Datenmodellierung
Mit Datenmodellierung bezeichnet man in der Informatik Verfahren zur formalen Abbildung der in einem definierten Kontext relevanten Objekte mittels ihrer Attribute und Beziehungen. Hauptziel ist die eindeutige Definition und Spezifikation der in einem Informationssystem zu verwaltenden Objekte, ihrer für die Informationszwecke erforderlichen Attribute und der Zusammenhänge zwischen den Informationsobjekten, um so einen Überblick über die Datensicht des Informationssystems erhalten zu können. (vgl. Ferstl/Sinz 2006, S. 131).
Ergebnis sind hierbei Datenmodelle, die, mehrere Modellierungsstufen durchlaufend, letztlich zu einsatzfähigen Datenbanken bzw. Datenbeständen führen.
Datenmodelle haben eine in der Regel wesentlich längere Lebensdauer als Funktionen und Prozesse und somit Software. Es gilt: „Data is stable – functions are not“ („Daten sind stabil, Funktionen sind es nicht“). Datenmodellierung kann auch außerhalb von Projekten zur Anwendungsentwicklung betrieben werden, um bestimmte Sachverhalte darzustellen. Zum Beispiel können damit Daten oder andere Gegebenheiten eines bestimmten Unternehmensbereichs, einer Abteilung, eines Geschäftsprozesses (bis hin zum gesamten Unternehmen), aufgenommen und mit ihren Zusammenhängen dokumentiert werden. Auch lassen sich mit solchen Maßnahmen einheitliche Begriffe festlegen.
Verfahren
Die Datenmodellierung, als wesentliche Teildisziplin der Softwareentwicklung, verläuft über unterschiedliche Projektphasen. Die Aktivitäten sind prozessual angelegt, d.h. es gibt jeweils Ziele/Zwecke, Tätigkeiten und Ergebnisse, die, aufeinander aufbauend, über Zwischen- zu letztlich finalen Ergebnissen führen. Angelehnt an die ANSI-SPARC-Architektur entstehen dabei – auf bestimmte Meilensteine im Projekt bezogen – im Wesentlichen die folgenden Modell-Varianten:
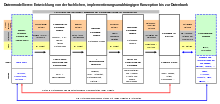
- Konzeptuelles Datenbankschema: Ausgehend von der Betrachtung eines Ausschnitts der realen Welt werden die relevanten Objekte mit allen relevanten Eigenschaften und die relevanten Beziehungen zwischen ihnen erhoben, analysiert sowie grafisch und textuell formuliert. Grundlage dazu sind Vorgaben oder Aussagen zur gegebenen Aufgabenstellung (= Kontext), die bei Bedarf durch Erörterung mit den Auftraggebern präzisiert werden.
- Logisches Datenbankschema: Das konzeptuelle Datenbankschema wird auf ein logisches Datenbankschema abgebildet. Dabei wird das Modell um datentechnische Angaben erweitert (z.B. Feldformate, identifizierende Suchbegriffe). Das logische Datenbankschema gehorcht den Regeln einer durch das zu verwendende DBMS gegebenen Struktur, z.B. dem relationalen Datenmodell, bei dem alle Daten in Tabellen abgelegt werden.
- Physisches Datenbankschema: Zur Umsetzung des Datenmodells mit einem bestimmten Datenbanksystem (DBMS) müssen zur Datenbankgenerierung alle Angaben in der Syntax des DBMS formuliert werden. Zum Teil ist dies unter Einsatz von Generatoren automatisch oder halbautomatisch möglich.
Mit diesen drei Modellebenen und dem Vorgehen dazu wird lediglich ein
grundsätzlicher Ansatz skizziert. Im Detail werden dieses Vorgehen, die
(Zwischen-)Ergebnisse und auch die Bezeichnungen
der Modelle von den häufig unternehmensspezifisch verwendeten Vorgehensmodellen
und von der benutzten Modellierungsmethodik und -Software bestimmt.
Beispiele:
- Bei Verwendung des späteren DBMS als Modellierungswerkzeug sind die Modellgrenzen fließend; die Modelle entwickeln sich sukzessive bis zur fertigen Datenbank.
- Für nicht unter einem DBMS zu führende Datenbestände wird (quasi als Datenbankschema-Ersatz) lediglich eine „Copystrecke“ erstellt, mit der die Datenstrukturdefinitionen in Programmen eingebunden und somit verwendet werden können.
In der Datenmodellierung werden im Allgemeinen nur Daten einbezogen, die zum fachlich-inhaltlichen Zweck der Systeme gehören, nicht jedoch jene, die im engeren Sinn zur Software zählen, z.B. Konfigurationsdaten, Parameterdaten. Letztere werden, als Voraussetzung für den technischen Betrieb, direkt in jeweils geeigneten Datenhaltungsformen installiert.
Tätigkeiten je Datenmodellstufe (Beispiele):
Zur Erläuterung der Vorgehensweise bei der Datenmodellierung sind nachfolgend beispielhaft einige Tätigkeiten genannt, die im Rahmen der jeweiligen Stufe Schwerpunkte sein können. Die Beispiele sind auf das Modellieren mit der Entity-Relationship-Methode und die Verwendung relationaler Datenbanken abgestellt.
