Überanpassung
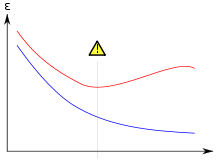
Rot: Fehler bzgl. Testdatensätzen
Wenn der Fehler bzgl. der Testdatensätze steigt, während der Fehler bzgl. der Trainingsdatensätze fällt, dann befindet man sich möglicherweise in einer Überanpassungssituation.
Überanpassung (englisch overfitting) bezeichnet eine bestimmte Korrektur eines Modells an einen vorgegebenen Datensatz. In der Statistik bedeutet Überanpassung die Spezifizierung eines Modells, das zu viele erklärende Variablen enthält.
Mathematische Definition
Gegeben sei ein Hypothesenraum  und eine Hypothese
und eine Hypothese  .
Dann wird
.
Dann wird  überangepasst an die Trainingsdaten
genannt, wenn es eine alternative Hypothese
überangepasst an die Trainingsdaten
genannt, wenn es eine alternative Hypothese  gibt, sodass
einen kleineren Fehler gegenüber
gibt, sodass
einen kleineren Fehler gegenüber  auf den Trainingsdaten aufweist, aber
einen kleineren Fehler als
in Bezug auf die Verteilung aller Instanzen hat.
auf den Trainingsdaten aufweist, aber
einen kleineren Fehler als
in Bezug auf die Verteilung aller Instanzen hat.
Statistik
In der multiplen Regression wird mit Überanpassung ein Modell charakterisiert, das zusätzliche, irrelevante Regressoren (erklärende Variablen) enthält. Werden dagegen relevante Variablen außer Acht gelassen (siehe Verzerrung durch ausgelassene Variablen), spricht man von Unteranpassung (englisch underfitting).
Durch die Aufnahme zusätzlicher Regressoren kann das Bestimmtheitsmaß
 ,
das die Güte
der Anpassung des Modells an die Daten der Stichprobe misst, nicht sinken.
Durch Zufallseffekte können so irrelevante Regressoren zur Erklärung der Varianz
beitragen und das Bestimmtheitsmaß künstlich erhöhen.
,
das die Güte
der Anpassung des Modells an die Daten der Stichprobe misst, nicht sinken.
Durch Zufallseffekte können so irrelevante Regressoren zur Erklärung der Varianz
beitragen und das Bestimmtheitsmaß künstlich erhöhen.
Überanpassung ist als negativ zu beurteilen, weil also die tatsächliche (geringere) Anpassungsgüte verschleiert wird und das Modell zwar besser auf die Daten der Stichprobe angepasst wird, allerdings aufgrund fehlender Generalität keine Übertragbarkeit auf die Grundgesamtheit besteht. Regressionskoeffizienten erscheinen fälschlicherweise als nicht signifikant, da ihre Wirkung nicht mehr hinreichend genau geschätzt werden kann. Die Schätzer sind ineffizient, d.h. ihre Varianz ist nicht mehr minimal. Gleichzeitig wächst die Gefahr, dass irrelevante Variablen aufgrund von Zufallseffekten als statistisch signifikant erscheinen. Überanpassung verschlechtert so die Schätzeigenschaften des Modells, insbesondere auch dadurch, dass eine zunehmende Anzahl von Regressoren die Anzahl der Freiheitsgrade verringert. Große Unterschiede zwischen dem unkorrigierten und dem korrigierten Bestimmtheitsmaß deuten auf Überanpassung hin. Überanpassung kann v.a. durch sachlogische Überlegungen und die Anwendung einer Faktorenanalyse entgegengewirkt werden.
Datensätze und überangepasste Modelle
Zunächst ist die Auswahl des Datensatzes, insbesondere die Zahl von Beobachtungen, Messpunkten oder Stichproben, ein wesentliches Kriterium für eine seriöse und erfolgreiche Modellbildung. Sonst erlauben die aus diesen Daten gewonnenen Annahmen überhaupt keine Rückschlüsse auf die Wirklichkeit. Dies gilt auch insbesondere für statistische Aussagen.
Die maximal mögliche Komplexität des Modells (ohne überanzupassen), ist proportional zur Repräsentativität der Trainingsmenge und somit auch zu deren Größe bei gegebenem Signal-Rausch-Verhältnis. Hieraus entsteht ebenfalls eine Interdependenz zur Verzerrung in endlichen Stichproben (englisch finite sample bias), so dass eine möglichst abdeckende und umfangreiche Trainingsdatensammlung anzustreben ist.
