Anscombe-Quartett
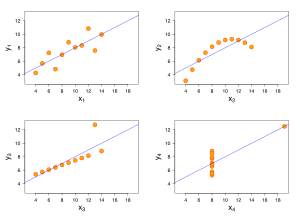
Das Anscombe-Quartett besteht aus vier Mengen von Datenpunkten, die nahezu identische einfache statistische Eigenschaften haben, aber aufgetragen sehr verschieden aussehen. Jede dieser vier Mengen besteht aus elf (x,y)-Punkten. Diese vier Mengen wurden im Jahre 1973 von dem englischen Statistiker Francis Anscombe konstruiert, um die Bedeutung einer graphischen Datenanalyse herauszustellen und die Effekte von Ausreißern zu demonstrieren.
Darstellung
Für die vier Punktmengen gilt:
-
Eigenschaft Wert Mittelwert von x in jedem Fall 9 (exakt) Varianz von x in jedem Fall 11 (exakt) Mittelwert von y in jedem Fall 7,50 (auf 2 Stellen) Varianz von y in jedem Fall 4,122 oder 4,127 (auf 3 Stellen) Korrelation zwischen x und y in jedem Fall 0,816 (auf 3 Stellen) Lineare Regression in jedem Fall y = 3,00 + 0,500x (auf 2 bzw. 3 Stellen)
Das erste Streudiagramm (oben links) scheint einen einfachen linearen Zusammenhang nahezulegen, die beiden Variablen erscheinen korreliert. Das zweite Streudiagramm (oben rechts) zeigt zwar einen Zusammenhang zwischen den Variablen, offensichtlich ist dieser aber nicht linear. Im dritten Streudiagramm (unten links) liegt anscheinend ein linearer Zusammenhang vor, allerdings gibt es einen Ausreißer. Das vierte Streudiagramm (unten rechts) zeigt ebenfalls einen Ausreißer, während die übrigen Datenpunkten alle übereinander liegen (gleicher x Wert). Berechnet man den Bravais-Pearson-Korrelationskoeffizienten (als Maß für den linearen Zusammenhang) so ergibt sich für alle vier Datensätze der Wert 0,816. Jedoch nur für das obere linke Streudiagramm wird der Zusammenhang damit korrekt beschrieben.
Das Anscombe-Quartett wird benutzt, um die Bedeutung der graphischen Datenanalyse herauszustellen, die erfolgen sollte, bevor man aufgrund einer Annahme über die statistischen Eigenschaften der Daten mit der Analyse beginnt. Weiterhin zeigt es, dass einfache statistische Maßzahlen zur Beschreibung der Daten nicht immer ausreichen.
Die vier Mengen von Datenpunkte sind in der nachstehenden Tabelle zusammengefasst. Die x-Werte sind dabei für die ersten drei Mengen dieselben.
-
Das Anscombe-Quartett I II III IV x y x y x y x y 10,0 8,04 10,0 9,14 10,0 7,46 8,0 6,58 8,0 6,95 8,0 8,14 8,0 6,77 8,0 5,76 13,0 7,58 13,0 8,74 13,0 12,74 8,0 7,71 9,0 8,81 9,0 8,77 9,0 7,11 8,0 8,84 11,0 8,33 11,0 9,26 11,0 7,81 8,0 8,47 14,0 9,96 14,0 8,10 14,0 8,84 8,0 7,04 6,0 7,24 6,0 6,13 6,0 6,08 8,0 5,25 4,0 4,26 4,0 3,10 4,0 5,39 19,0 12,50 12,0 10,84 12,0 9,13 12,0 8,15 8,0 5,56 7,0 4,82 7,0 7,26 7,0 6,42 8,0 7,91 5,0 5,68 5,0 4,74 5,0 5,73 8,0 6,89
Mithilfe von evolutionären Algorithmen lassen sich inzwischen solche Datensätze, deren wichtigste statistische Kennzahlen identisch sind, die aber in grafischer Darstellung völlig unterschiedliche Eigenschaften zeigen, automatisch erzeugen.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 17.05. 2020