Blockcode

Blockcodes sind eine Art der Kanalkodierung der
Familie der (fehlererkennenden und) fehlerkorrigierenden Codes. Sie zeichnen sich durch eine feste Blockgröße aus
 Symbolen eines festen
Alphabets
Symbolen eines festen
Alphabets
 (bei Binärcodes
(bei Binärcodes  ) aus.
Einzelne Blocks werden im Gegensatz zu
Faltungscodes unabhängig voneinander kodiert und
dekodiert.
) aus.
Einzelne Blocks werden im Gegensatz zu
Faltungscodes unabhängig voneinander kodiert und
dekodiert.
Wichtige Eigenschaften eines Blockcodes sind die
Informationsrate
(das Verhältnis aus enthaltener Informationsmenge  zur Gesamt-Datenmenge
) sowie seine Korrekturrate
(d.h. die Fähigkeit Fehler zu erkennen und/oder zu korrigieren). Beide Eigenschaften beeinflussen einander gegenseitig und
spannen eine gemeinsame, unüberwindbare Schranke auf. Durch Optimierung kann man sich der Schranke nähern, erhält aber lange
und aufwändig zu dekodierende Codes.
Hier hat sich das Kaskadieren von Codes als praktikablere Lösung erwiesen.
zur Gesamt-Datenmenge
) sowie seine Korrekturrate
(d.h. die Fähigkeit Fehler zu erkennen und/oder zu korrigieren). Beide Eigenschaften beeinflussen einander gegenseitig und
spannen eine gemeinsame, unüberwindbare Schranke auf. Durch Optimierung kann man sich der Schranke nähern, erhält aber lange
und aufwändig zu dekodierende Codes.
Hier hat sich das Kaskadieren von Codes als praktikablere Lösung erwiesen.
Obwohl Blockcodes häufig nicht optimal im Sinne einer minimalen mittleren Codewortlänge sind, schränkt man sich oft auf Blockcodes ein. Eine weitere Spezialisierung stellen lineare Codes und systematische Codes dar.
Aufbau
Aus dem Alphabet und der Blockgröße
ergeben sich
 mögliche Worte, von denen eine
Teilmenge
mögliche Worte, von denen eine
Teilmenge  die gültigen Codeworte darstellt. Die Mächtigkeit des Alphabets
wird mit
die gültigen Codeworte darstellt. Die Mächtigkeit des Alphabets
wird mit
 bezeichnet,
sie beträgt im Falle von Binärcodes
bezeichnet,
sie beträgt im Falle von Binärcodes  .
Die Mächtigkeit des Codes
.
Die Mächtigkeit des Codes  kann bei
vielen Codes (bei linearen Codes immer) als
kann bei
vielen Codes (bei linearen Codes immer) als  mit
mit
 geschrieben werden.
Diese Codes können bei einer Blockgröße von Symbolen eine Nutzlast
geschrieben werden.
Diese Codes können bei einer Blockgröße von Symbolen eine Nutzlast
 tragen.
tragen.
Die Informationrate beträgt  ,
die Korrekturrate wird durch den (minimalen) Hamming-Abstand des Codes
,
die Korrekturrate wird durch den (minimalen) Hamming-Abstand des Codes
 limitiert.
Der Hamming-Abstand zweier Codeworte
limitiert.
Der Hamming-Abstand zweier Codeworte
 und
und
 ist hierbei die Anzahl unterschiedlicher
Symbole dieser Codeworte
ist hierbei die Anzahl unterschiedlicher
Symbole dieser Codeworte  ,
der (minimale) Hamming-Abstand
,
der (minimale) Hamming-Abstand  eines (ganzen)
Codes
ist der minimale Hamming-Abstand aller (disjunkten) Codewort-Paare, d.h.
eines (ganzen)
Codes
ist der minimale Hamming-Abstand aller (disjunkten) Codewort-Paare, d.h.
 .
