Satz von Bayes

Der Satz von Bayes ist ein mathematischer Satz aus der Wahrscheinlichkeitstheorie, der die Berechnung bedingter Wahrscheinlichkeiten beschreibt. Er ist nach dem englischen Mathematiker Thomas Bayes benannt, der ihn erstmals in einem Spezialfall in der 1763 posthum veröffentlichten Abhandlung An Essay Towards Solving a Problem in the Doctrine of Chances beschrieb. Er wird auch Formel von Bayes oder (als Lehnübersetzung) Bayes-Theorem genannt.
Formel
Für zwei Ereignisse
 und
und  mit
mit  lässt sich die Wahrscheinlichkeit von
unter der Bedingung, dass
eingetreten ist, durch die Wahrscheinlichkeit von
unter der Bedingung, dass
eingetreten ist, errechnen:
lässt sich die Wahrscheinlichkeit von
unter der Bedingung, dass
eingetreten ist, durch die Wahrscheinlichkeit von
unter der Bedingung, dass
eingetreten ist, errechnen:
 .
.
Hierbei ist
 die (bedingte)
Wahrscheinlichkeit des Ereignisses
unter der Bedingung, dass
eingetreten ist,
die (bedingte)
Wahrscheinlichkeit des Ereignisses
unter der Bedingung, dass
eingetreten ist, die (bedingte) Wahrscheinlichkeit des Ereignisses
unter der Bedingung, dass
eingetreten ist,
die (bedingte) Wahrscheinlichkeit des Ereignisses
unter der Bedingung, dass
eingetreten ist, die A-priori-Wahrscheinlichkeit
des Ereignisses
und
die A-priori-Wahrscheinlichkeit
des Ereignisses
und die A-priori-Wahrscheinlichkeit des Ereignisses .
die A-priori-Wahrscheinlichkeit des Ereignisses .
Bei endlich vielen Ereignissen lautet der Satz von Bayes:
Wenn  eine Zerlegung
der Ergebnismenge
in disjunkte
Ereignisse ist, gilt für die A-posteriori-Wahrscheinlichkeit
eine Zerlegung
der Ergebnismenge
in disjunkte
Ereignisse ist, gilt für die A-posteriori-Wahrscheinlichkeit

 .
.
Den letzten Umformungsschritt bezeichnet man auch als Marginalisierung.
Da ein Ereignis
und sein Komplement
 stets eine Zerlegung der Ergebnismenge darstellen, gilt insbesondere
stets eine Zerlegung der Ergebnismenge darstellen, gilt insbesondere
 .
.
Des Weiteren gilt der Satz auch für eine Zerlegung des Grundraumes  in abzählbar viele paarweise disjunkte Ereignisse.
in abzählbar viele paarweise disjunkte Ereignisse.
Beweis
 .
.Der Satz folgt unmittelbar aus der Definition der bedingten Wahrscheinlichkeit:
 .
.
Die Beziehung

ist eine Anwendung des Gesetzes der totalen Wahrscheinlichkeit.
Interpretation
Der Satz von Bayes erlaubt in gewissem Sinn das Umkehren von
Schlussfolgerungen: Man geht von einem bekannten Wert
aus, ist aber eigentlich an dem Wert
interessiert. Beispielsweise ist es von Interesse, wie groß die
Wahrscheinlichkeit ist, dass jemand eine bestimmte Krankheit hat, wenn ein dafür
entwickelter Schnelltest
ein positives Ergebnis zeigt. Aus empirischen
Studien kennt man in der Regel die Wahrscheinlichkeit dafür, mit der der
Test bei einer von dieser Krankheit befallenen Person zu einem positiven
Ergebnis führt. Die gewünschte Umrechnung ist nur dann möglich, wenn man die Prävalenz der Krankheit
kennt, das heißt die (absolute) Wahrscheinlichkeit, mit der die betreffende
Krankheit in der Gesamtpopulation auftritt (siehe Rechenbeispiel
2).