Zum konzeptuellen Datenbankschema:
- Identifizieren des relevanten Informationsbedarfs (Attribute)
- Dabei: Identifizieren von Entitätstypen und Beziehungstypen
- Zuordnen der Attribute zu Entitätstypen
- Festlegen möglicher Attributwerte, Vorschläge für identifizierende Attribute
- Bestimmen der Beziehungskardinalität
- Fachliches Beschreiben der Entitäts- und Beziehungstypen und der Attribute
Zum logischen Datenbankschema:
- Methodisches Überprüfen der fachlich modellierten Ansätze (z.B. durch Normalisierung)
- Dabei: Bilden neuer Entitätstypen, z.B. durch Spezialisierung / Generalisierung
- Entscheidung: Mit welchem/n Datenhaltungssystem/en (DBMS, andere) sollen die Daten verwaltet werden?
- Überführen des ER-Modells in ein Relationenmodell
- Festlegen der identifizierenden Schlüssel
- Festlegungen zur technischen Umsetzung von Beziehungen: Fremdschlüssel, Beziehungstabellen
- Festlegen erweiterter Möglichkeiten für Direktzugriffe (Sekundärschlüssel)
- Festlegungen zur referentiellen Integrität
- Erweitern des Datenbankmodells im Zusammenhang mit Historien- und Versionsführung, Mandantenfähigkeit etc.
- Ergänzen des Modells um Lookup-Tabellen, Parametertabellen etc.
Zum physischen Datenbankschema:
- Optimierungsmöglichkeiten für Datenzugriffe (z.B. durch Index-Definitionen) einstellen
- Formulieren der Scripte / Kommandos zum Einrichten und Konfigurieren der Datenbank (in der Syntax des DBMS)
- Festlegungen zur Datensicherung
Methoden
Es gibt u.a. die folgenden Datenmodellierungsmethoden, die teils miteinander kombiniert werden:
- Bottom Up: Sammlung von Einzelattributen, Erkennen von potentiellen Schlüsseln, Gruppieren zu Objekttypen, Bilden von Beziehungen (Sonderform: Synthesealgorithmus)
- Top Down: Erkennen von Objekttypen, Bilden von Beziehungen, Erkennen von Elementarattributen
- Verallgemeinerung und Spezialisierung von Objekttypen im Sinne der Vererbung
- Re-Engineering existierender Schemata
- Aufstellen von Tabellen als Relationenmodell und Normalisierung
- Analyse existierender Listen, Ausgaben, Auswertungen etc.
Das Ergebnis der Datenmodellierung sind Datenmodelle, die etwa in Form des Entity-Relationship-Modells (ERM) vorliegen – und letztlich einsatzfähige Datenbanken. Ein ERM besteht aus einem Entity-Relationship-Diagramm (ERD), zum Beispiel gemäß UML oder IDEF1X, und einer textuellen Beschreibung des Modells und seiner Komponenten.
Entwurfsmuster: Wie in anderen Entwurfsprozessen der Informatik spielen auch in der Datenmodellierung Entwurfsmuster eine große Rolle, die zu einer Reihe von Fachgebieten vorliegen. Dazu gehören etwa Historisierung, Mehrsprachigkeit, Mandantenfähigkeit, aber auch Teilmodelle wie Adressen, Organisationsstrukturen, Rollen- und Rechtestrukturen etc. Auch vorgefertigte ganze Datenmodelle, etwa für den Finanzbereich, können als Entwurfsquelle dienen. Die am weitesten verbreiteten Muster sind bei Fowler, Hay und Silverston aufgeführt.
Metamodellierung: Ein wichtiges Gebiet für den Einsatz von Entwurfsmustern ist die Metamodellierung. Moriarty nennt diese Modellierung dynamic modelling. Bei einem Metamodell bildet im Gegensatz zum konkreten Datenmodell auch der Dateninhalt einen relevanten Teil des Datenmodells.
Unterschiedliche Begriffe für ähnliche Sachverhalte: Im praktischen Einsatz der Datenmodellierung werden nicht immer einheitliche Begriffe verwendet. Zum Teil ist dies methodenbezogen begründet, zum Teil in den jeweiligen Organisationen 'historisch gewachsen' (und nicht immer methodisch korrekt), zum Teil werden Begriffe aus unterschiedlichen Modellierungsstufen vermischt. Beispiele dafür sind:
- für Modellgrafiken: ER-Diagramm, Klassendiagramm, Datenmodell, Informationsstruktur, Informationslandkarte
- für Entitäten: Entity, Objekt, Informationsobjekt, Klasse, Tabelle, Zeile
- für Beziehungen: Relation, Fremdschlüssel
- für Attributswerte: Eigenschaft, Feld, Datenfeld, Attribut, Spalte.