Letztere beschränkt die maximale (zuverlässige) Korrekturleistung auf
.
Letztere beschränkt die maximale (zuverlässige) Korrekturleistung auf
 Symbolfehlern mit
Symbolfehlern mit
 ein.
Bei kaskadierten Korrekturverfahren spielt neben der Fehlerkorrektur auch die Fehlererkennung eine Rolle. Zum einen
erkennen Nicht-perfekte Codes
eine gewisse Menge an Mehrbit-Fehler mit
ein.
Bei kaskadierten Korrekturverfahren spielt neben der Fehlerkorrektur auch die Fehlererkennung eine Rolle. Zum einen
erkennen Nicht-perfekte Codes
eine gewisse Menge an Mehrbit-Fehler mit  ,
die sie selbst nicht mehr korrigieren können, zum anderen kann man Fehlerkorrektur-Fähigkeiten gegen weitere (garantierte)
Fehlererkennungs-Fähigkeiten
,
die sie selbst nicht mehr korrigieren können, zum anderen kann man Fehlerkorrektur-Fähigkeiten gegen weitere (garantierte)
Fehlererkennungs-Fähigkeiten  eintauschen und damit folgende
Korrektur-Stufen unterstützen:
eintauschen und damit folgende
Korrektur-Stufen unterstützen:  .
.
Für Codes haben sich in der Literatur unterschiedliche Notationen etabliert:
![{\displaystyle [n,k;d,q]}](/svg/3a9a0988ef325f77d93553b46afd8e3c52c07317.svg) oder
oder
![{\displaystyle [n,k;d]_{q}}](/svg/ec6c9dfccf00c353b46f562a9bed488610a16262.svg) ,
häufig wird das Semikolon durch ein Komma ersetzt, die eckigen Klammern durch runde Klammern.
,
häufig wird das Semikolon durch ein Komma ersetzt, die eckigen Klammern durch runde Klammern.
 wird häufig weggelassen,
gleiches gilt für das
wird häufig weggelassen,
gleiches gilt für das  der klassischen Hamming-Codes.
der klassischen Hamming-Codes.- Häufig wird statt (der Anzahl der Nutzsymbole)
die Mächtigkeit des Codes
 , d.h.
, d.h.
 oder der Code selbst angegeben
oder der Code selbst angegeben
 angegeben,
zum Teil wird diese Information in der Art der verwendeten Klammern versteckt.
angegeben,
zum Teil wird diese Information in der Art der verwendeten Klammern versteckt.
Im Weiteren wird versucht, dies wie auch die Nutzung von Variablennamen sowohl in diesem Artikel wie auch in verwandten Artikeln konsistent zu halten.
Man bezeichnet allgemein als einen
 -Code, falls
-Code, falls
- ein Alphabet mit
 ist,
ist, - der Code ist und
- der (minimalen) Hamming-Abstand
 ist.
ist.
Betrachtet man lineare Codes, so spricht man von
-Codes bzw.
-Codes,
wobei hier die Dimension von
über dem
Körper
 ist.
und
haben dabei die gleiche Bedeutung wie bei den allgemeinen Blockcodes.
ist.
und
haben dabei die gleiche Bedeutung wie bei den allgemeinen Blockcodes.
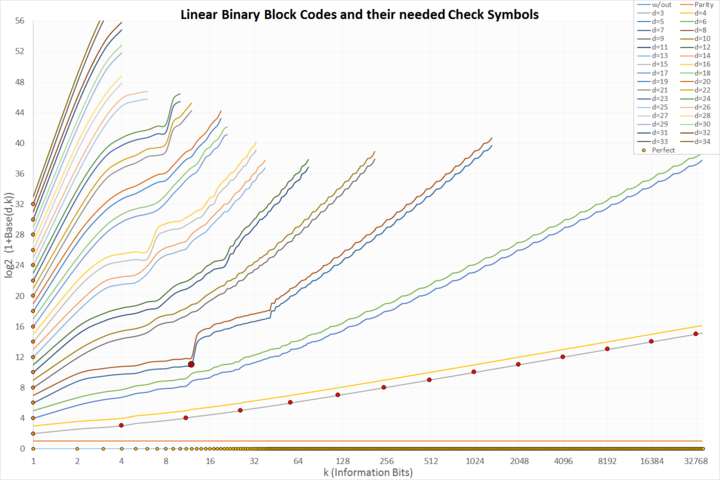
Mit Punkten markiert sind perfekte Codes:
- hellorange auf der x-Achse: trivial ungeschützte Codes
- orange, auf der y-Achse: trivial Wiederholungs-Codes
- dunkelorange, auf der Linie für d=3: klassische, perfekte Hamming-Codes
- dunkelrot und groß: der einzige perfekte binäre Golay-Code
Man interessiert sich bei gegebenem ,
und
 für eine Maximierung der Mächtigkeit des Codes,
d.h. für
für eine Maximierung der Mächtigkeit des Codes,
d.h. für  ,
da hierbei eine optimale Informationsrate für diese Parameter erzielt wird.
