Lambda-Kalkül
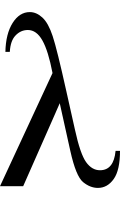
Der Lambda-Kalkül ist eine formale Sprache zur Untersuchung von Funktionen. Er beschreibt die Definition von Funktionen und gebundenen Parametern und wurde in den 1930er Jahren von Alonzo Church und Stephen Cole Kleene eingeführt. Heute ist er ein wichtiges Konstrukt für die Theoretische Informatik, Logik höherer Stufe und Linguistik.
Geschichte
Alonzo Church benutzte den Lambda-Kalkül, um 1936 sowohl eine negative Antwort auf das Entscheidungsproblem zu geben als auch eine Fundierung eines logischen Systems zu finden, wie es den Principia Mathematica von Bertrand Russell und Alfred North Whitehead zugrunde lag. Mittels des untypisierten Lambda-Kalküls kann man klar definieren, was eine berechenbare Funktion ist. Die Frage, ob zwei Lambda-Ausdrücke (s.u.) äquivalent sind, kann im Allgemeinen nicht algorithmisch entschieden werden. In seiner typisierten Form kann der Kalkül benutzt werden, um Logik höherer Stufe darzustellen. Der Lambda-Kalkül hat die Entwicklung funktionaler Programmiersprachen, die Forschung um Typsysteme von Programmiersprachen im Allgemeinen sowie moderne Teildisziplinen in der Logik wie die Typtheorie wesentlich beeinflusst.
Meilensteine der Entwicklung waren im Einzelnen:
- Nach der Einführung die frühe Entdeckung, dass sich mit dem Lambda-Kalkül alles ausdrücken lässt, was man mit einer Turingmaschine ausdrücken kann. Anders formuliert: Im Sinne des Konzepts der Berechenbarkeit sind beide gleich mächtig.
- Konrad Zuse hat Ideen aus dem Lambda-Kalkül 1942 bis 1946 in seinen Plankalkül einfließen lassen.
- John McCarthy hat sie Ende der 1950er Jahre verwendet und damit die minimalen Funktionen der Programmiersprache Lisp definiert.
- Die typisierten Varianten des Lambda-Kalküls führten zu modernen Programmiersprachen wie ML oder Haskell.
- Als überaus fruchtbar erwies sich die Idee, Ausdrücke des typisierten Lambda-Kalküls zur Repräsentation von Termen einer Logik zugrunde zu legen, den Lambda-Kalkül also als Meta-Logik zu verwenden. Erstmals von Church 1940 in seiner Theory of Simple Types präsentiert, führte sie einerseits zu modernen Theorembeweisern für Logiken höherer Stufe und …
- andererseits in den 1970er und 1980er Jahren zu Logiken mit immer mächtigeren Typsystemen, in denen sich z.B. logische Beweise an sich als Lambda-Ausdruck darstellen lassen.
- In Anlehnung an den Lambda-Kalkül wurde für die Beschreibung nebenläufiger Prozesse der Pi-Kalkül von Robin Milner in den 1990er Jahren entwickelt.
Der untypisierte Lambda-Kalkül
Motivation
Ausgehend von einem mathematischen Term, wie beispielsweise  ,
lässt sich eine Funktion bilden, die
,
lässt sich eine Funktion bilden, die  auf
abbildet. Man schreibt auch
auf
abbildet. Man schreibt auch  .
Beim Lambda-Kalkül geht es zunächst darum, solche Funktionsbildungen sprachlich
zu formalisieren. Im Lambda-Kalkül würde man statt
den Term
.
