Datenbank-Muster
Relationale-Datenbank-Muster sind Muster, die im Entwurf relationaler Datenbanken eingesetzt werden.
Grundlegende Tabellentypen
- Referenztabelle
- Eine Referenztabelle ist eine Tabelle, die über die Zeit relativ konstant bleibt und relativ wenige Spalten aufweist. Häufig anzutreffen sind dabei Key-Value-Referenztabellen mit nur zwei Spalten. Als Schlüssel sollten hierbei Zeichenfolgen verwendet werden, um Joins zu vermeiden.
- Mastertabelle
- Eine Mastertabelle ist eine Tabelle, welche die Eigenschaften eines Objektes (Person, Adresse etc.) in getrennten Spalten ablegt. Kleine Mastertabellen sollten hierbei mit einer eindeutigen Zeichenfolge; bei großen Mastertabellen und Mastertabellen, deren Inhalt sich oft ändert, sollte eine Ganzzahl als Schlüssel angelegt werden.
- Transaktionstabelle
- Eine Transaktionstabelle ist eine Tabelle die Interaktionen oder Ereignisse zwischen Mastertabellen speichert. Beispielsweise eine Liste von Objekten, die ein Kunde in einen Warenkorb gelegt hat. Als Schlüssel sollten automatisch generierte Ganzzahlen verwendet werden.
- Querverweistabelle
- Eine Querverweistabelle ist eine Tabelle in der die Beziehungen zwischen Mastertabellen gespeichert werden. In Querverweistabellen werden n:n-Beziehungen in mehreren Zeilen abgebildet. Als Schlüssel sollte eine Kombination aus mehreren Spalten gewählt werden.
Erweiterte Tabellentypen
- Begrenzte Transaktion
- Als begrenzte Transaktion bezeichnet man eine Einschränkung auf einer Tabelle, die definiert welche Transaktionen wann zulässig sind. Dieses Muster kann eingesetzt werden um entsprechende Prüfungen auf der Anwendungsseite zu reduzieren und um die Sicherheit der Datenbank vor falsch implementierten Anwendungen zu erhöhen.
- Vergänglicher Primärschlüssel
- werden eingesetzt, wenn sich eine Eigenschaft eines Objektes als Primärschlüssel anbietet (z.B. eine Kundennummer), diese sich jedoch möglicherweise ändert. In diesem Fall kann die entsprechende Eigenschaft zwar als Primärschlüssel verwendet werden, Änderungen müssen jedoch in einer History-Tabelle protokolliert werden um auch eine nachträgliche Zuordnung gewährleisten zu können.
Muster für Fremdschlüssel
- Fremdschlüsselbegrenzung
- bezeichnet es, wenn das Löschen eines Eintrags (Zeile) aus einer Tabelle die mit dem Eintrag verknüpften Einträge (in einer anderen Tabelle) nicht mit löscht. Die Fremdschlüsselbegrenzung ist somit das Gegenteil der Fremdschlüsselkaskade.
- In SQL wird
eine Fremdschlüsselbegrenzung mit dem Befehl
DELETE RESTRICTangestoßen. Dieses Verhalten ist bei den meisten Datenbankimplementierungen das Standardverhalten, wenn nur der BefehlDELETEalleine angegeben wird. - Fremdschlüsselkaskade
- Eine Fremdschlüsselkaskade ist das Gegenteil der Fremdschlüsselbegrenzung. Beim Löschen eines Eintrags werden die mit dem Eintrag verknüpften Einträge mitgelöscht.
- In SQL wird eine Fremdschlüsselbegrenzung mit dem Befehl
DELETE CASCADEangestoßen. - Querverweisvalidierung
- Eine Querverweisvalidierung wird eingesetzt, wenn Spalten in einer Mastertabelle eine bestimmte Relation miteinander aufweisen müssen. Diese Relation wird in einer getrennten Querverweistabelle gespeichert. Durch die getrennte Querverweistabelle wird zwar der Ressourcenverbrauch der Datenbank erhöht, der Einsatz ist jedoch nötig um die Gültigkeit der Daten prüfen zu können.
