Referentielle Integrität
Referentielle Integrität (RI) ist ein Begriff aus der Informatik. Man versteht darunter Bedingungen, die zur Sicherung der Datenintegrität bei Nutzung relationaler Datenbanken beitragen können. Nach der RI-Regel dürfen Datensätze (über ihre Fremdschlüssel) nur auf existierende Datensätze verweisen.
Danach besteht die RI grundsätzlich aus zwei Teilen:
- Ein neuer Datensatz mit einem Fremdschlüssel kann nur dann in einer Tabelle eingefügt werden, wenn in der referenzierten Tabelle ein Datensatz mit entsprechendem Wert im Primärschlüssel oder einem eindeutigen Alternativschlüssel existiert.
- Eine Datensatzlöschung oder Änderung des Schlüssels in einem Primär-Datensatz ist nur möglich, wenn zu diesem Datensatz keine abhängigen Datensätze in Beziehung stehen.
Definitionen
„Die referentielle Integrität (auch Beziehungsintegrität) besagt, dass Attributwerte eines Fremdschlüssels auch als Attributwert des Primärschlüssels vorhanden sein müssen.“
„Über die referentielle Integrität werden in einem DBMS die Beziehungen zwischen Datenobjekten kontrolliert.“
Begriffe und ihre Bedeutung
Ursprung/Hintergrund: Nach der Relationentheorie werden zu speichernde Daten i.d.R. auf mehrere Tabellen aufgeteilt. Die Datensätze dieser Tabellen weisen untereinander meist logische Zusammenhänge (Beziehungen) auf. Siehe Beispiel „Bücherei“: Buch X ist entliehen von Büchereibenutzer Y. Daraus entstand die Anforderung, die Konsistenz dieser „Referenzen“ bei Bedarf durch ein besonderes und sicheres Konzept (die „RI“) schützen zu können.
Nach der wörtlichen Bedeutung bezeichnet „RI“ einen gegebenen oder beabsichtigten Qualitätszustand von Daten: Integer (makellos, heil, „ganz“) im Hinblick auf die darin enthaltenen gegenseitigen Referenzen. Gleichzeitig versteht man unter „RI“ jedoch auch die Integritätsregel bzw. die funktionale Unterstützung, durch die ein DBMS diese Qualität sichert.
Die RI-Regel ist eine Erweiterung bei der Spezifikation von Beziehungstypen – die meist eine Kardinalität von 1:n aufweisen. Die darin beteiligten Entitätstypen bezeichnet man – rollenspezifisch für genau einen Beziehungstyp, nicht generell für die Tabelle geltend – als Mastertabelle und Detailtabelle. Wirksam sind diese Festlegungen für die in konkreten Beziehungen stehenden Datensätze. Master- und Detailtabelle kann auch dieselbe Tabelle sein (rekursive Beziehungen).
Andere Bezeichnungen für Mastertabelle sind Primär-, Parent-,
Eltern-
oder referenzierte Tabelle. Die Detailtabelle wird auch verknüpfte*,
Child/Kind-, abhängige, verwandte*, referenzierende, verweisende Tabelle
oder „Tabelle mit dem Fremdschlüssel“ genannt.
(*) = begrifflich eher
ungeeignet, weil das Abhängigkeitsverhältnis unklar bleibt.
Ein klassischer Fall für RI-Spezifikationen inkl. Löschweitergabe sind sog. Beziehungstabellen, die häufig nur die Fremdschlüssel der an einer n:m-Beziehung beteiligten Datensätze enthalten. Verweise auf nicht existente Primärdatensätze darf es hier nicht geben; wird einer der beiden Primärdatensätze gelöscht, so kann/muss auch der Datensatz in der Beziehungstabelle gelöscht werden.
Abgekürzt wird der (etwas sperrige) Begriff „referentielle Integrität“ (im Englischen “referential Integrity”) häufig mit RI oder R.I., auch wird verbreitet die neue deutsche Rechtschreibung (referenziell mit „z“) verwendet.
Abgrenzung:
- Neben der referentiellen Integrität kennt man (als Teilaspekte von Datenqualität und -Konsistenz) weitere Integritätsbedingungen wie die Wertebereichsintegrität (gültige Werte auf Datenfeldebene), die Eindeutigkeit von Schlüsselbegriffen. Darüber hinaus sichern Datenbanksysteme vor allem im Mehrbenutzerbetrieb die Konsistenz von Daten auf Transaktionsebene (alle oder keine Updates, z.B. bei technischem Abbruch) sowie gegen Updates konkurrierender Benutzer/Transaktionen.
