Metadaten

Metadaten oder Metainformationen sind strukturierte Daten, die Informationen über Merkmale anderer Daten enthalten.
Bei den durch Metadaten beschriebenen Daten handelt es sich oft um größere Datensammlungen wie Dokumente, Bücher, Datenbanken oder Dateien. So werden auch Angaben von Eigenschaften eines einzelnen Objektes (beispielsweise „Personenname“) als dessen Metadaten bezeichnet.
Anwendern von Computern ist oft nicht bewusst, dass Daten über nicht unmittelbar erkennbare Metadaten verfügen und dass diese unter Umständen einen größeren Nutzen für Computerkriminelle oder Behörden haben als die Daten selbst.
Einführende Beispiele
Typische Metadaten zu einem Buch sind beispielsweise der Name des Autors, die Auflage, das Erscheinungsjahr, der Verlag und die ISBN. Zu den Metadaten einer Computerdatei gehören unter anderem der Dateiname, die Zugriffsrechte und das Datum der letzten Änderung.
Unterscheidung zwischen Daten und Metadaten
Während der Begriff der Metadaten relativ neu ist, ist das Prinzip der Verweisung und der formalen Vorgaben schon jahrhundertelange bibliothekarische Praxis. Eine gültige Unterscheidung zwischen Metadaten und gewöhnlichen Daten existiert allerdings nur für den speziellen Fall, da die Bezeichnung eine Frage des Standpunkts ist. Für den Leser eines Buches sind der Inhalt die eigentlichen Daten, während der Name des Autors oder die Nummer der Auflage Metadaten sind. Für den Herausgeber eines Bücherkatalogs sind diese beiden Angaben dagegen Eigenschaften von Büchern allgemein, „Autor“ und „Auflagennummer“ sind Metadaten, die konkreten Ausprägungen („Karl May“, „17“) sind für ihn die eigentlichen Daten.
Zweckbestimmung
Versucht man zwischen Daten und Metadaten zu unterscheiden, so ist es hilfreich, den „Zweck“ als Begriff einzuführen. Der Zweck bestimmt das Ergebnis; um in der Lage zu sein, einen bestimmten Zweck zu erfüllen – ein bestimmtes Ergebnis zu erreichen –, werden Metadaten benötigt. Das Ergebnis kann aus Daten bestehen, insbesondere können Metadaten in ihrer Rolle als Daten Teil des Ergebnisses sein.
Beispiele:
- Zweck: Suche innerhalb einer Bibliothek nach allen Standorten (Signaturen) verfügbarer Bücher eines bestimmten Autors
- Metadaten: „Name des Autors“ und „verfügbar“
- Ergebnis: „Signatur“ (über die Signatur ist der Standort erschließbar)
Verwendung
In vielen Fällen findet keine bewusste Trennung zwischen Objekt- und Metaebene statt. Beispielsweise spricht man davon, in einem Katalog ein Buch zu suchen und nicht nur seine Metadaten. Bei der Verwendung von Metadaten wird oft erwartet, dass sie durch direkte Koppelung mit den Nutzdaten untrennbare Bestandteile eines abgeschlossenen, sich selbst beschreibenden Systems sind.
Metadaten werden oft dazu eingesetzt, um Informationsressourcen zu beschreiben und dadurch besser auffindbar zu machen und Beziehungen zwischen den Materialien herzustellen. Dies setzt in der Regel erst eine Erschließung mit einem gewissen Standardisierungsgrad (zum Beispiel durch Bibliothekarische Regelwerke) voraus.
Speicherung
Zur Speicherung von Metadaten gibt es verschiedene Möglichkeiten:
- Im Dokument selbst. So ist in einem Buch stets auch der Autor und das
Erscheinungsjahr verzeichnet.
In HTML-Dokumenten
werden mit Hilfe des Elements
<meta>beispielsweise Sprache, Autor, Unternehmen oder Schlagwörter angegeben. - In zugeordneten Nachschlagewerken, zum Beispiel für ein Buch in einer Bibliothek im Bibliothekskatalog.
- Bei Computerdateien in den Dateiattributen. Die meisten Dateisysteme erlauben nur genau festgelegte Metadaten in Dateiattributen; andere (HPFS mittels erweiterter Attribute) erlauben die Assoziation beliebiger Daten mit einer Datei. Auch ist es üblich, die Meta-Information „Dateityp“ im Dateinamen unterzubringen; typischerweise in der Dateinamenserweiterung oder in magischen Zahlen am Beginn der Datei.