Sicherheitsmuster
- Schreibgeschützte Lookup-Tabelle
- Eine schreibgeschützte Lookup-Tabelle ist eine Tabelle die eine Zuordnung zwischen zwei Tabellen definiert, deren Inhalt zwar allgemein abgefragt werden kann, jedoch nur von bestimmten Rollen bzw. Gruppen bearbeitet werden darf. Ein Beispiel ist die Verknüpfung von bestimmten Produkten mit einem Rabatt.
Denormalisierungsmuster
Denormalisierungsmuster ermöglichen die Denormalisierung einer Datenbank zum Zweck der Verbesserung des Laufzeitverhaltens.
- Fetching
- Beim Fetching werden Daten aus einer Tabelle in eine andere (temporäre) Tabelle (z.B. eine Transaktionstabelle) kopiert. Hierbei ist darauf zu achten, dass eine Änderung in der Quelltabelle nicht automatisch in die Zieltabelle übernommen wird.
- Vorweggenommene Aggregation
-
→ Hauptartikel: Vorweggenommene Aggregation
- Bei der vorweggenommenen Aggregation werden Werte aus verschiedenen Quellen bereits im Voraus im Zuge einer (lang laufenden) Stapelverarbeitung berechnet und in einer weiteren Tabelle zwischengespeichert. Die Werte werden dabei nicht bei jeder Abfrage neu berechnet, sondern erst im Zuge der nächsten Stapelverarbeitung. Der Vorteil ist, dass der Zugriff deutlich schneller ist und die Ressourcen der Datenbank geschont werden. Nachteilig wirkt sich aus, dass vor kurzem getätigte Änderungen an in der Berechnung nicht berücksichtigt sind.
- Erweiterung
- Eine Erweiterung der Tabelle liegt dann vor, wenn eine Spalte in der Tabelle durch die Berechnung aus anderen Spalten gebildet wird. Hierdurch muss die Berechnung nicht bei jeder Abfrage erneut durchgeführt werden, sondern erst wenn sich der Eintrag ändert.
Objekt-Relationale Verhaltensmuster
- Tabelle pro Vererbungshierarchie
- (englisch: Single Table Inheritance) verwendet eine einzige Tabelle für jede Klasse, um einen Klassenbaum in einer Datenbank abzubilden.
- Tabelle pro Unterklasse
- (englisch: Class Table Inheritance) verwendet eine eigene Tabelle für jede konkrete oder abstrakte Klasse, um einen Klassenbaum in einer Datenbank abzubilden.
- Tabelle pro konkrete Klasse
- (englisch: Concrete Table Inheritance) verwendet eine eigene Tabelle für jede konkrete Klasse, um einen Klassenbaum in einer Datenbank abzubilden.
-
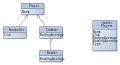 Tabelle pro Vererbungshierarchie
Tabelle pro Vererbungshierarchie -
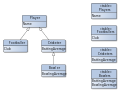 Tabelle pro Unterklasse
Tabelle pro Unterklasse -
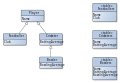 Tabelle pro konkrete Klasse
Tabelle pro konkrete Klasse
Verteilungsmuster
Bei den Verteilungsmustern wird im Wesentlichen zwischen keiner Verteilung, Replikation und Fragmentierung (englisch: Sharding) unterschieden:
- Die Replikation nimmt dieselben Teile der Daten und kopiert diese auf mehrere Server, um eine höhere Ausfallsicherheit zu gewährleisten.
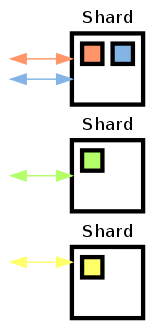
- Die Fragmentierung verteilt unterschiedliche Teile der Daten und verteilt diese über mehrere Server, um eine bessere Lastenverteilung zu gewährleisten.
