Gradientenverfahren
Das Gradientenverfahren wird in der Numerik eingesetzt, um allgemeine Optimierungsprobleme zu lösen. Dabei schreitet man (am Beispiel eines Minimierungsproblems) von einem Startpunkt aus entlang einer Abstiegsrichtung, bis keine numerische Verbesserung mehr erzielt wird. Wählt man als Abstiegsrichtung den negativen Gradient, also die Richtung des lokal steilsten Abstiegs, erhält man das Verfahren des steilsten Abstiegs. Manchmal werden die Begriffe Gradientenverfahren und Verfahren des steilsten Abstiegs synonym verwendet. Im Allgemeinen bezeichnet Gradientenverfahren eine Optimierungsmethode, bei der die Abstiegsrichtung durch Gradienteninformation gewonnen wird, also nicht notwendigerweise auf den negativen Gradient beschränkt ist.
Das Verfahren des steilsten Abstiegs konvergiert oftmals sehr langsam, da es sich dem stationären Punkt mit einem starken Zickzack-Kurs nähert. Andere Verfahren für die Berechnung der Abstiegsrichtung erreichen teils deutlich bessere Konvergenzgeschwindigkeiten, so bietet sich für die Lösung von symmetrisch positiv definiten linearen Gleichungssystemen beispielsweise das Verfahren der konjugierten Gradienten an. Der Gradientenabstieg ist mit dem Bergsteigeralgorithmus (hill climbing) verwandt.
Das Optimierungsproblem
Das Gradientenverfahren ist einsetzbar, um eine reellwertige,
differenzierbare Funktion  zu minimieren:
zu minimieren:

Hierbei handelt es sich um ein Problem der Optimierung ohne Nebenbedingungen, auch unrestringiertes Optimierungsproblem genannt.
Das Verfahren
Das Gradientenverfahren generiert ausgehend von einem Startpunkt  eine Folge von Punkten
eine Folge von Punkten  gemäß der Iterationsvorschrift
gemäß der Iterationsvorschrift

wobei  eine positive Schrittweite ist und
eine positive Schrittweite ist und  eine Abstiegsrichtung. Dabei werden sowohl
eine Abstiegsrichtung. Dabei werden sowohl  als auch
als auch  in jedem Iterationsschritt so bestimmt, dass die Folge
in jedem Iterationsschritt so bestimmt, dass die Folge  zu einem stationären
Punkt von
zu einem stationären
Punkt von  konvergiert.
konvergiert.
Bestimmen der Abstiegsrichtung
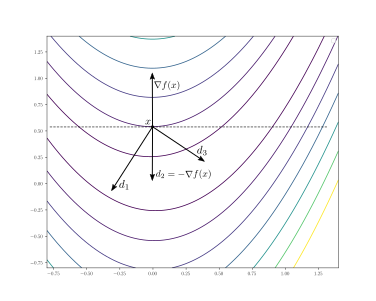
 haben einen Winkel größer als 90° mit dem Gradienten im Punkt
haben einen Winkel größer als 90° mit dem Gradienten im Punkt  .
Die strichlierte Gerade ist die Tangente an die Isolinie
der zweidimensionalen Funktion, sie stellt den Grenzfall dar bei dem der Winkel
mit dem Gradient 90° beträgt. Die Abstiegsrichtung
.
Die strichlierte Gerade ist die Tangente an die Isolinie
der zweidimensionalen Funktion, sie stellt den Grenzfall dar bei dem der Winkel
mit dem Gradient 90° beträgt. Die Abstiegsrichtung  zeigt in Richtung des negativen Gradienten, d.h. in Richtung des steilsten
Abstiegs.
zeigt in Richtung des negativen Gradienten, d.h. in Richtung des steilsten
Abstiegs.Eine Abstiegsrichtung im Punkt
ist ein Vektor ,
der

erfüllt. Intuitiv bedeutet das, dass der Winkel zwischen  und
größer als 90° ist. Da der Gradient
in Richtung des steilsten Anstiegs zeigt, ist
eine Richtung entlang derer sich der Funktionswert verringert.
und
größer als 90° ist. Da der Gradient
in Richtung des steilsten Anstiegs zeigt, ist
eine Richtung entlang derer sich der Funktionswert verringert.
Viele Gradientenmethoden berechnen die Abstiegsrichtung anhand

wobei  eine positiv
definite Matrix ist. In diesem Fall lautet die Bedingung für die
Abstiegsrichtung
eine positiv
definite Matrix ist. In diesem Fall lautet die Bedingung für die
Abstiegsrichtung