- RI-ähnliche Konsistenzbedingungen in nicht relational gespeicherten Datenbeständen fallen nicht unter den Begriff 'referentielle Integrität', sondern werden mit anderen Mitteln überprüft, z.B. individuell in der IT-Anwendung. Beispiel: Daten in Konfigurations und Registrydateien, Hyperlinks in Wikis etc.
Erweiterungen / Besonderheiten
Während die RI grundsätzlich vor inkonsistenten Datenaktionen schützt, bieten viele Datenbanksysteme Zusatzfunktionen an, die bei Updates von Master-Datensätzen nützlich sein können:
- Änderungsweitergabe (ÄW)
- Wenn der eindeutige Schlüssel eines Datensatzes geändert wird, kann das DBMS die Fremdschlüssel in allen abhängigen Datensätzen anpassen – anstatt die Änderung abzulehnen. Änderungsweitergabe wird insbesondere dann benutzt, wenn natürliche Schlüssel (die sich ändern können; Familienname bei Heirat) verwendet werden; denn künstliche Schlüssel sind i.d.R. unveränderlich und eine Änderungsweitergabe nicht erforderlich.
- Löschweitergabe (LW)
- In bestimmten Fällen ergibt es einen Sinn, abhängige Datensätze bei Löschung des Masterdatensatzes mitzulöschen.
Diese Funktionen können in der RI-Spezifikation optional gesetzt und (je nach DBMS) durch zusätzliche Bedingungen (siehe Beispiel) erweitert/präzisiert werden. Sie wirken nur bei Updates von Masterdatensätzen, Detaildaten können jederzeit gelöscht oder anderen (vorhandenen) Mastersätzen zugeordnet werden.
Weitere Besonderheiten im Zusammenhang mit der RI sind:
- Rekursive Beziehungen
- Die RI kann sich auch auf Daten in nur einer Tabelle beziehen, etwa wenn sich in der Tabelle ABTEILUNG Unterabteilungen ihrer gemeinsamen Hauptabteilung zuordnen.
- Kaskadierung
- Wenn die abhängigen Datensätze aus einer RI-Beziehung selbst wiederum Primärdatensatz sind, kann sich die RI-Regel auch auf deren abhängige Sätze beziehen. Eine Lösch- oder Änderungsweitergabe kann also mehrstufig wirken.
- Beziehung auf sich selbst
- In bestimmten Situationen kann ein Detaildatensatz auch auf sich selbst verweisen. Beispiel: Die Beziehung „Ort gehört zu Kreisstadt“ in der Tabelle ORT: Der Datensatz des Ortes, der die Kreisstadt ist, verweist mit dem Fremdschlüssel „Kreisstadt“ auf sich selbst. In solchen Fällen wird jedoch häufig auch ein Nullwert verwendet – was als „ist selbst Kreisstadt“ interpretiert werden kann.
Handlungs- und Wirkungsebenen

Die RI wird im Verlauf der Datenmodellierung als relevant erkannt, festgelegt und in der jeweiligen Syntax spezifiziert. Dies geschieht je Beziehungstyp (häufig vereinfachend nur „Beziehung“ genannt), an dem jeweils mehrere Entitätstypen (= Tabellen) beteiligt sind. Die Spezifikationen sind Teil des einmalig erstellten Datenbankschemas.
Aufgrund dieser Angaben überprüft das DBMS bei der Ausführung von ändernden Datenoperationen im laufenden Betrieb die Einhaltung der RI-Regeln. Solche Operationen werden von IT-Anwendungen (ggf. nach einer Eingabe bzw. Erfassung von Benutzern) ausgelöst und führen bei Einhaltung der Regeln zu Veränderungen im Datenbestand, ansonsten zu Fehlermeldungen bei unverändertem Bestand.
Beispiel
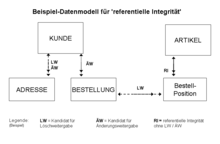
Die nebenstehende Grafik zeigt am Beispiel eines einfachen ER-Diagramms, welche Überlegungen im Zusammenhang mit der Festlegung von RI-Regeln angestellt werden können:
- Wenn es möglich ist, dass sich der Primärschlüssel von „KUNDEN-Einträgen“ ändert, sollten auch die in BESTELLUNG enthaltenen Fremdschlüssel automatisch mitgeändert werden: RI mit Änderungsweitergabe.