Allerdings gibt es günstige Parameter, die zu effizienteren Codes als ihre Nachbarparameter führen.
So fordert ein
,
da hierbei eine optimale Informationsrate für diese Parameter erzielt wird.
Allerdings gibt es günstige Parameter, die zu effizienteren Codes als ihre Nachbarparameter führen.
So fordert ein ![{\displaystyle [23,12;7,2]}](/svg/71d94bdcff52e3ce3b8b9de229b3e9049c8ee73a.svg) -Code 11 Schutzbits,
ein
-Code 11 Schutzbits,
ein ![{\displaystyle [27,13;7,2]}](/svg/f6925005f577d390cd6414c92061411488110f51.svg) -Code allerdings schon 14.
Ein
-Code allerdings schon 14.
Ein ![{\displaystyle [41,24;7,2]}](/svg/e302abf2d0d8bfaf5cd0eacb9b2e7148a041129e.svg) - kommt wie ein
- kommt wie ein
![{\displaystyle [55,38;7,2]}](/svg/78d98aeab7026fdfcc7fa2bc107503252da688f7.svg) -Code mit 17 Schutzbits aus.
-Code mit 17 Schutzbits aus.
Es gibt Abschätzungen, ob Codes möglich sein könnten oder gegen gewisse Prinzipien verstoßen:
- Singleton-Schranke (MDS-Code)
- Hamming-Schranke (Perfekter Code)
- Plotkin-Schranke
- Gilbert-Varshamov-Schranke, Johnson-Schranke, Griesmer-Schranke, Bassalygo-Elias-Schranke
- Optimaler Code
Schranken weisen darauf hin, ob Codes existieren können, nicht ob sie konstruierbar sind und wirklich existieren.
Typen von Blockcodes
Formal heißt der Code
Blockcode, wobei als Alphabet bezeichnet wird und
die Länge jedes Codewortes
 ist.
ist.
Triviale Blockcodes sind Codes
- die nur ein Wort als Code umfassen:
 .
Es lassen sich alle Übertragungsfehler erkennen, aber keine Information übertragen oder
.
Es lassen sich alle Übertragungsfehler erkennen, aber keine Information übertragen oder - die alle möglichen Worte als Code umfassen:
 .
Es lassen sich keine Übertragungsfehler erkennen, die übertragene Information ist aber maximal.
.
Es lassen sich keine Übertragungsfehler erkennen, die übertragene Information ist aber maximal.
| Bemerkungen: |
|
![{\displaystyle [n,0;2n+1,q]}](/svg/f84b1428e43878f36ed6ca90b5af60af2ad0a799.svg) -Code schreiben.
Er hat im klassischen Sinne keine Hamming-Distanz, da es keine Codepaare gibt. Es lassen sich bis zu maximal
-Code schreiben.
Er hat im klassischen Sinne keine Hamming-Distanz, da es keine Codepaare gibt. Es lassen sich bis zu maximal
 Symbolfehler im übertragenen Wort
Symbolfehler im übertragenen Wort
 korrigieren (das übertragene Codewort ist bekannt),
was eine typische Eigenschaft für Codes mit
korrigieren (das übertragene Codewort ist bekannt),
was eine typische Eigenschaft für Codes mit
 ist.
Das gleiche gilt für die Anzahl von Codes, die sich eindeutig dekodieren lassen. Die Gleichung
ist.
Das gleiche gilt für die Anzahl von Codes, die sich eindeutig dekodieren lassen. Die Gleichung
 liefert für
liefert für
 das richtige Ergebnis.
das richtige Ergebnis.![{\displaystyle [n,n;1,2]}](/svg/f7e1c55b0550bc74aac09c4fc0159c9cd3e70c0e.svg) -Code schreiben.
Er hat eine Hamming-Distanz von 1.
-Code schreiben.
Er hat eine Hamming-Distanz von 1.Lineare Blockcodes sind Codes,
wenn ein
-dimensionaler Untervektorraum von
ist.
Es existiert dann eine Basis  von
.
Fasst man diese Basis zu einer Matrix
von
.
Fasst man diese Basis zu einer Matrix