und ist dank der positiven Definitheit von
immer erfüllt.
Mit der Wahl der Matrix
erhält man folgende Algorithmen:
 ,
wobei
,
wobei  die Einheitsmatrix
ist, ergibt das Verfahren des steilsten Abstiegs. Die Absteigsrichtung
ist in diesem Fall einfach der negative Gradient,
die Einheitsmatrix
ist, ergibt das Verfahren des steilsten Abstiegs. Die Absteigsrichtung
ist in diesem Fall einfach der negative Gradient,  .
. ,
wobei
,
wobei  sodass
positiv definit ist, ist ein diagonal skalierter steilster Abstieg. Oft
werden die
sodass
positiv definit ist, ist ein diagonal skalierter steilster Abstieg. Oft
werden die  als Approximation der Inversen der 2. Ableitung gewählt, also
als Approximation der Inversen der 2. Ableitung gewählt, also  .
. ,
die Inverse Hesse-Matrix,
ergibt das Newton-Verfahren
für die Lösung nichtlinearer Minimierungsprobleme.
,
die Inverse Hesse-Matrix,
ergibt das Newton-Verfahren
für die Lösung nichtlinearer Minimierungsprobleme.- Da die Berechnung der Hesse-Matrix oft aufwändig ist, gibt es eine Klasse
von Algorithmen welche eine Approximation
 verwenden. Solche Methoden werden als Quasi-Newton-Verfahren
bezeichnet, es gibt verschiedene Arten wie die Approximation berechnet wird.
Ein wichtiger Vertreter aus der Klasse der Quasi-Newton Methoden ist der BFGS Algorithmus.
verwenden. Solche Methoden werden als Quasi-Newton-Verfahren
bezeichnet, es gibt verschiedene Arten wie die Approximation berechnet wird.
Ein wichtiger Vertreter aus der Klasse der Quasi-Newton Methoden ist der BFGS Algorithmus. - Falls das Optimierungsproblem in der speziellen Form
 ,
also als Summe von Quadraten von Funktionen, gegeben ist, erhält man mit
,
also als Summe von Quadraten von Funktionen, gegeben ist, erhält man mit  ,
wobei
,
wobei  die Jacobi-Matrix
von
im Punkt
ist, das Gauß-Newton-Verfahren.
die Jacobi-Matrix
von
im Punkt
ist, das Gauß-Newton-Verfahren.
Bestimmen der Schrittweite
Die Bestimmung der Schrittweite
ist ein wichtiger Teil des Gradientenverfahren, der großen Einfluss auf die
Konvergenz haben kann. Ausgehend vom Iterationsschritt  betrachtet man den Wert von
entlang der Linie
betrachtet man den Wert von
entlang der Linie  ,
also
,
also  .
Man spricht in diesem Zusammenhang oft auch von Liniensuche. Die
ideale Wahl wäre es, die Schrittweite als jenen Wert zu berechnen, der die
Funktion
.
Man spricht in diesem Zusammenhang oft auch von Liniensuche. Die
ideale Wahl wäre es, die Schrittweite als jenen Wert zu berechnen, der die
Funktion  minimiert, also das eindimensionale Problem
minimiert, also das eindimensionale Problem

zu lösen. Dies wird als exakte Liniensuche bezeichnet und wird in dieser Form in der Praxis selten angewandt, da selbst für einfache Optimierungsprobleme die exakte Bestimmung der Schrittweite sehr rechenaufwändig ist.
Als Alternative zur exakten Liniensuche lockert man die Erfordernisse und
beschränkt sich darauf, dass der Funktionswert sich mit jedem Iterationsschritt
„genügend“ verringert. Dies wird auch als inexakte Liniensuche
bezeichnet. Die einfachste Möglichkeit besteht darin, die Schrittweite  ausgehend von einem Startwert (z.B.
ausgehend von einem Startwert (z.B.  )
so lange zu verringern, bis
)
so lange zu verringern, bis  erreicht ist. Diese Methode funktioniert in der Praxis oft zufriedenstellend,
man kann jedoch zeigen, dass für manche pathologischen Funktionen diese
Liniensuche zwar in jedem Schritt den Funktionswert verringert, die Folge
jedoch nicht zu einem stationärem Punkt konvergiert.
erreicht ist. Diese Methode funktioniert in der Praxis oft zufriedenstellend,
man kann jedoch zeigen, dass für manche pathologischen Funktionen diese
Liniensuche zwar in jedem Schritt den Funktionswert verringert, die Folge
jedoch nicht zu einem stationärem Punkt konvergiert.
Armijo-Bedingung
Die Armijo-Bedingung formalisiert das Konzept "genügend" in der geforderten
Verringerung des Funktionswertes. Die Bedingung  wird modifiziert zu
wird modifiziert zu