Zur Speicherung und Übertragung von Metadaten gibt es eine Reihe von Datenformaten und Datenmodellen, wie beispielsweise Dublin Core oder EXIF, die sich in unterschiedliche, und somit auch in von Menschen lesbare Formate übertragen lassen.
Interoperable Metadaten
„Operabel“ bedeutet in fachsprachlichen Fügungen zunächst „so beschaffen, dass damit gearbeitet, operiert werden kann“. Die Vorsilbe „inter“ stammt aus dem Lateinischen und bedeutet so viel wie „zwischen“. Interoperable Metadaten sind also Metadaten aus potenziell unterschiedlichen Quellen, zwischen denen („inter“) eine Beziehung in der Weise besteht, dass mit ihnen gemeinsam gearbeitet („operiert“) werden kann.
Standards für interoperable Metadaten haben die Aufgabe, Metadaten aus unterschiedlichen Quellen nutzbar zu machen. Sie umfassen dazu zunächst die Aspekte Semantik, Datenmodell und Syntax.
Die Semantik beschreibt die Bedeutung, die in der Regel von Normierungs-Gremien festgelegt wird. Das Datenmodell legt fest, welche Struktur die Metadaten besitzen können. Als „Daten“ lassen sich im Zusammenhang mit Metadaten Aussagen auffassen, die über ein zu beschreibendes Objekt (Dokument, Ressource, …) getroffen werden. Als „Modell“-Komponente des Begriffs Datenmodell lässt sich eine Beschreibung dessen auffassen, wie die Aussagen strukturell beschaffen sind (der Begriff Datenmodell bedeutet damit im Kontext von Metadaten so viel wie „Grammatik“ oder „Struktur von Aussagen“). Beispiele für Datenmodelle von Metadaten sind einfache Attribut/Wert-Kombinationen (z.B. HTML-Meta-Elemente) oder Sätze mit Subjekt, Prädikat und Objekt (z.B. Tripel in RDF). Die Syntax dient schließlich dazu, die entsprechend dem Datenmodell generierten Aussagen zu repräsentieren. Beispiel für ein Repräsentationsformat ist XML (eXtensible Markup Language).
Zwischen diesen drei Aspekten besteht nun folgende Beziehung: Die Semantik wird durch Konstrukte des Datenmodells repräsentiert. Das Datenmodell wird wiederum durch syntaktische Konstrukte repräsentiert. Die syntaktischen Konstrukte werden schließlich aus Zeichen eines vereinbarten Zeichensatzes (wie bei Unicode) zusammengesetzt. Diese drei Aspekte lassen sich als hierarchisch übereinander liegende Schichten auffassen, da jede Schicht jeweils auf der darunter befindlichen Schicht aufbaut. Die Schichten sind dabei voneinander unabhängig, d.h. die Verwendung eines bestimmten Standards in einer Schicht erfolgt unabhängig von den anderen Schichten (wie die Schichtenmodelle der Netzwerkkommunikation, beispielsweise das ISO/OSI-Schichtenmodell). So kann eine bestimmte Semantik durch Konstrukte verschiedener Datenmodelle repräsentiert werden (z.B. Attribut/Wert-Kombination, Tripel), die wiederum durch verschiedene Syntaxen repräsentiert werden können (Graphen, XML-Formate).
Orthogonal zu diesen Schichten liegt als vierter Aspekt die Identifizierung, die alle drei Schichten betrifft. Um Metadaten verschiedener Quellen sinnvoll verarbeiten zu können, muss (weltweit) eindeutig gekennzeichnet werden, um welche Semantik, welches Datenmodell und welche Syntax es sich handelt. Hierzu ist ein Identifikationsmechanismus erforderlich, wie ihn die URIs (Uniform Resource Identifier) bereitstellen.