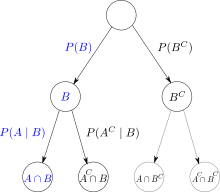
Für das Verständnis kann ein Entscheidungsbaum oder eine Vierfeldertafel helfen. Das Verfahren ist auch als Rückwärtsinduktion bekannt.
Mitunter begegnet man dem Fehlschluss,
direkt von
auf
schließen zu wollen, ohne die A-priori-Wahrscheinlichkeit
zu berücksichtigen, beispielsweise indem angenommen wird, die beiden bedingten
Wahrscheinlichkeiten müssten ungefähr gleich groß sein.
Wie der Satz von Bayes zeigt, ist das aber nur dann der Fall, wenn auch
und
ungefähr gleich groß sind.
Ebenso ist zu beachten, dass bedingte Wahrscheinlichkeiten für sich allein nicht dazu geeignet sind, eine bestimmte Kausalbeziehung nachzuweisen.
Anwendungsgebiete
- Statistik: Alle Fragen des Lernens aus Erfahrung, bei denen eine A-priori-Wahrscheinlichkeitseinschätzung aufgrund von Erfahrungen verändert und in eine A-posteriori-Verteilung überführt wird (vgl. Bayessche Statistik).
- Data-Mining: Bayes-Klassifikatoren sind theoretische Entscheidungsregeln mit beweisbar minimaler Fehlerrate.
- Spamerkennung: Bayes-Filter – Von charakteristischen Wörtern in einer E-Mail (Ereignis A) wird auf die Eigenschaft Spam (Ereignis B) zu sein, geschlossen.
- Künstliche Intelligenz: Hier wird der Satz von Bayes verwendet, um auch in Domänen mit „unsicherem“ Wissen Schlussfolgerungen ziehen zu können. Diese sind dann nicht deduktiv und somit auch nicht immer korrekt, sondern eher abduktiver Natur, haben sich aber zur Hypothesenbildung und zum Lernen in solchen Systemen als durchaus nützlich erwiesen.
- Qualitätsmanagement: Beurteilung der Aussagekraft von Testreihen.
- Entscheidungstheorie/Informationsökonomik: Bestimmung des erwarteten Wertes von zusätzlichen Informationen.
- Grundmodell der Verkehrsverteilung.
- Bioinformatik: Bestimmung funktioneller Ähnlichkeit von Sequenzen; Rekonstruktion von Stammbäumen und des Alters der Knoten
- Kommunikationstheorie: Lösung von Detektions- und Dekodierproblemen.
- Ökonometrie: Bayessche Ökonometrie
Rechenbeispiel 1
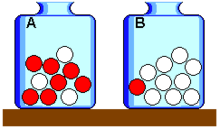
In den beiden Urnen
und
befinden sich jeweils zehn Kugeln. In
sind sieben rote und drei weiße Kugeln, in
eine rote und neun weiße. Es wird nun eine beliebige Kugel aus einer zufällig
gewählten Urne gezogen. Anders ausgedrückt: Ob aus Urne
oder
gezogen wird, ist a priori gleich wahrscheinlich. Das Ergebnis der Ziehung ist: Die Kugel ist
rot. Gesucht ist die Wahrscheinlichkeit, dass diese rote Kugel aus Urne
stammt.
Es sei:
das Ereignis „Die Kugel stammt aus Urne “,
das Ereignis „Die Kugel stammt aus Urne “
und das Ereignis „Die Kugel ist rot“.
das Ereignis „Die Kugel ist rot“.
Dann gilt:  (beide
Urnen sind a priori gleich wahrscheinlich)
(beide
Urnen sind a priori gleich wahrscheinlich)
 (in
Urne A sind 10 Kugeln, davon 7 rote)
(in
Urne A sind 10 Kugeln, davon 7 rote)
 (in
Urne B sind 10 Kugeln, davon 1 rote)
(in
Urne B sind 10 Kugeln, davon 1 rote)
 (totale
Wahrscheinlichkeit, eine rote Kugel zu ziehen)
(totale
Wahrscheinlichkeit, eine rote Kugel zu ziehen)
Damit ist  .