Anders ausgedrückt: Wer versucht, in vorhandenen Daten nach Regeln oder Trends zu suchen, der muss geeignete Daten wählen. Wer eine Aussage über die häufigsten Buchstaben des deutschen Alphabets treffen möchte, sollte dafür nicht nur einen einzelnen Satz betrachten, zumal wenn in diesem der Buchstabe „E“ selten vorkommt.
Überanpassung durch zu viel Training
Bei der rechnergestützten Modellbildung kommt ein zweiter Effekt hinzu. Hier wird in mehreren Trainingsschritten ein Datenmodell an vorhandene Trainingsdaten angepasst. Beispielsweise kann mit einigen Dutzend Schriftproben ein Rechner trainiert werden, dass er handgeschriebene Ziffern (0–9) richtig erkennt und zuordnet. Das Ziel ist hierbei, auch Handschriften von Personen erkennen zu können, deren Handschrift gar nicht in dem Trainingssatz enthalten war.
Folgende Erfahrung wird häufig gemacht: Die Erkennungsleistung für geschriebene Ziffern (unbekannter Personen) mit zunehmender Anzahl der Trainingsschritte nimmt zunächst zu. Nach einer Sättigungsphase nimmt sie aber wieder ab, weil sich die Datenrepräsentation des Rechners zu sehr an die Schreibweise der Trainingsdaten anpasst und nicht mehr an den zugrundeliegenden Formen der zu lernenden Ziffern selbst orientiert. Dieser Prozess hat den Begriff Überanpassung im Kern geprägt, auch wenn der Zustand der Überangepasstheit wie oben beschrieben eine Reihe von Gründen haben kann.
Wenn mit dem Modell kein Einsatz über die Trainingsmenge hinaus geplant ist, wenn also nur ein Modell für eine abgeschlossene Problemstellung gelöst wird, kann natürlich von Überanpassung nicht die Rede sein. Ein Beispiel hierfür wäre, wenn nur ein Rechnermodell für die abgeschlossene Menge von Vorfahrtsituationen im Straßenverkehr gesucht wird. Solche Modelle sind deutlich weniger komplex als das oben genannte und meistens kennt man die Regeln schon, so dass von Menschen verfasste Programme hier meist effizienter sind als maschinelles Lernen.
Kognitive Analogie
Ein überangepasstes Modell mag zwar die Trainingsdaten korrekt wiedergeben, da es sie sozusagen „auswendig gelernt“ hat. Eine Generalisierungsleistung, was einer intelligenten Klassifikation gleichkommt, ist allerdings nicht mehr möglich. Das „Gedächtnis“ des Modells ist zu groß, so dass keine Regeln gelernt werden müssen.
Strategien zur Vermeidung von Überanpassung
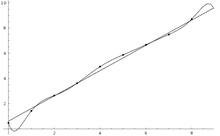
Wie bereits erwähnt, ist es günstig bei parametrischen Modellen eine möglichst geringe Anzahl an Parametern anzustreben. Bei nichtparametrischen Verfahren ist es analog ratsam die Anzahl der Freiheitsgrade ebenso von vornherein einzuschränken. Auf ein mehrlagiges Perzeptron würde das zum Beispiel eine Beschränkung in der Größe der verdeckten Neuronenschichten (englisch hidden layers) bedeuten. Eine Verringerung der Anzahl der notwendigen Parameter/Freiheitsgrade kann in komplexen Fällen auch dadurch ermöglicht werden, dass vor dem eigentlichen Klassifikations-/Regressionsschritt eine Transformation der Daten durchgeführt wird. Insbesondere wären hier Verfahren zur Dimensionsreduktion u.U. sinnvoll (>Hauptkomponentenanalyse, Unabhängigkeitsanalyse o.Ä.).
Um von der Trainingsdauer abhängige Überanpassung im Maschinellen Lernen zumindest erkennen (und somit ggf. handeln) zu können, werden Datensätze häufig nicht nur 2-fach aufgeteilt und einer Trainings- und Validierungsmenge zugeordnet, sondern es kann z.B. eine 3-fache Aufteilung erfolgen. Wobei die Mengen respektive und exklusiv zum Training, zur „Echtzeitkontrolle“ des Out-Of-Sample-Fehlers (und ggf. Trainingsabbruch bei Anstieg) und zur endgültigen Bestimmung der Testgüte verwandt werden.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 03.07. 2025