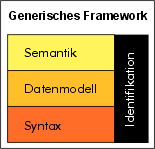
Alle vier Aspekte – Semantik, Datenmodell, Syntax und Identifizierung – sind erforderlich, um Standards für interoperable Metadaten zu schaffen. Sie können daher gemeinsam in ein Framework eingeordnet werden. Ein Framework bietet also eine Art Grundgerüst oder Gerippe, das bereits die wichtigsten Elemente bzw. Komponenten eines Systems und deren Beziehungen beschreibt, jedoch ohne genaue Vorgaben hinsichtlich deren Ausgestaltung zu machen. Es fungiert somit als eine Art „Bezugssystem“, das die sinnvolle Eingliederung neuer Komponenten ermöglicht. Da ein Framework Elemente und deren Beziehungen zeigt, kann dies leicht durch die grafische Anordnung von Elementen visualisiert werden. Die Abbildung „Generisches Framework“ zeigt ein Framework für Metadaten, auf einer Metaebene. Im Gegensatz zu konkreten Ausprägungen von Frameworks, d.h. also der Ausprägungs- oder Instanzenebene, beschreibt ein Framework auf der Metaebene ein verallgemeinertes Framework – erkennbar an den generischen Bezeichnungen der Bestandteile.
Als Beispiel für ein konkretes Framework für Metadaten sei RDF (Resource Description Framework) des World Wide Web Consortium (W3C) genannt. RDF enthält alle der oben genannten vier Aspekte mit spezifischen Ausprägungen, wie in der Abbildung dargestellt.

Die Komponenten im Detail:
- Semantik: Domänenspezifische Semantiken können über Namensräume importiert werden, womit die Semantik eines RDF-Vokabulars beliebig erweitert werden kann
- Datenmodell: RDF besitzt ein festgelegtes Datenmodell, das Aussagen über Ressourcen in Form von Tripeln mit Subjekt, Prädikat und Objekt gestattet
- Syntax: Zur Repräsentation solcher Aussagen kann eine beliebige Syntax verwendet werden, RDF/XML, Graphen, oder die N-Triple-Notation; RDF/XML ist jedoch die normative Syntax
- Identifikation: Als universeller Identifikations-Mechanismus werden URIs verbindlich vorgeschrieben
Der Idee eines Frameworks folgend definiert RDF selbst keine domänenspezifische Semantik, sondern spezifiziert lediglich einen Mechanismus, wie über Namensräume mit Hilfe einer URI weitere Semantiken eingebunden werden können. Verbindlich legt RDF hingegen ein gemeinsames Datenmodell in Form von Tripeln fest sowie die universelle Verwendung von URIs als Identifikationsmechanismus. Diese werden sowohl eingesetzt, um die einzelnen Komponenten eines Tripels (Subjekt, Prädikat, Objekt) zu kennzeichnen, als auch deren Werte und Datentypen. Die konkrete Syntax zur Repräsentation der Tripel kann jedoch, wiederum dem Gedanken eines Frameworks folgend, frei gewählt werden, wobei RDF/XML als Standard vorgesehen ist. Mit RDF Schema enthält RDF außerdem noch eine Schema-Sprache, um eigene Metadaten-Vokabulare zu definieren.
RDF-Schema verhält sich zu RDF ähnlich wie XML Schema zu XML. Ein RDF Schema ist gleichzeitig ein gültiges RDF-Dokument, ebenso ist ein XML Schema gleichzeitig ein gültiges XML-Dokument. In beiden Fällen handelt es sich also um spezialisierte Teilmengen einer Auszeichnungssprache. Während XML Schema jedoch syntaktische Einschränkungen beschreibt, z.B. Elementnamen, Häufigkeit des Auftretens etc., beschreibt RDF Schema semantische Einschränkungen, also z.B. dass ein Attribut „hasPublished“ nur auf Instanzen der Klasse „Mensch“ oder „juristischePerson“ angewendet werden darf, nicht jedoch auf Instanzen der Klasse „Tier“ – in der Schemasprache formuliert, hat das Attribut „hasPublished“ die Domäne „Mensch“ oder „juristischePerson“.
Wie XML dem Grundsatz der Einfachheit und Erweiterbarkeit folgend die Welt der Daten gründlich veränderte, in dem es durch eine einheitliche Syntax, ein genormtes Typsystem und seine Textbasiertheit die Definition problemlos zwischen verschiedenen Systemen und Programmen austauschbarer Datenformate ermöglichte, versucht RDF die Welt der Metadaten durch ein einheitliches Datenmodell zu verändern. Durch den Charakter eines Frameworks knüpft RDF dabei ebenfalls an bewährte Grundsätze wie Einfachheit und Erweiterbarkeit an.
