinere Datenübertragungsrate.
Üblicherweise kann ein Kanalcode mit einer niedrigeren Koderate mehr Fehler korrigieren als ein vergleichbarer Kanalkode mit einer
hohen Koderate – es ist also ein Abtausch zwischen Datenübertragungsrate und Fehlerkorrekturfähigkeit möglich.
Codeverkettung
Durch geschicktes Verketten von Codes (z.B. bei Turbo-Codes) kann die Korrekturfähigkeit des so entstandenen verketteten Codes sehr viel höher sein als die der einzelnen Codes (Komponentencodes).
Punktierung
Unter Punktierung versteht man
das gezielte Streichen einzelner Codesymbole, so dass die Anzahl der übertragenden Codesymbole von
auf  reduziert wird. Damit ergibt sich für
den punktierten Code eine höhere Rate
reduziert wird. Damit ergibt sich für
den punktierten Code eine höhere Rate  .
Punktierung ermöglicht die Nutzung desselben Codierer/Decodierer-Paares für Codes unterschiedlicher Raten.
.
Punktierung ermöglicht die Nutzung desselben Codierer/Decodierer-Paares für Codes unterschiedlicher Raten.
Geschichte
Shannons Pionierarbeit 1948
Die Veröffentlichung von Claude E. Shannons Pionierarbeit zur Informationstheorie A mathematical Theory of Communication stellt gleichzeitig die Geburtsstunde der Kanalkodierung 1948 dar. Zwar gab es vorher schon Bemühungen, Nachrichten gegen Fehlübertragung zu schützen, diese gingen jedoch nicht über eine einfache Mehrfachübertragung (Wiederholungscode) hinaus, was sich als ein Kanalcode ohne Codegewinn entpuppte. Shannon zeigte, dass jeder Übertragungskanal durch eine Kanalkapazität beschrieben werden kann, die die Informationsrate, die zuverlässig über einem Kanal erreicht werden kann, nach oben begrenzt. Zuverlässig heißt in diesem Zusammenhang, dass die Symbolfehlerrate nicht über einem festgelegten Grenzwert liegt. Er zeigte außerdem, dass Kanalcodes existieren, die beliebig nahe an diese Kapazität herankommen (Kanalkodierungstheorem). Der Existenzbeweis gibt jedoch weder eine praktische Konstruktion für Kanalcodes an, noch wie man diese effizient dekodiert. Tatsächlich sind die von Shannon beschriebenen Codes unendlich lang und haben einen zufälligen Charakter.
Erste praktische Konstruktionen in den 1950er-Jahren
Bereits kurz nach Shannons Veröffentlichung wurden die ersten praktischen Kanalcodes entwickelt. Als besonders wegweisend sind hier die Arbeiten von Marcel J. E. Golay (Golay-Code, 1949) und Richard W. Hamming (Hamming-Code, 1950). Hammings Arbeit wurde dabei von der Unzuverlässigkeit der damaligen Relais-Computer motiviert, in denen es häufig zu Bitfehlern kam. Der (7,4)-Hamming-Code kann mit nur 3 bit Redundanz einen beliebigen Bitfehler in 4 Nachrichtenbits korrigieren.
Irving S. Reed und
David E. Muller entwickelten 1954 die heute als
Reed-Muller-Codes bekannten Kanalcodes.
Reed-Muller-Codes haben den Vorteil, dass sie auch für große Blocklängen konstruiert werden können und dabei vergleichsweise
viele Fehler korrigieren. Eine Unterklasse von Reed-Muller-Codes sind die
Hadamard-Codes, die als erste Kanalcodes für
die Datenübertragung von Raumsonden (Mariner-9) in die
Geschichte eingingen.