zusammen, erhält man eine Generatormatrix
dieses linearen Blockcodes.
Die Codeworte erhält man durch Multiplizieren des Eingangssignals
 mit der Generatormatrix
mit der Generatormatrix

Der Hauptvorteil linearer Code ist die einfache Codierbarkeit und die einfache Decodierbarkeit.
| Bemerkungen: |
Zur Kodierung eines Codes mit  Codeworten muss man nur noch Codeworte vorrätig halten.
Gleiches gilt für die Dekodierung mit
Codeworten muss man nur noch Codeworte vorrätig halten.
Gleiches gilt für die Dekodierung mit  vs.
. vs.
.
|
Systematische Blockcodes
sind Codes,
bei denen die Informationssymbole direkt im Block ablesbar sind
(meist am Blockanfang, siehe Abbildung am Anfang des Artikels).
Sie können gleichzeitig lineare Blockcodes sein, müssen es aber nicht.
Sie sind lineare Blockcodes, wenn neben den Informationssymbolen (die immer linear sind) auch die Prüfsymbole linear sind.
Perfekte Blockcodes sind Codes,
in denen jedes Wort  nur zu genau einem
Codewort (und nicht zu mehreren)
einen geringsten Hamming-Abstand
nur zu genau einem
Codewort (und nicht zu mehreren)
einen geringsten Hamming-Abstand
 hat.
Jedes Wort lässt sich damit eindeutig decodieren.
Der Hamming-Code ist ein Beispiel für einen perfekten Code.
hat.
Jedes Wort lässt sich damit eindeutig decodieren.
Der Hamming-Code ist ein Beispiel für einen perfekten Code.
Maximum-Distanz-Codes (MDS Codes) sind Blockcodes,
deren Codeworte den größtmöglichen Hamming-Abstand voneinander haben. Beispiele für MDS Codes sind Wiederholungscodes, Paritätscodes und Reed-Solomon-Codes.
Informationsrate von Blockcodes
Die Informationsrate (auch Coderate)
 gibt an,
wie viel Information pro Codewortsymbol im Mittel übertragen wird, sie ist also das Verhältnis von Nachrichtensymbolen zu
Codewortsymbolen. Da ein Code Redundanz hinzufügt, gilt allgemein
gibt an,
wie viel Information pro Codewortsymbol im Mittel übertragen wird, sie ist also das Verhältnis von Nachrichtensymbolen zu
Codewortsymbolen. Da ein Code Redundanz hinzufügt, gilt allgemein
 .
.
Sei
ein Blockcode und es gelte
,
das Alphabet habe also verschiedene Elemente.
Dann lautet für die Definition der Informationsrate:
 .
.
Ist z.B. ein binärer Code mit
 verschiedenen Codeworten, dann benötigt man
verschiedenen Codeworten, dann benötigt man
 Bits,
um diese eindeutig zu unterscheiden.
Bits,
um diese eindeutig zu unterscheiden.
Handelt es sich um einen linearen Code, so ist die Informationsrate:
 .
.
Beispiele für Blockcodes
Wiederholungscode
Wiederholungscodes sind lineare,
systematische ![{\displaystyle [n,1;n]}](/svg/69582b51f15eae9774e480a48572c089e8c3d079.svg) -Blockcodes
über einem beliebigen Alphabet, bei denen jedes Nachrichtensymbol n-mal wiederholt wird. Damit hat ein Wiederholungscode
die Generatormatrix
-Blockcodes
über einem beliebigen Alphabet, bei denen jedes Nachrichtensymbol n-mal wiederholt wird. Damit hat ein Wiederholungscode
die Generatormatrix