.
Die bedingte Wahrscheinlichkeit, dass die gezogene rote Kugel aus der Urne
gezogen wurde, beträgt also  .
.
Das Ergebnis der Bayes-Formel in diesem einfachen Beispiel kann leicht
anschaulich eingesehen werden: Da beide Urnen a priori mit der gleichen
Wahrscheinlichkeit ausgewählt werden und sich in beiden Urnen gleich viele
Kugeln befinden, haben alle Kugeln – und damit auch alle acht roten Kugeln – die
gleiche Wahrscheinlichkeit, gezogen zu werden. Wenn man wiederholt eine Kugel
aus einer zufälligen Urne zieht und wieder in die richtige Urne zurücklegt, wird
man im Durchschnitt in acht von 20 Fällen eine rote und in zwölf von 20 Fällen
eine weiße Kugel ziehen (deshalb ist auch die totale Wahrscheinlichkeit, eine
rote Kugel zu ziehen, gleich  ).
Von diesen acht roten Kugeln kommen im Mittel sieben aus Urne
und eine aus Urne .
Die Wahrscheinlichkeit, dass eine gezogene rote Kugel aus Urne
stammt, ist daher gleich
).
Von diesen acht roten Kugeln kommen im Mittel sieben aus Urne
und eine aus Urne .
Die Wahrscheinlichkeit, dass eine gezogene rote Kugel aus Urne
stammt, ist daher gleich  .
.
Rechenbeispiel 2
Eine bestimmte Krankheit tritt mit einer Prävalenz
von 20 pro 100 000 Personen auf. Der Sachverhalt  ,
dass ein Mensch diese Krankheit in sich trägt, hat also die Wahrscheinlichkeit
,
dass ein Mensch diese Krankheit in sich trägt, hat also die Wahrscheinlichkeit
 .
.
Ist ein Screening der
Gesamtbevölkerung ohne Rücksicht auf Risikofaktoren oder Symptome geeignet,
Träger dieser Krankheit zu ermitteln? Es würden dabei weit überwiegend Personen
aus dem Komplement
 von
getestet, also Personen, die diese Krankheit nicht in sich tragen: Die
Wahrscheinlichkeit, dass eine zu testende Person nicht Träger der Krankheit ist,
beträgt
von
getestet, also Personen, die diese Krankheit nicht in sich tragen: Die
Wahrscheinlichkeit, dass eine zu testende Person nicht Träger der Krankheit ist,
beträgt  .
.
 bezeichne die Tatsache, dass der Test bei einer Person „positiv“ ausgefallen
ist, also die Krankheit anzeigt. Es sei bekannt, dass der Test
mit 95 % Wahrscheinlichkeit anzeigt (Sensitivität
bezeichne die Tatsache, dass der Test bei einer Person „positiv“ ausgefallen
ist, also die Krankheit anzeigt. Es sei bekannt, dass der Test
mit 95 % Wahrscheinlichkeit anzeigt (Sensitivität  ),
aber manchmal auch bei Gesunden anspricht, d.h. ein falsch
positives Testergebnis liefert, und zwar mit einer Wahrscheinlichkeit von
),
aber manchmal auch bei Gesunden anspricht, d.h. ein falsch
positives Testergebnis liefert, und zwar mit einer Wahrscheinlichkeit von
 (Spezifität
(Spezifität
 ).
).
Nicht nur für die Eingangsfrage, sondern in jedem Einzelfall ,
insbesondere vor dem Ergebnis weiterer Untersuchungen, interessiert die positiver
prädiktiver Wert genannte bedingte Wahrscheinlichkeit  ,
dass positiv Getestete Träger der Krankheit sind.
,
dass positiv Getestete Träger der Krankheit sind.
Berechnung mit dem Satz von Bayes
 .