mit  .
Die Armijo-Bedingung umgeht die Konvergenzprobleme aus der vorigen einfachen
Bedingung, indem sie fordert dass die Verringerung zumindest proportional zur
Schrittweite und zur Richtungsableitung
.
Die Armijo-Bedingung umgeht die Konvergenzprobleme aus der vorigen einfachen
Bedingung, indem sie fordert dass die Verringerung zumindest proportional zur
Schrittweite und zur Richtungsableitung
 ist, mit Proportionalitätskonstante
ist, mit Proportionalitätskonstante  .
In der Praxis werden oft sehr kleine Werte verwendet, z.B.
.
In der Praxis werden oft sehr kleine Werte verwendet, z.B.  .
.
Backtracking Liniensuche
Die Armijo-Bedingung gilt immer dann, wenn die Schrittweite genügend klein ist und kann damit zum Stillstand des Gradientenverfahrens führen – der Schritt ist so klein, dass kein nennenswerter Fortschritt mehr gemacht wird. Eine einfache Kombination aus wiederholter Verkleinerung der Schrittweite und der Armijo-Bedingung ist die Backtracking-Liniensuche. Sie stellt sicher, dass die Schrittweite klein genug ist, um die Armijo-Bedingung zu erfüllen, andererseits aber nicht zu klein. In Pseudocode:
Wähle Startwert für
while
end
Setze
Die Backtracking-Liniensuche verringert die Schrittweite wiederholt um den
Faktor  ,
bis die Armijo-Bedingung erfüllt ist. Sie terminiert garantiert nach einer
endlichen Anzahl von Schritten und wird wegen ihrer Einfachheit oft in Praxis
verwendet.
,
bis die Armijo-Bedingung erfüllt ist. Sie terminiert garantiert nach einer
endlichen Anzahl von Schritten und wird wegen ihrer Einfachheit oft in Praxis
verwendet.
Konvergenz
Im Allgemeinen konvergiert das Gradientenverfahren weder zu einem globalen
noch zu einem lokalen Minimum. Garantiert werden kann nur die Konvergenz zu
einem stationären
Punkt, also einem Punkt  mit
mit
 .
Schränkt man die Klasse der Zielfunktionen auf konvexe Funktionen
ein, so sind stärkere Garantien möglich,
siehe konvexe
Optimierung.
.
Schränkt man die Klasse der Zielfunktionen auf konvexe Funktionen
ein, so sind stärkere Garantien möglich,
siehe konvexe
Optimierung.
Konvergenzgeschwindigkeit
Für den allgemeinen Fall kann weder über die Konvergenzgeschwindigkeit der
Folge  noch über die Konvergenzgeschwindigkeit der Folge
noch über die Konvergenzgeschwindigkeit der Folge  eine Aussage getroffen werden. Ist
eine Aussage getroffen werden. Ist  eine Lipschitz-Konstante
von
eine Lipschitz-Konstante
von  ,
so kann man zeigen, dass die Norm der Gradienten
,
so kann man zeigen, dass die Norm der Gradienten  mit der Rate
mit der Rate  gegen 0 konvergiert, wobei
gegen 0 konvergiert, wobei  eine positive Konstante ist.
eine positive Konstante ist.
Beispiel
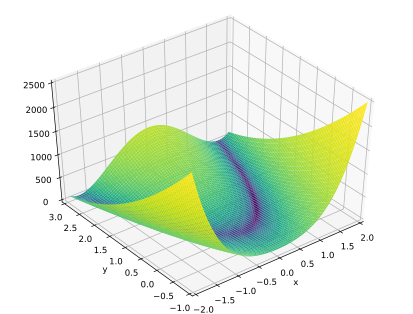

Die Rosenbrock-Funktion

wird häufig als Test für Optimierungsmethoden verwendet, da sie wegen des
schmalen und flachen Tals, in welchem iterative Methoden nur kleine Schritte
machen können, eine Herausforderung darstellt. Die Konstanten werden
üblicherweise mit
gewählt, das globale Optimum liegt in diesem Fall bei  mit dem Funktionswert
mit dem Funktionswert  .
.
Der Gradient sowie die Hesse-Matrix ergeben sich als

sowie
 .
.
Damit lassen sich die Algorithmen Verfahren des steilsten Abstiegs und Newton-Verfahren direkt implementieren. Um das Gauß-Newton-Verfahren anzuwenden, muss die Rosenbrock-Funktion zunächst in die Form „Summe von Quadraten von Funktionen“ gebracht werden. Dies ist auf der Seite zum Gauß-Newton-Verfahren im Detail erklärt.
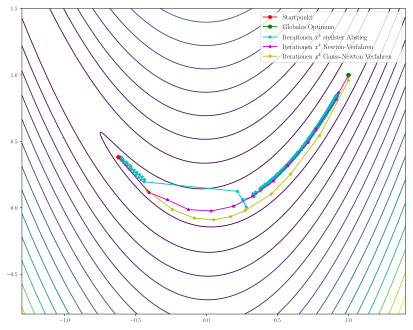
Für die Liniensuche kommt bei allen Verfahren ein Backtracking mit folgenden
Parametern zum Einsatz: Startwert ,
 .
Als Startpunkt wird
.
Als Startpunkt wird  gewählt.
gewählt.
Das Verfahren des steilsten Abstiegs findet auch nach 1000 Iterationen nicht zum globalen Optimum und steckt in dem flachen Tal fest, wo nur sehr kleine Schritte möglich sind. Im Gegensatz dazu finden sowohl das Newton-Verfahren als auch der Gauß-Newton- Algorithmus in wenigen Iterationen zum globalen Optimum.
Siehe auch


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 11.02. 2023