Entscheidungsbaum
Entscheidungsbäume sind geordnete, gerichtete Bäume, die der Darstellung von Entscheidungsregeln dienen. Die grafische Darstellung als Baumdiagramm veranschaulicht hierarchisch aufeinanderfolgende Entscheidungen. Sie haben eine Bedeutung in zahlreichen Bereichen, in denen automatisch klassifiziert wird oder aus Erfahrungswissen formale Regeln hergeleitet oder dargestellt werden.
Eigenschaften und Einsatz
Entscheidungsbäume sind eine Methode zur automatischen Klassifikation von Datenobjekten und damit zur Lösung von Entscheidungsproblemen. Sie werden außerdem zur übersichtlichen Darstellung von formalen Regeln genutzt. Ein Entscheidungsbaum besteht immer aus einem Wurzelknoten und beliebig vielen inneren Knoten sowie mindestens zwei Blättern. Dabei repräsentiert jeder Knoten eine logische Regel und jedes Blatt eine Antwort auf das Entscheidungsproblem.
Die Komplexität und Semantik der Regeln sind von vornherein nicht beschränkt. Bei binären Entscheidungsbäumen kann jeder Regelausdruck nur einen von zwei Werten annehmen. Alle Entscheidungsbäume lassen sich in binäre Entscheidungsbäume überführen.
Entscheidungsbäume kommen in zahlreichen Bereichen zum Einsatz, z.B.
- in der Stochastik als Wahrscheinlichkeitsbaum zur Veranschaulichung bedingter Wahrscheinlichkeiten (z.B. bei absoluten Häufigkeiten)
- im Maschinellen Lernen als Methode zur automatischen Klassifikation von Objekten
- im Data-Mining
- in der Entscheidungstheorie
- in der ärztlichen Entscheidungsfindung (Medizin) und in der Notfallmedizin
- in Business-Rule-Management-Systemen (BRMS) für die Definition von Regeln
Funktionsweise
Klassifizieren mit Entscheidungsbäumen
Um eine Klassifikation eines einzelnen Datenobjektes abzulesen, geht man vom Wurzelknoten entlang des Baumes abwärts. Bei jedem Knoten wird ein Attribut abgefragt und eine Entscheidung über die Auswahl des folgenden Knoten getroffen. Diese Prozedur wird so lange fortgesetzt, bis man ein Blatt erreicht. Das Blatt entspricht der Klassifikation. Ein Baum enthält grundsätzlich Regeln zur Beantwortung von nur genau einer Fragestellung.
Beispiel: Ein Entscheidungsbaum mit geringer Komplexität
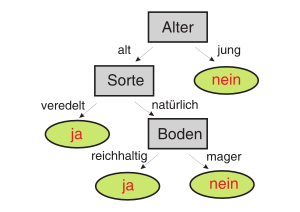
Der nebenstehende binäre Entscheidungsbaum gibt eine Antwort auf die Frage, ob ein Apfelbaum Früchte tragen wird. Als Eingabe benötigt der Baum einen Vektor mit Angaben zu den Attributen eines Apfelbaumes. Ein Apfelbaum kann beispielsweise die Attribute alt, natürliche Sorte und reichhaltiger Boden besitzen. Beginnend mit dem Wurzelknoten werden nun die Entscheidungsregeln des Baumes auf den Eingabevektor angewendet. Dabei wird im Beispielbaum an jedem Knoten ein Attribut des Eingabevektors abgefragt, am Wurzelknoten etwa das Alter des Apfelbaumes. Die Antwort entscheidet über den Folgeknoten und damit über die nächste anzuwendende Entscheidungsregel, in diesem Falle die Frage zur Sorte, und danach die Frage nach der Bodenbeschaffenheit. Gelangt man nach einer Folge von ausgewerteten Regeln an ein Blatt, hat man die Antwort auf die ursprüngliche Frage. Nicht immer müssen alle Ebenen des Entscheidungsbaums durchlaufen werden. Für den oben beschriebenen Apfelbaum ist die Antwort ja, also dass der Baum Früchte tragen wird. Diesen Entscheidungsvorgang nennt man formal Klassifikation.