1960er-Jahre: Algebraische Codes
Einen Meilenstein stellen die Reed-Solomon-Codes
(nach Irving S. Reed und
Gustave Solomon, 1960) und deren
Untergruppe BCH-Codes
(nach R. C. Bose,
D. K. Ray-Chaudhuri und
A. Hocquenghem) dar. Die Grundidee ist hier, Codesymbole aus einem
endlichen Körper (anstatt Bits) zu
verwenden, und Nachrichten als Polynome über diesem Körper
zu betrachten, und Codeworte als Auswertung an der Polynome an verschiedenen Stellen. Dabei gelingt es,
die Codeworte maximal voneinander zu separieren
(Maximum Distance Separable Code, MDS-Code).
Reed-Solomon-Codes haben daher ausgezeichnete Fehlerkorrektureigenschaften und werden seitdem in vielen Anwendungen, wie
CDs,
DVDs,
DVB und
QR-Codes, eingesetzt. Ein effizienter Dekodierverfahren
(Berlekamp-Massey-Algorithmus) wurde von
Elvyn Berlekamp und
James Massey zwischen 1968 und 1969 entwickelt.
1970er- und 1980er-Jahre: Faltungscodes und Codeverkettung
Mit den Faltungscodes beschrieb Peter Elias bereits 1955 die ersten datenstrombasierten Codes, also Kanalcodes ohne eine festgelegte Blocklänge. Diese fanden jedoch erst mit dem effizienten Dekodieralgorithmus von Andrew Viterbi (Viterbi-Algorithmus, 1967) praktische Anwendung. Der Viterbi-Algorithmus erlaubte es erstmals, einfach eine sogenannte Soft-Input-Dekodierung anzuwenden, bei der (statt hart-entschiedenen Bitwerten) Wahrscheinlichkeiten für jedes Symbol berücksichtigt werden. Somit fanden Faltungscodes besonders Funkanwendungen wie GSM und WLAN (802.11a/g) Verwendung, bei denen diese Information zur Verfügung steht. Dennoch ist deren Fehlerkorrekturfähigkeit von der Länge des verwendeten Schieberegisters abhängig, die exponentiell in die Dekodierkomplexität eingeht.
Serielle Codeverkettung (Dave Forney, 1966) erwies sich als Schlüsseltechnologie, um immer bessere Codes mit beherrschbarem Dekodieraufwand zu entwerfen. Dabei wird eine Nachricht zunächst mit einem (äußeren) Kanalcode (meist einem algebraischer Code) und anschließend mit einem (inneren) Faltungscode kodiert. Diese Methode fand 1977 mit den Voyager-Raumsonden eine prominente Anwendung und blieb das Zugpferd der Kanalkodierung bis zur Entwicklung der Turbo-Codes.
Iterative Dekodierung seit den 1990ern
Alle bisher genannten Kanalcodes operierten noch weit weg (d.h. mehrere Dezibel im Signal-Rausch-Verhältnis) von der von Shannon aufgezeigten Kanalkapazität, und es verbreitete sich die Ansicht, dass diese nicht auf praktikable Weise erreicht werden kann. Daher war die Aufruhr groß, als die Anfang den 1990er von Claude Berrou erfundenen Turbo-Codes (in der Veröffentlichung von 1993 sind Alain Glavieux und Punya Thitimajshima Mitautoren) plötzlich diese Lücke zur Kanalkapazität bis auf einige Zehntel dB schlossen. In Turbo-Codes werden zwei parallel verkettete Faltungscodes mit einem pseudo-zufälligen Interleaver eingesetzt. Zum Dekodieren kommen zwei rückgekoppelte BCJR-Dekoder zum Einsatz – ein Prinzip, das an den Turbolader eines Verbrennungsmotors erinnert. In mehreren Iterationen tauschen beide Dekoder Information aus, um schließlich zu einem Codewort zu konvergieren. Es werden vergleichsweise kurze Schieberegister für die Faltungscodes verwendet, da bei Turbo-Codes der Interleaver dafür sorgt, dass die Codewortbits über die gesamte Länge des Codes miteinander verschränkt werden. Somit ist der Dekodieraufwand nur linear mit der Codewortlänge, was sehr lange Codes (viele Kilobit pro Codewort) erstmals praktikabel machte und damit den von Shannon erdachten Codes bereits sehr nahe kommt. Turbo-Codes fanden daraufhin Anwendung in den Mobilfunkstandards UMTS und LTE.