Beim Lambda-Kalkül geht es zunächst darum, solche Funktionsbildungen sprachlich
zu formalisieren. Im Lambda-Kalkül würde man statt
den Term

schreiben. Man sagt, dass die freie Variable
durch λ-Abstraktion gebunden wird. Die Variablen-Bindung kommt in
der Mathematik auch in anderen Bereichen vor:
- Mengenlehre:

- Logik:
 und
und 
- Analysis:

Die abstrahierte Variable muss nicht notwendigerweise im Term vorkommen,
z.B.  . Dieser λ-Ausdruck bezeichnet dann die Funktion, die jedes
auf
. Dieser λ-Ausdruck bezeichnet dann die Funktion, die jedes
auf  abbildet. Etwas allgemeiner ist
abbildet. Etwas allgemeiner ist  die Funktion, die konstant
die Funktion, die konstant  ist. Wird nachträglich noch nach
abstrahiert, so erhält man mit
ist. Wird nachträglich noch nach
abstrahiert, so erhält man mit  eine Formalisierung der Funktion, die jedem Wert
die Funktion zuordnet, die konstant
ist. Der Ausdruck
repräsentiert also eine funktionswertige Funktion. Im Lambda-Kalkül lassen sich
aber auch Funktionen ausdrücken, deren Argumente bereits Funktionen sind. Nimmt
man bspw. die Funktion, die jeder Funktion
eine Formalisierung der Funktion, die jedem Wert
die Funktion zuordnet, die konstant
ist. Der Ausdruck
repräsentiert also eine funktionswertige Funktion. Im Lambda-Kalkül lassen sich
aber auch Funktionen ausdrücken, deren Argumente bereits Funktionen sind. Nimmt
man bspw. die Funktion, die jeder Funktion  eine andere Funktion
eine andere Funktion  zuordnet, die so entsteht, dass
zweimal angewandt wird, so wird
durch den λ-Term
zuordnet, die so entsteht, dass
zweimal angewandt wird, so wird
durch den λ-Term  dargestellt und die Zuordnung
dargestellt und die Zuordnung  durch
durch  .
.
Da λ-Terme als Funktionen gesehen werden, kann man sie auf ein Argument
anwenden. Man spricht von Applikation und schreibt im Lambda-Kalkül eher
 statt
statt  .
Klammern können Terme gruppieren. Die Applikation als Verbindungsprinzip von
Termen ist definitionsgemäß linksassoziativ,
d.h.
.
Klammern können Terme gruppieren. Die Applikation als Verbindungsprinzip von
Termen ist definitionsgemäß linksassoziativ,
d.h.  bedeutet
bedeutet  .
In der üblichen mathematischen Notation würde man hier
.
In der üblichen mathematischen Notation würde man hier  schreiben. Wendet man nun einen Lambda-Term
schreiben. Wendet man nun einen Lambda-Term  auf ein Argument
auf ein Argument  an, also
an, also  ,
so berechnet sich das Ergebnis dadurch, dass in dem Term
,
so berechnet sich das Ergebnis dadurch, dass in dem Term  jedes Vorkommen der Variablen
durch
ersetzt wird. Diese Ableitungsregel nennt man β-Konversion.
jedes Vorkommen der Variablen
durch
ersetzt wird. Diese Ableitungsregel nennt man β-Konversion.
λ-Terme formulieren eher allgemeine Prinzipien der Mathematik und bezeichnen
nicht so sehr Objekte des üblichen mathematischen Universums. Beispielsweise
formuliert  das Zuordnungsprinzip der identischen
Abbildung, doch diese ist immer auf eine gegebene Menge als Definitionsmenge
bezogen. Eine universelle Identität als Funktion ist in der
mengentheoretischen Formulierung der Mathematik nicht definiert. Der
Lambda-Kalkül im strengen Sinne ist daher eher als ein Neuentwurf der Mathematik
zu sehen, in dem die Grundobjekte als universelle Funktionen verstanden werden,
im Gegensatz zur axiomatischen
Mengenlehre, deren Grundobjekte Mengen sind.
das Zuordnungsprinzip der identischen
Abbildung, doch diese ist immer auf eine gegebene Menge als Definitionsmenge
bezogen. Eine universelle Identität als Funktion ist in der
mengentheoretischen Formulierung der Mathematik nicht definiert. Der
Lambda-Kalkül im strengen Sinne ist daher eher als ein Neuentwurf der Mathematik
zu sehen, in dem die Grundobjekte als universelle Funktionen verstanden werden,
im Gegensatz zur axiomatischen
Mengenlehre, deren Grundobjekte Mengen sind.