und eine Informationsrate von  .
.
Paritätscode
Paritätscodes (engl. Single Parity Check (SPC) codes) sind lineare, systematische und binäre Codes, bei denen der Nachricht ein einziges Prüfbit angefügt wird, das sich als XOR-Verknüpfung aller Nachrichtenbits ergibt. Somit hat jedes Codewort eine gerade Anzahl an „1“-Bits. Die Generatormatrix hat folgende Form:

Sie haben eine Hamming-Distanz von 2 und stellen -![{\displaystyle [n,n-1;2,2]}](/svg/93bbf225c188431ee101755866c8395269bf34bb.svg) Blockcodes dar.
Sie können einen Fehler erkennen, aber keine Fehler korrigieren.
Lineare binäre Blockcodes mit ungeradem Hamming-Abstand
Blockcodes dar.
Sie können einen Fehler erkennen, aber keine Fehler korrigieren.
Lineare binäre Blockcodes mit ungeradem Hamming-Abstand ![{\displaystyle [n,k;2m+1,2]}](/svg/488baf6174c9652ca5a90f1bee8681d133c52ffe.svg) lassen sich mit
einem zusätzlichen Paritätscode zu einem
lassen sich mit
einem zusätzlichen Paritätscode zu einem
![{\displaystyle [n+1,k;2m+2,2]}](/svg/29a4c4cf60df25a020f20df4b87a13958f6865ea.svg) -Code erweitern.
-Code erweitern.
Hadamard-Code
Hadamard Codes sind lineare nicht-systematische
Blockcodes ![{\displaystyle [2^{k},k+1;2^{k-1}]}](/svg/9ba688a56615b0eeb877852f5eebb3c34da89e21.svg) .
Die Generatormatrix hat eine sehr auffällige Form
.
Die Generatormatrix hat eine sehr auffällige Form

Sie haben eine geringe Coderate von  ,
können aber noch Daten aus sehr fehlerbehafteten Signal dekodieren. Daher fanden sie unter anderem in der
Mariner 9 Mission Anwendung.
,
können aber noch Daten aus sehr fehlerbehafteten Signal dekodieren. Daher fanden sie unter anderem in der
Mariner 9 Mission Anwendung.
Weitere Beispiele für Blockcodes
Beispiel 1

Die  lauten in der Binärdarstellung:
lauten in der Binärdarstellung:
......... ....##### .###...## #.##.##.. ##.##.#.# ###.##.#.
Es existiert kein linearer Code dieser Mächtigkeit.
Zum einen ist  ,
zum anderen sind die größten lineare Code dieser Art ein
,
zum anderen sind die größten lineare Code dieser Art ein
![{\displaystyle [8,2;5,2]}](/svg/d8145ed7ad6fdb124e2057f9649a3b06c63e7393.svg) - und ein
- und ein
![{\displaystyle [10,3;5,2]}](/svg/2fda2367e6c46e70d280fa9c0676e2c153dea4e9.svg) -Code.
Der Code lässt sich nicht in einen linearen Code umwandeln.
-Code.
Der Code lässt sich nicht in einen linearen Code umwandeln.
Beispiel 2