Die Replikation kann hierbei mit Fragmentierung kombiniert werden. Zudem unterscheidet man bei der Replikation zwischen der Master/Slave-Replikation und der Peer-to-Peer-Replikation.
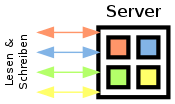
Single-Server-„Verteilung“ |
Verteilung
durch Fragmentierung |
Verteilung
mit Master/Slave-Replikation |
Verteilung
mit Peer-to-Peer Replikation |
Single-Server
Das einfachste Verteilungsmuster ist keine Verteilung. Die Datenbank läuft vollständig auf einem einzelnen Server, der sämtliche Schreib- und Lesezugriffe behandelt. Der Vorteil dieses Musters ist es, dass der Server einfach zu warten ist. Updates, Datensicherungen, Reparaturen, Upgrades etc. lassen sich bei diesem Muster zentral behandeln.
Zudem müssen Softwareentwickler keine aufwändige Logik implementieren um Probleme mit der Konsistenz, Verfügbarkeit oder Partitionierung zu behandeln (siehe auch: CAP-Theorem).
Diese Variante bietet sich auch besonders bei Graphdatenbanken an, da Latenzen durch den Zugriff von Daten über das Netzwerk vermieden werden.
Fragmentierung
Bei der Fragmentierung (englisch: Sharding) werden unterschiedliche Datenbanken bzw. voneinander unabhängige Teile der Datenbank auf verschiedene Server, die Shards, verteilt.
Hierdurch ergibt sich eine bessere Lastverteilung. Zudem fallen bei einem Ausfall des Servers nicht alle Applikationen aus, sondern nur jene die auf die jeweiligen Daten zugreifen oder schreiben müssen.
Da die Lese-und-Schreibzugriffe für jeweils bestimmte Daten vom jeweiligen Shard alleine bearbeitet werden, ergibt sich keine Inkonsistenz der Daten.
Federation
Als Federation bezeichnet man einen Spezialfall der Fragmentierung, bei dem ein zentraler Server, federation root genannt, die Verteilung der einzelnen Shards automatisch bestimmt.
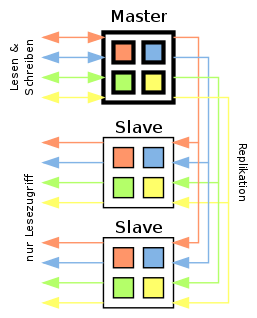
Master/Slave-Replikation
Bei der Master/Slave-Replikation übernimmt ein zentraler Server, der Master, alle Schreibzugriffe auf die Datenbank. Anschließend werden die Änderungen auf die anderen Server, den Slaves (Sklaven) übermittelt. Wenn der Master-Server ausfallen sollte, kann ein Slave die Rolle des Masters übernehmen.
Da es etwas dauert, bis die Änderungen von den Slave-Servern übernommen werden, kann es kurzzeitig zu Dateninkonsistenzen kommen.
Alle Server ermöglichen Lesezugriffe, wodurch es bei Lesezugriffen zu einer Lastverteilung kommt. Da Schreibzugriffe jedoch zentral bearbeitet werden, stellt der Master einen Flaschenhals dar.
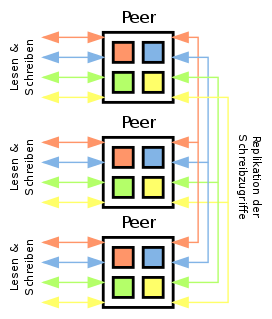
Peer-to-Peer-Replikation
Bei der Peer-to-Peer-Replikation, sind alle Server über ein Peer-to-Peer-Netzwerk verbunden. Jeder Server übernimmt sowohl Schreib- als auch Lesezugriffe. Schreibzugriffe werden hierbei mit allen Servern synchronisiert.