Zahlen und Terme wie
sind zunächst nicht Bestandteil eines reinen Lambda-Kalküls. Ähnlich wie in der
Mengenlehre, in der man Zahlen und Arithmetik
allein aus dem Mengenbegriff heraus konstruieren kann, ist es aber auch im
Lambda-Kalkül möglich, auf der Basis von λ-Abstraktion und Applikation die
Arithmetik zu definieren. Da im Lambda-Kalkül jeder Term als einstellige
Funktion verstanden wird, muss eine Addition als die Funktion verstanden werden,
die jeder Zahl
diejenige (einstellige) Funktion zuordnet, die zu jeder Zahl
den Wert
addiert.
Lambda-Terme ohne freie Variablen werden auch als Kombinatoren bezeichnet. Die Kombinatorische Logik (oder Kombinator-Kalkül) kann als alternativer Ansatz zum Lambda-Kalkül gesehen werden.
Formale Definition
In seiner einfachsten, dennoch vollständigen Form gibt es im Lambda-Kalkül drei Sorten von Termen, hier in Backus-Naur-Form:
Term ;::= a (Variable) | (Term Term) (Applikation)
| λa. Term (Abstraktion)
wobei
für ein beliebiges Symbol aus einer mindestens abzählbar-unendlichen
Menge von Variablensymbolen (kurz: Variablen) steht. Für praktische
Zwecke wird der Lambda-Kalkül üblicherweise noch um eine weitere Sorte von
Termen, die Konstantensymbole, erweitert.
Die Menge der freien Variablen  kann induktiv
über der Struktur eines λ-Terms
kann induktiv
über der Struktur eines λ-Terms  wie folgt definiert werden:
wie folgt definiert werden:
 ,
falls der Term eine Variable
ist
,
falls der Term eine Variable
ist für Applikationen, und
für Applikationen, und ,
falls der Term eine Abstraktion ist, sind seine freien Variablen die freien
Variablen von
außer .
,
falls der Term eine Abstraktion ist, sind seine freien Variablen die freien
Variablen von
außer .
Die Menge der gebundenen Variablen  eines Terms
errechnet sich auch induktiv:
eines Terms
errechnet sich auch induktiv:
 ,
falls der Term eine Variable
ist
,
falls der Term eine Variable
ist für Applikationen, und
für Applikationen, und ,
falls der Term eine Abstraktion ist, sind seine gebundenen Variablen die
gebundenen Variablen von
vereinigt .
,
falls der Term eine Abstraktion ist, sind seine gebundenen Variablen die
gebundenen Variablen von
vereinigt .
Mittels der Definition von freien und gebundenen Variablen kann nun der Begriff der (freien) Variablensubstitution (Einsetzung) induktiv definiert werden durch:
![a[x\leftarrow T]=a](/svg/fec5310ccddda708d4e05c8b54433ade033dc1ea.svg) falls Variable
ungleich
falls Variable
ungleich ![a[a\leftarrow T]=T](/svg/c34441b727209a8423a19b9353dbd8486fb1ba88.svg)
![(T_{1}~T_{2})[x\leftarrow T]=(T_{1}[x\leftarrow T]~T_{2}[x\leftarrow T])](/svg/7846108ecc03326fcb2f42461a22a2100f804d97.svg)
![(\lambda a.T')[a\leftarrow T]=(\lambda a.T')](/svg/6f9ba13671bd0f9daa020e30f3b498afef1e84da.svg)
![(\lambda a.T')[x\leftarrow T]=(\lambda a.T'[x\leftarrow T])](/svg/ff12e153ca313eedc76721991cf491c3a00ea6ef.svg) falls Variable
ungleich
und falls
disjunkt von
falls Variable
ungleich
und falls
disjunkt von  .
.
Hinweis: ![S[x\leftarrow T]](/svg/a14ebbaa5c4c281f65aecc1ed701141a155b3b4e.svg) steht für:
steht für:  ,
in dem die freie Variable
durch
ersetzt wurde (falls
nicht in
vorhanden ist, wird auch nichts ersetzt).
,
in dem die freie Variable
durch
ersetzt wurde (falls
nicht in
vorhanden ist, wird auch nichts ersetzt).
Man beachte, dass die Substitution nur partiell definiert ist; ggf. müssen gebundene Variablen geeignet umbenannt werden (siehe α-Kongruenz im Folgenden), so dass niemals eine freie Variable in einem Substitut durch Einsetzung für eine Variable gebunden wird.