Induktion von Entscheidungsbäumen
Entscheidungsbäume können entweder von Experten manuell aufgeschrieben werden oder mit Techniken des maschinellen Lernens automatisch aus gesammelten Erfahrungswerten induziert werden. Hierzu gibt es mehrere konkurrierende Algorithmen.
Die Induktion der Entscheidungsbäume erfolgt üblicherweise rekursiv im Top-down-Prinzip. Dazu ist es von entscheidender Bedeutung, dass ein geeigneter Datensatz mit verlässlichen Erfahrungswerten zum Entscheidungsproblem (der sogenannte Trainingsdatensatz) vorliegt. Das bedeutet, dass zu jedem Objekt des Trainingsdatensatzes die Klassifikation des Zielattributs bekannt sein muss. Bei jedem Induktionsschritt wird nun das Attribut gesucht, mit welchem sich die Trainingsdaten in diesem Schritt bezüglich des Zielattributs am besten klassifizieren lassen. Als Maß für die Bestimmung der besten Klassifizierung kommen Entropie-Maße, Gini-Index oder andere zur Anwendung. Das ermittelte Attribut wird nun zur Aufteilung der Daten verwendet. Auf die so entstandenen Teilmengen wird die Prozedur rekursiv angewendet, bis in jeder Teilmenge nur noch Objekte mit einer Klassifikation enthalten sind. Am Ende ist ein Entscheidungsbaum entstanden, der das Erfahrungswissen des Trainingsdatensatzes in formalen Regeln beschreibt.
Die Bäume können nun zum automatischen Klassifizieren anderer Datensätze oder zum Interpretieren und Auswerten des entstandenen Regelwerks genutzt werden.
Algorithmen im Vergleich
Die Algorithmen zur automatischen Induktion von Entscheidungsbäumen setzen alle auf dem gleichen rekursiven Top-down-Prinzip auf. Sie unterscheiden sich nur in ihren Kriterien zur Auswahl der Attribute und Werte der Regeln an den Knoten des Baumes, in ihren Kriterien zum Abbruch des Induktionsprozesses und in möglichen Nachbearbeitungsschritten, die einen bereits berechneten Ast eines Baumes (oder ganze Bäume) nachträglich anhand diverser Kriterien optimieren.
Die Praxis unterscheidet verschiedene Familien von Algorithmen:
- Die älteste Familie sind die CHAIDs (Chi-square Automatic Interaction Detectors) von 1964. Sie können Bäume auf Basis von diskreten Attributen erzeugen.
- Die Familie der CARTs (Classification And Regression Trees) erweitert die CHAIDS vor allem um die Möglichkeit, reellwertige Attribute verarbeiten zu können, indem ein Teilungs-Kriterium (engl. split-criterion) zur Aufteilung reellwertiger Attribute in diskrete Kategorien genutzt wird. Zudem werden einige Optimierungsstrategien wie z.B. das Pruning eingeführt.
- Die jüngsten Algorithmen sind der ID3-Algorithmus und seine Nachfolger C4.5 und C5.0. Sie zählen formal zur Familie der CARTs, werden aber häufig als eigenständige Gruppe gesehen, da sie im Vergleich zu CART zahlreiche neue Optimierungsstrategien einführen.
Fehlerrate und Wirksamkeit
Die Fehlerrate eines Entscheidungsbaumes ist die Anzahl der inkorrekt klassifizierten Datenobjekte im Verhältnis zu allen Datenobjekten eines Datensatzes. Diese Zahl wird regelmäßig entweder auf den benutzten Trainingsdaten oder besser auf einer zu den Trainingsdaten disjunkten Menge an möglichst korrekt klassifizierten Datenobjekten ermittelt.
Je nach Anwendungsbereich kann es von besonderer Bedeutung sein, entweder die Anzahl der falsch positiv oder falsch negativ klassifizierten Objekte im Speziellen niedrig zu halten. So ist es etwa in der Notfallmedizin wesentlich unschädlicher einen gesunden Patienten zu behandeln, als einen kranken Patienten nicht zu behandeln. Die Wirksamkeit von Entscheidungsbäumen ist daher immer auch eine kontextabhängige Größe.