- Wenn ADRESSEN immer nur zu genau einem KUNDEN gehören, ergibt es einen Sinn, diese bei Löschung des KUNDEN (d.h. der Daten über ihn) automatisch mitzulöschen: RI mit Löschweitergabe.
- Da sich BESTELLUNGEN immer auf ARTIKEL beziehen (über „Bestell-Position“), muss verhindert werden, dass ein ARTIKEL im Datenbestand gelöscht wird, wenn noch BESTELLUNGEN (mit Positionen) vorhanden sind. Umgekehrt dürfen nur solche Bestellpositionen angelegt werden, die sich auf einen (im Datenbestand) existenten ARTIKEL beziehen: Normale RI ohne LW/ÄW.
- Wenn Löschweitergabe in der Beziehung „KUNDE:BESTELLUNG“ nicht definiert ist, würde die Löschung eines KUNDEN bei Existenz von BESTELLUNGEN (dieses Kunden) abgelehnt werden. Wäre Löschweitergabe spezifiziert, so würde im Fall der Kundenlöschung ein „kaskadierendes Löschen“ (inkl. Bestellposition) eintreten.
- Ohne jegliche RI-Spezifikation müsste die Anwendung / der Benutzer selbst für die Konsistenz der Datenbeziehungen Sorge tragen; sonst könnten inkonsistente Daten entstehen, die zur Folge hätten, dass in der automatischen Verarbeitung dieser Daten z.B. keine Versand-ADRESSE und kein Rechnungsempfänger (Kunde) bekannt wäre.
DBMS-abhängige Unterschiede
Der Umfang an Unterstützung zur RI, den Datenbanksysteme leisten können, kann unterschiedlich sein. Neben der Grundfunktion, die RI überhaupt zu schützen, kann das zum Beispiel die folgenden Zusatzaspekte betreffen:
- Löschweitergabe, Änderungsweitergabe
- kaskadierende Lösch- oder Änderungsweitergabe
- zusätzliche Bedingungen, unter denen die Lösch- und Änderungsweitergabe erfolgen soll
- RI über die Daten mehrerer Datenbanken hinweg.
RI-Darstellung in Datenmodellen / Diagrammen
Zur Darstellung der referentiellen Integrität in Datenmodellgrafiken werden kaum einheitliche Regeln angewendet. In manchen Modell-Werkzeugen wird der Beziehungspfeil bei RI fett dargestellt. Zusatzfunktionen wie Löschweitergabe sind meist nur textuell in den spezifizierten Beziehungstypen bzw. im Quellcode des Datenbankschemas sichtbar.
Technische Umsetzung
Technisch wird die referentielle Integrität über einen so genannten Fremdschlüssel realisiert. Die beteiligten Relationen (= Tabellen) benötigen gleichartige Attribute, die in der abhängigen Tabelle als Fremdschlüssel und in der anderen Relation als Primärschlüssel verwendet werden. Beide Attribute müssen vom selben oder einem kompatiblen Datentyp sein. Die Datensätze verweisen („referenzieren“) mit dem Fremdschlüssel auf Datensätze mit identischem Wert in ihrem Primärschlüssel. Das DBMS stellt sicher, dass nur Verweise auf existierende Datensätze möglich sind und überprüft dies beim Anlegen oder Löschen von Datensätzen oder beim Ändern von Schlüsselfeldern.
Bei Systemen, die nach dem Transaktionsprinzip arbeiten, werden bei Verletzung von RI-Regeln alle innerhalb der Transaktion getätigten Updates zurückgesetzt (Rollback).
Primärschlüssel und Fremdschlüssel können auch aus mehreren Attributen/Tabellenspalten bestehen.
Die Festlegung sinnvoller RI-Regeln, insbesondere der Lösch-Weitergabe, sind eine wichtige Aufgabenstellung beim Datendesign, um ungewollte Löschmengen oder nicht durchführbare Löschweitergaben zu verhindern.
Nachteile
Die Vorteile der referentiellen Integrität haben aber auch ihren Preis, denn jede Prüfung, die von einem RDBMS vorgenommen wird, kostet Rechnerressourcen, insbesondere Zeit.
So könnte es z.B. bei einem eventuell regelmäßigen Importieren größerer Datenmengen zweckmäßig sein, im aufnehmenden System die RI-Regeln temporär außer Kraft zu setzen, besonders wenn im Liefersystem die Konsistenz der Daten gesichert ist.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 15.06. 2020