.
Berechnung mittels Baumdiagramm
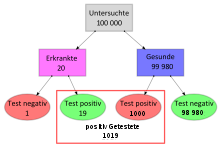
Probleme mit wenigen Klassen und einfachen Verteilungen lassen sich übersichtlich im Baumdiagramm für die Aufteilung der Häufigkeiten darstellen. Geht man von den Häufigkeiten auf relative Häufigkeiten bzw. auf (bedingte) Wahrscheinlichkeiten über, wird aus dem Baumdiagramm ein Ereignisbaum, ein Sonderfall des Entscheidungsbaums.
Den obigen Angaben folgend ergeben sich als absolute
Häufigkeit bei 100 000 Personen 20 tatsächlich erkrankte Personen, 99 980
Personen sind gesund. Der Test diagnostiziert bei den 20 kranken Personen in 19
Fällen (95 Prozent Sensitivität) korrekt die Erkrankung. In einem Fall
versagt der Test und zeigt die vorliegende Krankheit nicht an (falsch negativ).
Bei wahrscheinlich 1000 der 99 980 gesunden Personen zeigt der Test
fälschlicherweise eine Erkrankung an. Von den insgesamt 1019 positiv getesteten
Personen sind also nur 19 tatsächlich krank ( ).
).
Bedeutung des Ergebnisses
Der Preis, 19 Träger der Krankheit zu finden, möglicherweise rechtzeitig genug für eine Behandlung oder Isolation, besteht nicht nur in den Kosten für 100 000 Tests, sondern auch in den unnötigen Ängsten und womöglich Behandlungen von 1000 falsch positiv Getesteten. Die Ausgangsfrage, ob bei diesen Zahlenwerten ein Massenscreening sinnvoll ist, ist daher wohl zu verneinen.
Die instinktive Annahme, dass eine – auf den ersten Blick eindrückliche – Sensitivität von 95 % bedeutet, dass eine positiv getestete Person auch tatsächlich mit hoher Wahrscheinlichkeit krank ist, ist also falsch. Dieses Problem tritt immer dann auf, wenn die tatsächliche Rate, mit der ein Merkmal in der untersuchten Gesamtmenge vorkommt, klein ist gegenüber der Rate der falsch positiven Ergebnisse.
Bayessche Statistik
Die Bayessche Statistik verwendet den Satz von Bayes im Rahmen der induktiven Statistik zur Schätzung von Parametern und zum Testen von Hypothesen.
Problemstellung
Folgende Situation sei gegeben:  ist ein unbekannter Umweltzustand
(z.B. ein Parameter einer Wahrscheinlichkeitsverteilung), der auf der
Basis einer Beobachtung
ist ein unbekannter Umweltzustand
(z.B. ein Parameter einer Wahrscheinlichkeitsverteilung), der auf der
Basis einer Beobachtung  einer Zufallsvariable
einer Zufallsvariable
 geschätzt werden soll. Weiterhin ist Vorwissen in Form einer A-priori-Wahrscheinlichkeitsverteilung
des unbekannten Parameters
gegeben. Diese A-priori-Verteilung enthält die gesamte Information über den
Umweltzustand ,
die vor der Beobachtung der Stichprobe gegeben ist.
geschätzt werden soll. Weiterhin ist Vorwissen in Form einer A-priori-Wahrscheinlichkeitsverteilung
des unbekannten Parameters
gegeben. Diese A-priori-Verteilung enthält die gesamte Information über den
Umweltzustand ,
die vor der Beobachtung der Stichprobe gegeben ist.