Darstellung in disjunktiver Normalform
Jede mögliche Klassifikation eines Entscheidungsbaumes lässt sich in Disjunktiver Normalform angeben. Hierzu betrachtet man alle Blätter dieser Klassifikation und deren Pfade zum Wurzelknoten. Für jeden dieser Pfade werden alle Bedingungen der Entscheidungsknoten entlang des Pfades miteinander in Konjunktion gesetzt und die dadurch entstehenden Terme in Disjunktion gesetzt. Für das oben abgebildete Beispiel ergibt sich für die Klassifikation „Apfelbaum trägt Früchte“ (ja) folgende Aussage:

Vor- und Nachteile
Interpretierbarkeit und Verständlichkeit
Ein großer Vorteil von Entscheidungsbäumen ist, dass sie gut erklärbar und nachvollziehbar sind. Dies erlaubt dem Benutzer, das Ergebnis auszuwerten und Schlüsselattribute zu erkennen. Das ist vor allem nützlich, wenn grundlegende Eigenschaften der Daten von vornherein nicht bekannt sind. Damit ist die Induktion von Entscheidungsbäumen auch eine wichtige Technik des Data-Minings.
Klassifikationsgüte in reellwertigen Datenräumen
Ein oft benannter Nachteil der Entscheidungsbäume ist die relativ geringe Klassifikationsgüte in reellwertigen Datenräumen, wenn man die Bäume zur automatischen Klassifikation einsetzt. So schneiden die Bäume aufgrund ihres diskreten Regelwerks bei den meisten Klassifikationsproblemen aus der realen Welt im Vergleich zu anderen Klassifikationstechniken wie beispielsweise Künstlichen Neuronalen Netzen oder Support-Vektor-Maschinen etwas schlechter ab. Das bedeutet, dass durch die Bäume zwar für Menschen leicht nachvollziehbare Regeln erzeugt werden können, diese verständlichen Regeln aber für Klassifikationsprobleme der realen Welt statistisch betrachtet oft nicht die bestmögliche Qualität besitzen.
Größe der Entscheidungsbäume und Überanpassung
Ein weiterer Nachteil ist die mögliche Größe der Entscheidungsbäume, wenn sich aus den Trainingsdaten keine einfachen Regeln induzieren lassen. Dies kann sich mehrfach negativ auswirken: Zum einen verliert ein menschlicher Betrachter schnell den Gesamtüberblick über den Zusammenhang der vielen Regeln, zum anderen führen solche großen Bäume aber auch meistens zur Überanpassung an den Trainingsdatensatz, so dass neue Datensätze nur fehlerhaft automatisch klassifiziert werden. Es wurden deshalb so genannte Pruning-Methoden entwickelt, welche die Entscheidungsbäume auf eine vernünftige Größe kürzen. Beispielsweise kann man die maximale Tiefe der Bäume beschränken oder eine Mindestanzahl der Objekte pro Knoten festlegen.
Weiterverarbeitung der Ergebnisse
Oft bedient man sich der Entscheidungsbäume nur als Zwischenschritt zu einer effizienteren Darstellung des Regelwerkes. Um zu den Regeln zu gelangen, werden durch verschiedene Verfahren unterschiedliche Entscheidungsbäume generiert. Dabei werden häufig auftretende Regeln extrahiert. Die Optimierungen werden überlagert, um einen robusten, allgemeinen und korrekten Regelsatz zu erhalten. Dass die Regeln in keinerlei Beziehungen zueinander stehen und dass widersprüchliche Regeln erzeugt werden können, wirkt sich nachteilig auf diese Methode aus.
Weiterentwicklungen und Erweiterungen
Entscheidungswälder
Eine Methode, um die Klassifikationsgüte beim Einsatz von Entscheidungsbäumen zu steigern, ist der Einsatz von Mengen von Entscheidungsbäumen anstelle von einzelnen Bäumen. Solche Mengen von Entscheidungsbäumen werden als Entscheidungswälder (englisch: decision forests) bezeichnet.
Der Gebrauch von Entscheidungswäldern zählt im maschinellen Lernen zu den sogenannten Ensemble-Techniken. Die Idee der Entscheidungswälder ist, dass ein einzelner Entscheidungsbaum zwar keine optimale Klassifikation liefern muss, die Mehrheitsentscheidung einer Menge von geeigneten Bäumen dies aber sehr wohl leisten kann. Verbreitete Methoden zur Erzeugung geeigneter Wälder sind Boosting, Bagging und Arcing.