Beispiele in Anwendungsgebieten
Die folgenden Abschnitte liefern Beispiele und Standardformate für Metadaten in Anwendungsgebieten auf.
Metadaten in der Statistik
In statistischen Datenbanken werden diejenigen Daten als Metadaten bezeichnet, die nicht direkt den Inhalt einer Statistik darstellen, so als Branchen- oder Berufsbezeichnungen, Gemeindeverzeichnisse und andere Kataloge. Zu den statistischen Metadaten zählen auch Beschreibungen der Datenfelder in Umfrageformularen, unter Umständen auch komplette Formularbeschreibungen. Die eigentlichen statistischen Daten bezeichnet man in Abgrenzung zu den Metadaten als Mikrodaten und Makrodaten.
In der Umfrageforschung werden spezielle Metadaten zur Umfrage als Paradaten bezeichnet.
Metadaten bei Geodaten
In der INSPIRE-Richtlinie sowie in dem darauf aufbauenden Gesetz über den Zugang zu digitalen Geodaten (Geodatenzugangsgesetz – GeoZG) findet sich eine Legaldefinition für Metadaten im Bereich der Geoinformationsverarbeitung: „Metadaten sind Informationen, die Geodaten oder Geodatendienste beschreiben und es ermöglichen, Geodaten und Geodatendienste zu ermitteln, in Verzeichnisse aufzunehmen und zu nutzen.“ (§ 3 Abs. 2 GeoZG)
Metadaten in der Softwareentwicklung
In der Softwareentwicklung wird der Metadatenbegriff für verschiedene Zwecke gebraucht:
- Man bezeichnet Bestandteile eines Programmquelltextes als Metadaten, die nicht vom eigentlichen Übersetzungswerkzeug, meist einem Compiler, sondern Zusatzwerkzeugen ausgewertet werden. Diese Metadaten werden meist zur Dokumentation oder mit Hilfe von Annotationen zur Codegenerierung eingesetzt. Beispiele sind die Annotations in Java oder die Attribute innerhalb des .Net-Frameworks.
- Eine von der klassischen Programmierung abweichende Form ist die Verwendung von Metadaten in Universal-Software. Hierbei sind die meisten benötigten Anwendungsfunktionen vorkompiliert vorhanden und werden über eine Metadaten-Engine aufgerufen und parametrisiert. Die gewünschte Zielanwendung muss vorher mittels spezifischer Metadaten deklarativ beschrieben werden. Dieser Ansatz wird insbesondere von Data-Warehouse- und Business-Intelligence-Produkten verfolgt. Einige Hersteller wie Tenfold, Data-Warehouse GmbH und Scopeland Technology wenden dieses Prinzip auch auf die Erstellung schreibender Datenbankanwendungen an.
- Unter Metadaten versteht man auch die Datensatzdefinition in einem Data-Dictionary einer Datenbank.
- Als Metadaten können auch die Informationen in der Software-Versionsverwaltung gelten. Diese machen es oft möglich, den Autor einer jeden Zeile eines Programmcodes zu identifizieren. Dafür werden Nutzdaten (der Quellcode) und Metadaten aus dem Versionsverwaltungsarchiv korreliert. Bei vielen Versionsverwaltungssoftwaren (etwa Git und SVN) heißt dieser fest eingebaute Befehl blame (eng. für beschuldigen).
Metadaten digitaler Bilder
Metadaten digitaler Fotos, wie Aufnahmedatum/-zeit, Brennweite, Blende, Belichtungsdauer und andere technische Parameter (ggf. auch geographische Koordinaten des Aufnahmeorts), werden heute von nahezu allen Digitalkameras am Anfang einer Bilddatei im Exif-Format abgespeichert. Durch geeignete Software kann ein digitales Bild (Foto, Scan oder Grafik) durch Metadaten im IPTC-Format angereichert werden; dabei können im Wesentlichen Angaben gemacht werden zu Bildtitel, Bildbeschreibung, Aufnahmeort (GPS-Koordinaten/Ort/Bundesland/Land), Autor (Fotograf) bzw. Urheberrechts-Inhaber, Kontaktdaten des Urheberrechts-Inhabers oder Lizenzgebers, Urheberrechts-Bestimmungen und Suchbegriffe (Schlüsselwörter). Viele Bildbearbeitungsprogramme ergänzen oder verändern beim Bearbeiten von digitalen Fotos (bzw. Bildern im Allgemeinen) die Metadaten zusätzlich, sodass sich Rückschlüsse auf die Bildbearbeitungssoftware ziehen lässt.