Je nach Kontext und philosophischer Schule wird die A-priori-Verteilung verstanden
- als mathematische Modellierung des subjektiven degrees of belief (subjektiver Wahrscheinlichkeitsbegriff),
- als adäquate Darstellung des allgemeinen Vorwissens (wobei Wahrscheinlichkeiten als natürliche Erweiterung der aristotelischen Logik in Bezug auf Unsicherheit verstanden werden – Cox' Postulate),
- als aus Voruntersuchungen bekannte Wahrscheinlichkeitsverteilung eines tatsächlich zufälligen Parameters oder
- als eine spezifisch gewählte Verteilung, die auf ideale Weise mit Unwissen über den Parameter korrespondiert (objektive A-priori-Verteilungen, zum Beispiel mithilfe der Maximum-Entropie-Methode).
Die bedingte Verteilung von
unter der Bedingung, dass
den Wert  annimmt, wird im Folgenden mit
annimmt, wird im Folgenden mit  bezeichnet. Diese Wahrscheinlichkeitsverteilung kann nach Beobachtung der
Stichprobe bestimmt werden und wird auch als Likelihood des
Parameterwerts
bezeichnet.
bezeichnet. Diese Wahrscheinlichkeitsverteilung kann nach Beobachtung der
Stichprobe bestimmt werden und wird auch als Likelihood des
Parameterwerts
bezeichnet.
Die A-posteriori-Wahrscheinlichkeit  kann mit Hilfe des Satzes von Bayes berechnet werden. Im Spezialfall einer
diskreten A-priori-Verteilung erhält man:
kann mit Hilfe des Satzes von Bayes berechnet werden. Im Spezialfall einer
diskreten A-priori-Verteilung erhält man:

Falls die Menge aller möglichen Umweltzustände endlich ist, lässt sich die
A-posteriori-Verteilung im Wert
als die Wahrscheinlichkeit interpretieren, mit der man nach Beobachtung der
Stichprobe und unter Einbeziehung des Vorwissens den Umweltzustand
erwartet.
Als Schätzwert verwendet ein Anhänger der subjektivistischen Schule der Statistik in der Regel den Erwartungswert der A-posteriori-Verteilung, in manchen Fällen auch den Modalwert.
Beispiel
Ähnlich wie oben werde wieder eine Urne betrachtet, die mit zehn Kugeln
gefüllt ist, aber nun sei unbekannt, wie viele davon rot sind. Die Anzahl
der roten Kugeln ist hier der unbekannte Umweltzustand und als dessen
A-priori-Verteilung soll angenommen werden, dass alle möglichen Werte von null
bis zehn gleich wahrscheinlich sein sollen, d.h. es gilt  für alle
für alle  .
.
Nun werde fünfmal mit Zurücklegen eine Kugel aus der Urne gezogen und
bezeichne die Zufallsvariable, die angibt, wie viele davon rot sind. Unter der
Annahme  ist dann
binomialverteilt
mit den Parametern
ist dann
binomialverteilt
mit den Parametern  und
und  ,
es gilt also
,
es gilt also

für  .
.
Beispielsweise für  ,
d.h. zwei der fünf gezogenen Kugeln waren rot, ergeben sich die folgenden
Werte (auf drei Nachkommastellen gerundet)
,
d.h. zwei der fünf gezogenen Kugeln waren rot, ergeben sich die folgenden
Werte (auf drei Nachkommastellen gerundet)
|
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
 |
0,091 | 0,091 | 0,091 | 0,091 | 0,091 | 0,091 | 0,091 | 0,091 | 0,091 | 0,091 | 0,091 |
 |
0,000 | 0,044 | 0,123 | 0,185 | 0,207 | 0,188 | 0,138 | 0,079 | 0,031 | 0,005 | 0,000 |
Man sieht, dass im Gegensatz zur A-priori-Verteilung in der zweiten Zeile, in
der alle Werte von
als gleich wahrscheinlich angenommen wurden, unter der A-posteriori-Verteilung
in der dritten Zeile  die größte Wahrscheinlichkeit besitzt, das heißt der A-posteriori-Modus ist
die größte Wahrscheinlichkeit besitzt, das heißt der A-posteriori-Modus ist
 .
.
Als Erwartungswert der A-posteriori-Verteilung ergibt sich hier:
 .
.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 30.12. 2025