Ähnlich gute Leistungsfähigkeit wie Turbo-Codes wies David J.C. MacKay 1996 bei LDPC-Codes nach, die mit dem Belief-Propagation-Algorithmus ebenfalls iterativ dekodiert werden. Diese wurden zwar schon Anfang der 1960er von Robert Gallager erfunden, sie gerieten jedoch in Vergessenheit, da die damalige Technologie noch keine praktische Implementierung erlaubte. In den folgenden Jahren wurde in Arbeiten von Tom Richardson und Rüdiger Urbanke eine umfangreiche Theorie zur Konstruktion von LDPC-Codes entwickelt, sodass diese nun als Quasi-Stand der Technik in der Kanalkodierung gelten. Sie werden unter anderem im 5G-Mobilfunkstandard, neueren WLAN-Standards (802.11n und 802.11ac) und DVB-x2. In letzterem werden LDPC-Codes innere Codes mit BCH-Codes verkettet eingesetzt.
Polar Codes
Einen weiteren Fortschritt machte die Technik mit den 2008 von Erdal Arıkan eingeführten Polar-Codes. Er zeigte, dass Polar-Codes zusammen mit einem einfachen, rekursiven Dekodieralgorithmus, asymptotisch (also für eine Blocklänge, die gegen unendlich geht) die Kanalkapazität erreichen. Damit sind Polar-Codes die ersten Codes, für die dies mathematisch nachgewiesen wurde, während die gute Leistungsfähigkeit von Turbo- und LDPC-Codes lediglich experimentell belegt ist. Für kurze Blocklängen sind Polar-Codes zwar anderen Schemen unterlegen, jedoch konnte durch Verkettung einer CRC-Prüfsumme eine ähnlich gute Leistungsfähigkeit wie bei kurzen LDPC-Codes erzielt werden. Daher wurden CRC-Polar-Codes für die Steuerkanäle in 5G-Mobilfunknetzen ausgewählt.
Codeklassen
Kennt man die Fehlerarten, die in einem Übertragungskanal auftreten, kann man verschiedene Codes konstruieren, die die häufigen Fehlerarten gut, weniger häufigere Fehlerarten weniger gut korrigieren können. Die nebenstehende Abbildung zeigt eine Übersicht häufig verwendeter Codeklassen.
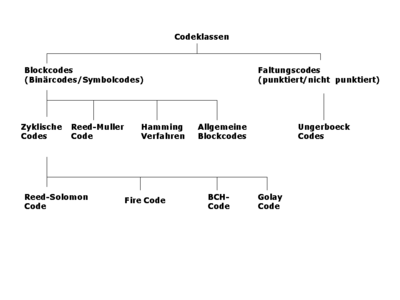
Grundsätzlich lassen sich Kanalcodes in blockbasierte und zeichenstrombasierte Codes unterteilen.
Blockbasierte Codes (Blockcodes)
Blockcodes zeichnen sich durch eine vordefinierte,
konstante Codewortlänge aus.
Algebraische Codes
Algebraische Codes basieren auf algebraischen Konstruktionen. Sie werden entworfen, um ganz bestimmte Eigenschaften, beispielsweise eine große Minimaldistanz, zu erzielen. Daher lassen sich genaue Aussagen treffen, welche Fehlerarten und wie viele Fehler sie erkennen bzw. korrigieren können.