Über der Menge der λ-Terme können nun Kongruenzregeln (hier ≡ geschrieben) definiert werden, die die Intuition formal fassen, dass zwei Ausdrücke dieselbe Funktion beschreiben. Diese Relationen sind durch die sogenannte α-Konversion, die β-Konversion sowie die η-Konversion erfasst.
Kongruenzregeln
α-Konversion
Die α-Konversionsregel formalisiert die Idee, dass die Namen von gebundenen
Variablen „Schall und Rauch“ sind; z.B. beschreiben
und  dieselbe Funktion. Allerdings sind die Details nicht ganz so einfach wie es
zunächst erscheint: Eine Reihe von Einschränkungen müssen beachtet werden, wenn
gebundene Variablen durch andere gebundene Variablen ersetzt werden.
dieselbe Funktion. Allerdings sind die Details nicht ganz so einfach wie es
zunächst erscheint: Eine Reihe von Einschränkungen müssen beachtet werden, wenn
gebundene Variablen durch andere gebundene Variablen ersetzt werden.
Formal lautet die Regel wie folgt:
![\lambda V.E~\equiv ~\lambda W.E[V\leftarrow W]](/svg/431152383299148dcfd2ae366c60eb9d13fdb644.svg)
falls  in
in  nirgends frei vorkommt und
in
dort nicht gebunden ist, wo es ein
nirgends frei vorkommt und
in
dort nicht gebunden ist, wo es ein  ersetzt. Da eine Kongruenzregel in jedem Teilterm anwendbar ist, erlaubt sie die
Ableitung, dass
ersetzt. Da eine Kongruenzregel in jedem Teilterm anwendbar ist, erlaubt sie die
Ableitung, dass  gleich
gleich  ist.
ist.
β-Konversion
Die β-Konversionsregel formalisiert das Konzept der „Funktionsanwendung“. Wird sie ausschließlich von links nach rechts angewandt, spricht man auch von β-Reduktion. Formal lässt sie sich durch
![((\lambda V.E)~E')~\equiv ~E[V\leftarrow E']](/svg/e29e3ece492970452b313d85ddcfcd7ba6c625ab.svg)
beschreiben, wobei alle freien Variablen in  in
in ![E[V\leftarrow E']](/svg/06ccadd60c078fcb4b55823d076924ea7b9a876a.svg) frei bleiben müssen (siehe Nebenbedingung bei der Substitutionsdefinition).
frei bleiben müssen (siehe Nebenbedingung bei der Substitutionsdefinition).
Ein Term heißt in β-Normalform, wenn keine β-Reduktion mehr anwendbar
ist (nicht für alle Terme existiert eine β-Normalform; siehe unten).
Ein tiefes Resultat von Church und Rosser über den λ-Kalkül besagt, dass die
Reihenfolgen von α-Konversionen und β-Reduktionen in gewissem Sinn keine Rolle
spielt: wenn man einen Term zu zwei Termen  und
und  ableitet, gibt es immer eine Möglichkeit,
und
jeweils zu einem gemeinsamen Term
ableitet, gibt es immer eine Möglichkeit,
und
jeweils zu einem gemeinsamen Term  abzuleiten.
abzuleiten.
η-Konversion
Die η-Konversion kann optional zum Kalkül hinzugefügt werden. Sie formalisiert das Konzept der Extensionalität, d.h., dass zwei Funktionen genau dann gleich sind, wenn sie für alle Argumente dasselbe Resultat liefern. Formal ist die η-Konversion beschrieben durch:
 ,
wenn
nicht freie Variable von
ist.
,
wenn
nicht freie Variable von
ist.
Anmerkungen
- Nicht für alle Terme existiert eine β-Normalform. Beispielsweise kann man
auf den Term
 zwar β-Reduktion anwenden, doch man erhält wieder den gleichen Term als
Ergebnis zurück.
zwar β-Reduktion anwenden, doch man erhält wieder den gleichen Term als
Ergebnis zurück. - Jeder Term, der die Bedingung der β-Regel erfüllt, wird β-reduzibel genannt.