Die  Codeworte
lauten in der Binärdarstellung (MSB links):
Codeworte
lauten in der Binärdarstellung (MSB links):
........... ...#...#### ..#..##..## ..##.####.. .#..#.#.#.# .#.##.##.#. .##.##..##. .#####.#..# #...##.#.#. #..###..#.# #.#.#.##..# #.###.#.##. ##...###### ##.#.##.... ###....##.. ####.....##
Es handelt sich um einen linearen systematischen Code mit der Basis
...#...#### ..#..##..## .#..#.#.#.# #...##.#.#.
Die 16 Codeworte lassen sich durch eine XOR-Verknüpfung der Basisvektoren erzeugen, deren Informationsbits gesetzt sind (daher linearer Code). Die Informationsbits stellen die linken 4 Bit dar (Bit 10 bis 7), die Schutzbits die rechten 7 Bit (Bit 6 bis 0) (daher systematischer Code).
Beispiel 3

Die  Codeworte lauten in der Binärdarstellung:
Codeworte lauten in der Binärdarstellung:
........ .....### ...##..# ...####. ..#.#.#. ..##.#.# .#..#.## .#.#.#.. .##....# .##.##.. .###..#. .####### #...##.. #..#..## #.#..##. #.#.#..# #.##.... ##....#. ##...#.# ##.##...
Es existiert kein linearer Code dieser Mächtigkeit.
Auch hier ist zum einen  ,
zum anderen sind die größten lineare Code dieser Art ein
,
zum anderen sind die größten lineare Code dieser Art ein
![{\displaystyle [7,4;3,2]}](/svg/c0b6b3e082a3ae82b89c00ac768a27c73dc1bb24.svg) - und ein
- und ein
![{\displaystyle [9,5;3,2]}](/svg/68aea8e185236ce75f09d771b304f31049062cf8.svg) -Code.
Der Code lässt sich nicht in einen linearen Code umwandeln.
-Code.
Der Code lässt sich nicht in einen linearen Code umwandeln.
Fehlerkorrektur
Blockcodes können zur Fehlererkennung und
Fehlerkorrektur bei der Übertragung von Daten über fehlerbehaftete
Kanäle verwendet werden. Dabei ordnet der
Sender dem zu übertragenen Informationswort der Länge
ein Codewort der Länge
zu, wobei
 .
Durch das Hinzufügen der
.
Durch das Hinzufügen der  zusätzlichen Symbole entsteht
Redundanz und die Informationsrate sinkt;
jedoch kann der Empfänger die redundante Information nun dazu nutzen Übertragungsfehler zu erkennen und zu korrigieren.
zusätzlichen Symbole entsteht
Redundanz und die Informationsrate sinkt;
jedoch kann der Empfänger die redundante Information nun dazu nutzen Übertragungsfehler zu erkennen und zu korrigieren.
Verwendet man beispielsweise, im Fall der Binärkodierung, die Zuordnung
| Informationswort | Codewort |
|---|---|
| 0 | 000 |
| 1 | 111 |
so können empfangene Codewörter mit genau einem Bitfehler korrigiert werden, indem man mit Hilfe einer Mehrheitsfunktion das abweichende Bit umkehrt:
| Fehlerhaftes Codewort |
Korrigiertes Codewort |
Zugeordnetes Informationswort |
|---|---|---|
| 001 | 000 | 0 |
| 010 | 000 | 0 |
| 011 | 111 | 1 |
| 100 | 000 | 0 |
| 101 | 111 | 1 |
| 110 | 111 | 1 |
Sind in diesem Falle jedoch zwei Bits falsch, so wird zwar ein Fehler erkannt, aber fehlerhaft korrigiert. Sind gar drei Bits falsch, so kann nicht einmal mehr ein Fehler erkannt werden.
Schranken
Singleton-Schranke
Die Singleton-Schranke
bezeichnet eine obere Schranke für die Mindestdistanz
eines Blockcodes der Länge
bei Informationswörtern der Länge
über einem einheitlichen Alphabet
.
Sie lautet:

Die Schranke kann auf folgende Art intuitiv klargemacht werden:
- Annahme: Alphabet