Nachteil der Entscheidungswälder ist, dass es für Menschen nicht mehr so einfach ist, die in allen Bäumen enthaltenen Regeln in ihrer Gesamtheit in einfacher Weise zu interpretieren, so wie es bei einzelnen Bäumen möglich wäre.
Kombination mit Neuronalen Netzen
Entscheidungsbäume können mit neuronalen Netzen kombiniert werden. So ist es möglich, ineffiziente Äste des Baumes durch neuronale Netze zu ersetzen, um eine höhere, allein mit den Bäumen nicht erreichbare Klassifikationsgüte zu erreichen. Auch können die Vorteile beider Klassifikationsmethoden durch die Abbildung von Teilstrukturen in die jeweils andere Methodik genutzt werden: Die Bäume brauchen nicht so viele Trainingsdaten zur Induktion wie die neuronalen Netze. Dafür können sie ziemlich ungenau sein, besonders wenn sie klein sind. Die Neuronalen Netze hingegen klassifizieren genauer, benötigen aber mehr Trainingsdaten. Deshalb versucht man, die Eigenschaften der Entscheidungsbäume zur Generierung von Teilen neuronaler Netze zu nutzen, indem so genannte TBNN (Tree-Based Neural Network) die Regeln der Entscheidungsbäume in die neuronalen Netze übersetzen.
Praktische Anwendungen
Anwendungsprogramme
Es gibt etliche Anwendungsprogramme, die Entscheidungsbäume implementiert haben, so werden sie zum Beispiel in den Statistiksoftwarepaketen GNU R, Scikit-learn, SPSS und SAS angeboten. Die letzteren beiden Pakete verwenden übrigens – wie die meisten anderen Data-Mining-Software-Pakete auch – den CHAID-Algorithmus.
Kundenklassifikation
Eine Bank möchte mit einer Direct-Mailing-Aktion einen neuen Service verkaufen. Um den Gewinn zu maximieren, sollen mit der Aktion diejenigen Haushalte angesprochen werden, welche der Kombination von demografischen Variablen entsprechen, die der entsprechende Entscheidungsbaum als optimal erklärt hat. Dieser Prozess wird Data Segmentation oder auch Segmentation Modeling genannt.
Der Entscheidungsbaum liefert also gute Tipps, wer positiv auf den Versand reagieren könnte. Dies erlaubt der Bank, nur diejenigen Haushalte anzuschreiben, welche der Zielgruppe entsprechen.
Entscheidungsbäume in der BWL
Im Gebiet der Entscheidungslehre innerhalb der BWL werden Entscheidungsbäume von links nach rechts gezeichnet (und umgekehrt berechnet), um Payoffs aus Ausgaben und Einnahmen zu errechnen und die Entscheidung für maximalen Payoff zu optimieren.
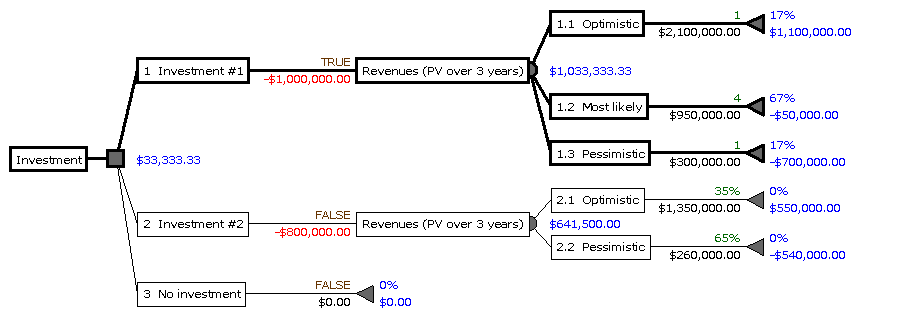
Bei diesen Entscheidungsbäumen stehen Quadrate für Entscheidungen, Kreise für Möglichkeiten, und Dreiecke terminieren die Zweige. Entscheidungsbäume dieses Typs können mit anderen Verfahren kombiniert werden, im Beispiel oben werden NPV (Net Present Value, Netto-Barwert), lineare Verteilung von Annahmen (Investment #2) und PERT 3-Punkt-Schätzung (Investment #1) verwendet.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 11.04. 2023