- Die β-Reduktion ist im Allgemeinen nicht eindeutig; es kann mehrere Ansatzpunkte (sog. β-Redexe, von englisch reducible expression, reduzibler Ausdruck) für die Anwendung der β-Regel geben, weil die Regelanwendung in allen Teiltermen möglich ist.
- Wenn mehrere Folgen von β-Reduktionen möglich sind und mehrere davon zu einem nicht-β-reduziblen Term führen, so sind diese Terme bis auf α-Kongruenz gleich.
- Wenn jedoch eine Reihenfolge der β zu einem nicht-β-reduziblen Term (einem Ergebnis) führt, so tut dies auch die Standard Reduction Order, bei der das im Term erste Lambda zuerst verwendet wird.
- In einer alternativen Notation werden die Variablennamen durch De-Bruijn-Indizes ersetzt. Diese Indizes entsprechen der Anzahl der Lambda-Terme zwischen der Variablen und ihrem bindenden Lambda-Ausdruck. Diese Darstellung wird oft in Computerprogrammen verwendet, da sie die α-Konversion obsolet macht und β-Reduktion deutlich vereinfacht.
Weitere Beispiele
- Der Term
 ist eine Möglichkeit von vielen, die logische Funktion
ist eine Möglichkeit von vielen, die logische Funktion  darzustellen. Hierzu versteht man
darzustellen. Hierzu versteht man  als Abkürzung für
als Abkürzung für  und
und  als Abkürzung für
als Abkürzung für  .
Der Term erfüllt alle Forderungen, die man an die Funktion
stellt.
.
Der Term erfüllt alle Forderungen, die man an die Funktion
stellt.
- Man kann in ähnlicher Weise Zahlen, Tupel und Listen in λ-Ausdrücken codieren (z.B. durch sogenannte Church-Numerale)
- Man kann beliebige rekursive Funktionen durch den Fixpunkt-Kombinator
 darstellen.
darstellen.




Typisierter Lambda-Kalkül
Die zentrale Idee des typisierten Lambda-Kalküls ist es, nur noch Lambda-Ausdrücke zu betrachten, denen sich ein Typ durch ein System von Typinferenzregeln zuordnen lässt. Das einfachste Typsystem, das von Alonzo Church 1940 in seiner Theory of Simple Types vorgestellt wurde, sieht die Typen vor, die durch folgende Grammatik in Backus-Naur-Form generiert werden:
TT ::= I (Individuen) | O (Wahrheitswerte) | (TT →
TT) (Funktionstypen)
Den Typ  kann man sich als Zahlen vorstellen,
kann man sich als Zahlen vorstellen,  wird für boolesche Werte wie True und False verwendet.
wird für boolesche Werte wie True und False verwendet.
Zusätzlich wird eine Umgebung  definiert; dies ist eine Funktion, die Variablensymbolen Typen
definiert; dies ist eine Funktion, die Variablensymbolen Typen  zuordnet.
zuordnet.
Ein Tripel aus einer Umgebung ,
einem Ausdruck
und einem Typ ,
geschrieben  wird ein Typurteil genannt.
wird ein Typurteil genannt.
Nun können die Inferenzregeln Beziehungen zwischen Ausdrücken, ihren Typen
und Typurteilen herstellen:


![{\displaystyle {\Gamma [a\mapsto \tau _{1}]\vdash t::\tau _{2} \over \Gamma \vdash \lambda a.t::\tau _{1}\rightarrow \tau _{2}}\qquad ({\rm {Abstraktion)}}}](/svg/400c7fec576036cba9dd45b03d49f9503e6c82af.svg)
Hierbei ist ![\Gamma [a\mapsto \tau _{1}]](/svg/9f444541dbbc706653c732fa1d78ad61c5e877ea.svg) diejenige Funktion, die an der Stelle
den Typ
diejenige Funktion, die an der Stelle
den Typ  zuordnet, und ansonsten die Funktion
ist. (Anders ausgedrückt: Der Parameter
der Funktion ist vom Typ
und genau diese Information wird der Umgebung hinzugefügt.)
zuordnet, und ansonsten die Funktion
ist. (Anders ausgedrückt: Der Parameter
der Funktion ist vom Typ
und genau diese Information wird der Umgebung hinzugefügt.)