Wie daraus ersichtlich ist, werden z.T. statt Typbegriffen (Entitätstyp …) die Instanzenbegriffe (Entität, Beziehung) verwendet oder schon die Begriffe aus der Datenbankimplementierung (Tabelle ...) benutzt. Abweichende Begriffe werden auch verwendet, wenn Beteiligte aus unterschiedlichen Unternehmen oder aus unterschiedlichen Abteilungen (Fachabteilung, Programmierung) kommunizieren. Im Interesse einer effizienten Kommunikation und zur Vermeidung von Missverständnissen sollte auf die Verwendung korrekter und einheitlicher Begriffe hingewirkt werden.
Unterstützung durch Software-Werkzeuge
Wie alle Prozesse zur Softwareentwicklung wird auch die Datenmodellierung unter Nutzung bestimmter Werkzeuge durchgeführt. In der Projektpraxis sind diesbezüglich sehr unterschiedliche Ansätze zu beobachten, die in den folgenden Beispielen skizziert werden:
- Lediglich Standardsoftware für Grafiken (für ERDs) und zur Textverarbeitung (für die Beschreibung von Komponenten) wird benutzt. Praktisch wird nur Freitext erfasst, evtl. durch Musterformulare gestützt; Qualitätssicherung kaum automatisierbar; keine Ausrichtung auf die spezielle Aufgabenstellung; nicht zu empfehlen.
- Einfache Spezialanwendungen, in denen Grafiksymbole und die Beschreibungen im Zusammenhang stehen. Beispiel: Doppelklick auf Entität öffnet deren Beschreibung; Bezeichnungen sind in Grafiken und Texten identisch; auf fremde Begriffe kann per Link verwiesen werden.
- Die Anwendung hat ein Metamodell, in dem festgelegt ist, welche Informationsdetails erfasst werden können / müssen. Das Werkzeug prüft die möglichen Eingaben und bestimmte Zusammenhänge. Z.B.: Einer Entität können nur existierende Attribute zugeordnet werden.
- Data-Dictionary: Die erarbeiteten Komponenten werden als Datenobjekte geführt und sind in mehreren Projekten verwendbar. Je Projekt werden nur Ausschnitte referenziert, Erweiterungen / Änderungen / Löschungen sind projektbezogen möglich etc.
- Weitere Leistungsbestandteile von DM-Werkzeugen, beispielhaft aufgeführt, können sein: Versionenkonzept, Dokumentations- und Auswertungsfunktionen, Mehrbenutzer- und Mehrprojektfähigkeit, Mandantenfähigkeit, Berechtigungs- und Sicherheitskonzept.
Als besonders hoch integriert können die folgenden Beispiele gelten:
- Universelles Spezifikationswerkzeug: Die für die Daten modellierten Modellinhalte werden auch von den Werkzeugen benutzt (referenziert), mit denen funktionale Spezifikationen erstellt werden. Die Datenkonstrukte sind darin etwa über einen Verwendungsnachweis abrufbar (Feld XYZ tritt auf in Formel ABC, Auswertung CDE, …).
- „Aktives Datadictionary“: Die Modellinhalte werden nicht nur im Projekt, sondern auch in der fertigen Anwendung benutzt – z.B. zur Anzeige von Feldnamen, Durchführung von Plausibilitätsprüfungen.
Der Integrationsgrad der Werkzeuge kann also sehr unterschiedlich sein. Er bestimmt maßgeblich die Qualität der Modellierungsprozesse, besonders ihre Effizienz.
Beispiele
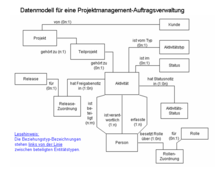
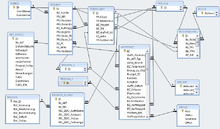
Beispiele für Datenmodelle sind etwa:
- Produkt, Kunde, Auftrag und Rechnung als „Objekttypen“ (Entitätstypen) in einem zu erstellenden oder zu beschaffenden Auftragsabwicklungssystem eines mittelständischen Handelsunternehmens aus der Sicht des Vertriebs. Das Modell dieses Realitätsausschnittes kann dazu dienen, die Spezifikation der funktionellen Anforderungen an das System vorzunehmen.
- Das Metamodell des in einem Forschungsbereich verwendeten Thesaurus, also die spezifische Terminologie mit ihren Synonyma und Unter- und Oberbegriffen sowie verwandten Begriffen als Nachschlagewerk für die in diesem Bereich arbeitenden Forscher. Für die Darstellung des resultierenden Datenmodells kann zum Beispiel eine Topic Map verwendet werden. Das Metamodell für diesen Thesaurus kann dazu dienen, eine Datenbank (ggf. inkl. IT-Anwendung) für die Erfassung der genannten Begriffe zu schaffen.
- Das semantische Datenmodell für eine Projektmanagement-Anwendung zur Auftragsverwaltung – wie in der Grafik 1 dargestellt.
- Das Datenbankschema als Grafik aus dem Implementierungswerkzeug MS Access für dieselbe Projektmanagement-Anwendung – Grafik 2 mit implementierungstechnischen Erweiterungen bzw. Abweichungen vom semantischen Modell. Ein Datenbankmodell als Zwischenstufe wurde hier nicht getrennt erstellt.
Es wird deutlich, dass die Relevanz des Realitätsausschnittes durch den jeweiligen Kontext und den spezifischen Zweck bestimmt wird.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 21.09. 2022