Metadaten bei der Kommunikation im Internet
Das Internet-Protokoll folgt einem Schichtenmodell. Am Beispiel des Standards zum Versenden von E-Mails soll dies illustriert werden. Das zur Übermittlung von E-Mails gebräuchliche Protokoll lautet Simple Mail Transfer Protocol. Seine Position in der Internetprotokollschicht lässt sich genau angeben:
| Anwendung | SMTP | ||||
| Transport | TCP | ||||
| Internet | IP (IPv4, IPv6) | ||||
| Netzzugang | Ethernet | Token Bus |
Token Ring |
FDDI | … |
Aus Sicht der Versender und Empfänger von E-Mails können alle Schichten unterhalb der Anwendungsschicht als Metadaten angesehen werden. Das wird besonders augenfällig, wenn die Anwendungsschicht verschlüsselt wird. Selbst dann kodiert bereits die Transportschicht (TCP) genügend Informationen, um den Namen des sendenden und empfangenden Servers (oft der globale Teil einer E-Mail-Adresse) sowie Nachrichtenlänge und Zeitraum der Sendung zu ermitteln. Bei häufigem E-Mail-Verkehr zwischen zwei Parteien kann die bloße Frequenzinformation einem recherchierenden Dritten Rückschlüsse auf den Inhalt der E-Mails erlauben.
Die gleiche Situation ergibt sich prinzipiell mit anderen Netzwerkprotokollen, etwa Instant-Messaging-Diensten oder dem World Wide Web. Allgemein spricht man in diesem Zusammenhang von Verkehrsdaten oder Randdaten.
Nach  §206 Abs. 5 des deutschen
Strafgesetzbuchs zählen neben dem Inhalt der Telekommunikation auch „ihre
näheren Umstände, insbesondere die Tatsache, ob jemand an einem
Telekommunikationsvorgang beteiligt ist oder war“ zum Fernmeldegeheimnis.
§206 Abs. 5 des deutschen
Strafgesetzbuchs zählen neben dem Inhalt der Telekommunikation auch „ihre
näheren Umstände, insbesondere die Tatsache, ob jemand an einem
Telekommunikationsvorgang beteiligt ist oder war“ zum Fernmeldegeheimnis.
Gesellschaftskritik
Der italienische Philosoph und Medientheoretiker Matteo Pasquinelli hat die These aufgestellt, dass mit der Datenexplosion eine neue Steuerungsform möglich werde: eine „Gesellschaft der Metadaten“. Mit Metadaten könnten neue Formen der biopolitischen Steuerung zur Kontrolle der Massen und Verhaltenssteuerung etabliert werden, etwa Online-Aktivitäten in sozialen Netzwerken oder Passagierströme in öffentlichen Verkehrsmitteln. Das Problem sieht Pasquinelli nicht darin, dass Individuen wie in totalitären Systemen auf Schritt und Tritt überwacht werden, sondern vermasst werden und die Gesellschaft als Aggregat berechenbar und kontrollierbar werde.
Literatur
- Gunnar Auth: Metadaten – Grundlagen und Bedeutung im Data Warehousing. In: Gunnar Auth: Prozessorientierte Organisation des Metadatenmanagements für Data-Warehouse-Systeme. BoD, Norderstedt 2004, ISBN 978-3-8334-1926-3, S. 27–74.
- Ingrid Schmidt: Modellierung von Metadaten. In: Henning Lobin; Lothar Lemnitzer: Texttechnologie. Perspektiven und Anwendungen. Stauffenburg, Tübingen 2004, ISBN 3-86057-287-3, S. 143–164.
- Ulrich Hambuch: Erfolgsfaktor Metadatenmanagement: Die Relevanz des Metadatenmanagements für die Datenqualität bei Business Intelligence. Vdm, Saarbrücken 2008, ISBN 3-639-07879-9


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 02.10. 2022