Durch Einführung einer zweiten Umgebung sind auch Konstantensymbole
behandelbar; eine weitere wichtige Erweiterung besteht darin, in Typen auch die
Kategorie der Typvariablen  etc. oder Typkonstruktoren wie
etc. oder Typkonstruktoren wie  ,
,
 etc. zuzulassen: so entstehen schon sehr mächtige funktionale oder logische
Kernsprachen.
ist beispielsweise eine Funktion, die den beliebigen Typen
etc. zuzulassen: so entstehen schon sehr mächtige funktionale oder logische
Kernsprachen.
ist beispielsweise eine Funktion, die den beliebigen Typen  auf den Typ „Menge, deren Elemente vom Typ
sind“ abbildet;
analog; geschrieben
auf den Typ „Menge, deren Elemente vom Typ
sind“ abbildet;
analog; geschrieben  und
und  ,
wobei auch wie gehabt die Klammern fehlen dürfen. Das Konzept kann leicht weiter
abstrahiert werden, indem statt eines konkreten Typkonstruktors auch eine
Variable verwendet wird, z.B.
,
wobei auch wie gehabt die Klammern fehlen dürfen. Das Konzept kann leicht weiter
abstrahiert werden, indem statt eines konkreten Typkonstruktors auch eine
Variable verwendet wird, z.B.  .
Typkonstruktoren dürfen allgemein auch mehrere Argumente besitzen, wie
beispielsweise der Pfeil: Der Typ
.
Typkonstruktoren dürfen allgemein auch mehrere Argumente besitzen, wie
beispielsweise der Pfeil: Der Typ  ist nichts anderes als
ist nichts anderes als  ,
zeigt aber besser, dass der Pfeil ein Typkonstruktor in zwei Variablen ist.
Insbesondere ist auch bei Typkonstruktoren Currying möglich, und
,
zeigt aber besser, dass der Pfeil ein Typkonstruktor in zwei Variablen ist.
Insbesondere ist auch bei Typkonstruktoren Currying möglich, und  ist ein Typkonstruktor in einer Variablen.
ist ein Typkonstruktor in einer Variablen.
Es ist entscheidbar,
ob ein untypisierter Term sich typisieren lässt, selbst wenn die Umgebung
unbekannt ist (eine Variante mit Typvariablen und Typkonstruktoren ist der
Algorithmus nach Hindley-Milner).
Die Menge der typisierbaren Ausdrücke ist eine echte Teilmenge des untypisierten Lambda-Kalküls; z. B. lässt sich der Y-Kombinator nicht typisieren. Andererseits ist für typisierte Ausdrücke die Gleichheit zwischen zwei Funktionen modulo α- und β-Konversionen entscheidbar. Es ist bekannt, dass das Matching-Problem auf Lambda-Ausdrücken bis zur vierten Ordnung entscheidbar ist. Das Unifikationsproblem ist unentscheidbar; allerdings gibt es praktisch brauchbare approximative Algorithmen.
Anwendung in der Semantik
Die Semantik ist dasjenige Teilgebiet der Linguistik, welches die Bedeutung natürlichsprachlicher Ausdrücke analysiert. Die formale Semantik nutzt dazu zunächst einfache Mittel der Prädikatenlogik und Mengenlehre. Diese erweitert man um Grundlagen des Lambda-Kalküls, etwa um mittels Lambda-Abstraktion Propositionen als Eigenschaften zu repräsentieren und komplexere Nominalphrasen, Adjektivphrasen und einige Verbalphrasen darstellen zu können. Grundlage ist etwa eine modelltheoretische semantische Interpretation der intensionalen Logik Richard Montagues.
Anwendung in der Informatik
Der Lambda-Kalkül ist auch die formale Grundlage für viele Programmiersprachen, wie z.B. Scheme oder Lisp. Einige Programmiersprachen bieten Konzepte wie anonyme Funktionen an, auf die sich einige der Regeln des Lambda-Kalküls anwenden lassen. Die Programmiersprachen erlauben jedoch meist mehr als der reine Lambda-Kalkül wie beispielsweise Seiteneffekte.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 20.08. 2022