Da es jedoch einige Zeit dauert bis die Schreibzugriffe synchronisiert werden, kann es bei diesem Modell zu Dateninkonsistenzen kommen. Dieser Effekt tritt hier besonders zutage, wenn die Netzwerkverbindung zwischen zwei Standorten ausfällt.
Der Vorteil dieser Konfiguration ist, dass eine besonders hohe Ausfallsicherheit gegeben ist. Der Wegfall einzelner Peers führt nicht zu einem Datenverlust. Zudem ist dieses Modell leicht horizontal skalierbar, da bei Engpässen einfach weitere (kostengünstige) Rechner hinzugefügt werden können.
Die Peer-to-Peer-Replikation ist in der Softwareentwicklung und der Wartung (Updates, Backups etc.) besonders aufwändig und bedarf daher einer guten Planung seitens des Betreibers.
Fragmentierung mit Master-Slave-Replikation
Die Fragmentierung und Master-Slave-Replikation kann auch kombiniert werden. Hierbei werden für jeden Datentyp ein Master bestimmt und auf mehrere andere Server, welche hierbei dem Master als Slaves dienen, repliziert. Ein Server kann hierbei die Rolle des Masters für einen Datentyp und die Rolle des Slave für andere Datentypen gleichzeitig übernehmen.
Fragmentierung mit Peer-to-Peer-Replikation
Als letzte Möglichkeit bietet sich noch die Fragmentierung eines Peer-to-Peer-Netzwerkes an. Hierbei werden mehrere Server zusammengefasst um sich als Peer-to-Peer-Netzwerk um einen bestimmten Datentyp zu kümmern. Jeder Server kann hierbei Teil von mehreren Peer-to-Peer-Netzwerken sein und somit unterschiedliche Datentypen behandeln.
Weitere Muster
- Auflösungsmuster
- Das Auflösungsmuster wird eingesetzt, wenn ein Wert aus verschiedenen Quellen kommen bzw. berechnet werden kann und entschieden werden muss, welche Quelle gewählt wird bzw. welches Berechnungsmodell anzuwenden ist.
- History-Tabelle
- Eine History-Tabelle ist eine Tabelle die Änderungen protokolliert. Durch diese Tabelle sind Änderungen nachvollziehbar und der ursprüngliche Zustand der überwachten Tabelle wiederherstellbar. Ein Beispiel für eine History-Tabelle ist die „Versionsgeschichte“ der Wikipedia, in der Änderungen in Form von Diff-Elementen gespeichert werden.
- Abhängigkeitsseqenzierung
- Bei einer Abhängigkeitsseqenzierung muss eine Reihe von Befehlen in einer Sequenz abgearbeitet werden. Da einige Befehle vom Ergebnis anderer Befehle abhängig sein können, muss die korrekte Reihenfolge mit Hilfe eines gerichteten Analysegraphen (englisch: directed analytic graph) ermittelt und in einer eigenen Tabelle abgebildet werden.
- Sicheres Passwortrücksetzen
- Die Datenbank muss ein sicheres Zurücksetzen des Passwortes erlauben, falls der Benutzer das Passwort vergessen hat. Das Passwort darf weder im Klartext oder wiederherstellbar in der Datenbank gespeichert werden, noch darf das Passwort des Benutzers über einen unsicheren Kanal (z.B. etwa in einer E-Mail oder eine nicht mit SSL verschlüsselte Webseite) übermittelt werden.
Antimuster
- Umgekehrter Fremdschlüssel
Ein umgekehrter Fremdschlüssel (englisch reverse foreign key) entsteht, wenn ein bestimmter Eintrag einer Tabelle einen bestimmten Eintrag in einer anderen Tabelle verhindern soll. Ein Umgekehrter Fremdschlüssel sieht auf den ersten Blick oft wie ein Primärschlüssel aus.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 20.09. 2022