- Anzahl der möglichen Informationswörter:

- Anzahl der Codewörter:

- Mindestdistanz:
Streicht man nun in den Codewörtern jeweils die letzten ( ) der
Stellen,
so haben die übrigen Codewörter zueinander immer noch mindestens den
Hamming-Abstand 1. Bei
Streichungen wäre dies nicht mehr gewährleistet.
Damit sind immer noch alle Codewörter unterschiedlich, also
) der
Stellen,
so haben die übrigen Codewörter zueinander immer noch mindestens den
Hamming-Abstand 1. Bei
Streichungen wäre dies nicht mehr gewährleistet.
Damit sind immer noch alle Codewörter unterschiedlich, also

Deswegen muss auch die Anzahl der durch die Länge
 erzeugbaren Wörter
erzeugbaren Wörter
 sein.
Stellt man diese Gleichung um, ergibt sich daraus die Singleton-Schranke
sein.
Stellt man diese Gleichung um, ergibt sich daraus die Singleton-Schranke

Für nicht-lineare Codes gilt entsprechend
 ,
,
wobei  .
.
Codes, die die Singleton-Schranke mit Gleichheit erfüllen, nennt man auch MDS-Codes.
Im Falle der Hamming-Schranke ist
 die Anzahl der maximal korrigierbaren Fehler eines Codes mit der Hamming-Distanz
.
die Anzahl der maximal korrigierbaren Fehler eines Codes mit der Hamming-Distanz
.
Die Hamming-Schranke sagt aus, dass
 ,
,
beziehungsweise

erfüllt sein muss für einen Code, der mittels
Symbolen eines Alphabets der Größe
eine Nachricht mit der Länge
transportiert.
Die Singleton-Schranke ist eine ungenauere Abschätzung als die Hamming-Schranke, die die Größe des Alphabets nicht berücksichtigt.
Weiterhin gibt es Unterschiede in der Beziehung zwischen
und
.
Plotkin-Grenze
In der Kanalcodierung verwendet man Blockcodes,
um Fehler in Datenströmen erkennen und korrigieren zu können. Ein Blockcode
 der Länge
über einem
-nären Alphabet mit einem Minimalabstand
erfüllt die
Plotkin-Grenze,
auch als Plotkin-Schranke bezeichnet,
der Länge
über einem
-nären Alphabet mit einem Minimalabstand
erfüllt die
Plotkin-Grenze,
auch als Plotkin-Schranke bezeichnet,

dann, wenn der Nenner positiv ist. Somit liefert die Plotkin-Grenze nur dann ein Resultat, wenn
hinreichend nahe bei
liegt.
Nimmt ein Code die Plotkin-Schranke an,
so gilt insbesondere, dass der Abstand zweier beliebiger Codewörter genau
ist.
Ist  und
und
 mit
mit
 ,
so gilt sogar die schärfere Beziehung:
,
so gilt sogar die schärfere Beziehung:

Beispielsweise liefert die Plotkin-Grenze für  ,
,
 und
und
 nur
nur
 ,
die Verschärfung jedoch
,
die Verschärfung jedoch  ,
da sich für
,
da sich für  und
und
 ein Widerspruch ergibt.
ein Widerspruch ergibt.
Sie wurde 1960 von Morris Plotkin veröffentlicht.
Literatur
- Rudolf Nocker: Digitale Kommunikationssysteme 1. Grundlagen der Basisbandübertragung, 1. Auflage, Friedrich Vieweg & Sohn Verlag, Wiesbaden 2004, ISBN 978-3-528-03976-9.
- Markus Hufschmid: Information und Kommunikation. Grundlagen der Informationsübertragung, Vieweg und Teubner, Wiesbaden 2006, ISBN 3-8351-0122-6.
- Bernd Friedrichs: Kanalcodierung. Grundlagen und Anwendungen in modernen Kommunikationssystemen. Springer Verlag, Berlin/ Heidelberg 1995, ISBN 3-540-59353-5.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 23.12. 2025