- Hamming-Code
- Golay-Code
- Reed-Muller-Code
- Fire-Code
- Reed-Solomon-Code und BCH-Code
- Zyklische Redundanzprüfung (CRC-Code)
Codes für Iterative Dekodierung
Iterativ dekodierte Codes bezeichnet man auch als moderne Kanalcodes. Im Gegensatz zu algebraischen Codes bestimmt hier der Dekodieralgorithmus den Code-Entwurf. Diese effizienten Algorithmen erlauben sehr lange Blocklängen, womit iterativ dekodierte Codes der Shannon-Kanalkapazität am nähesten kommen können. Sie zeichnen sich durch eine meist pseudo-zufällige Konstruktion aus. Die beiden wichtigsten Vertreter dieser Codeklasse sind:
- Low-Density-Parity-Check-Code (LDPC Code)
- Turbo-Code
- Turbo Convolutional Code (zwei terminierte Faltungscodes als Basiscodes)
- Turbo-Product-Code (beliebige algebraische Codes als Basiscodes)
Codes aus der Informationstheorie
Mit den 2008 eingeführten Polar-Codes wurden Blockcodes gefunden, die auf dem informationstheoretischen Prinzip der Kanal-Polarisierung basieren. Sie können keiner der beiden obigen Klassen zugeordnet werden, sind aber eng verwandt mit dem Reed-Muller-Code.
- Polar-Code
Zeichenstrombasierte Codes
Im Gegensatz zu Blockcodes haben zeichenstrombasierte Codes keine festgelegte Blocklänge. Sie eignen sich daher für Streaming-Dienste und für Weitverkehrsnetze. Durch Terminierung können zeichenstrombasierte Codes in Blockcodes beliebiger Länge umgewandelt werden. Die wichtigsten Klassen zeichenstrombasierter Codes sind:
- Faltungscodes
- Ungerboeck-Code (auch als Trellis-Coded-Modulation bezeichnet)
- Staircase Codes
- Räumlich verkettete LDPC-Codes (Spatially-Coupled LDPC-Codes, auch LDPC-Faltungscodes genannt)
Beispiele
- Kanalfehler abhängig von Quellkodierung
- Die Festlegung eines Kodierungsverfahren berücksichtigt sowohl die Qualitätsansprüche an das zu übertragende Signal als auch die Eigenschaften des Kanals. Wird beispielsweise bei einem unkomprimiert übertragenen Fernsehsignal ein Bit auf dem Übertragungsweg verfälscht, so ändert sich nur ein Pixel eines (Halb-)Bildes. Tritt der gleiche Fehler bei einem komprimierten MPEG-codierten Fernsehsignal auf, verfälscht er einen ganzen Makroblock von einer bestimmten Anzahl von Bildpunkten (je nachdem, wie groß der Makroblock ist: 16×16 bis hin zu 4×4 Pixel) und die darauffolgenden Bilder; erst wenn wieder ein unabhängig codiertes Frame (I-Frame) kommt, ist der Fehler nicht mehr vorhanden.
- Beispiel Rückwärtsfehlerkorrektur
- Hinzufügen von Paritätsbits zu einem Datenwort.
- Beispiel Rückwärts-/Vorwärtsfehlerkorrektur
- ISBN-Code: Bei fehlender Übereinstimmung mit der Prüfziffer kommen nur wenige ISBN-Codes als korrekte Werte in Frage.
- Beispiel Vorwärtsfehlerkorrektur
- Angabe von Postleitzahl und Ort: eine falsch geschriebene Ortsangabe kann anhand der Postleitzahl korrigiert werden. Ebenso werden Zahlendreher in der Postleitzahl durch den Abgleich mit dem Ortsnamen erkannt.
- Beispiel GSM
- Das Telefon begrenzt den Frequenzbereich der Sprache auf ca. 4 kHz. Bei einer Abtastung mit 8 kHz bei einer Quantisierung von 8 Bit pro Abtastwert fällt ein Datenstrom von 64 kbit/s an. Die GSM-Quellcodierung reduziert ihn auf ca. 13 kbit/s. Um die Bitfehlerhäufigkeit bei der störanfälligen Funkübertragung zu begrenzen, werden dem Datenstrom Redundanzen hinzugefügt. Die Kanalkodierung erhöht die Bitrate auf 22,8 kbit/s.
Siehe auch
Literatur
- John G. Proakis, Masoud Salehi: Communication Systems Engineering. 2. Auflage. Prentice Hall, 2002, ISBN 0-13-095007-6.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 23.12. 2023