Residuenquadratsumme
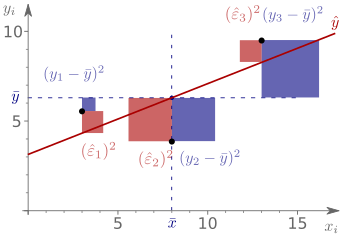
Die Residuenquadratsumme, Quadratsumme der Residuen, oder auch Summe der Residuenquadrate, bezeichnet in der Statistik die Summe der quadrierten (Kleinste-Quadrate-)Residuen (Abweichungen zwischen Beobachtungswerten und den vorhergesagten Werten) aller Beobachtungen. Da zunächst Abweichungsquadrate (hier Residuenquadrate) gebildet werden und dann über alle Beobachtungen summiert wird, stellt sie eine Abweichungsquadratsumme dar. Die Residuenquadratsumme ist ein Gütekriterium für ein lineares Modell und beschreibt die Ungenauigkeit des Modells. Sie erfasst die Streuung der Beobachtungswerte um die vorhergesagten Werte der Zielgröße, also die Streuung, die durch die Stichproben-Regressionsgerade nicht erklärt werden kann. Sie wird daher auch als die nicht erklärte Abweichungsquadratsumme (oder kurz nicht erklärte Quadratsumme) bezeichnet. Neben der Residuenquadratsumme spielt in der Statistik auch die totale Quadratsumme und die erklärte Quadratsumme eine große Rolle.
Um einen globalen F-Test durchzuführen, sind oft mittlere Abweichungsquadrate von Interesse. Dividiert man die Residuenquadratsumme durch die residualen Freiheitsgrade, erhält man das mittlere Residuenquadrat. Die Teststatistik eines globalen F-Tests ist dann gegeben durch den Quotienten aus dem „mittleren Quadrat der erklärten Abweichungen“ und dem „mittleren Residuenquadrat“.
Abkürzungs- und Bezeichnungsproblematik
Über die genaue Bezeichnung und ihre Abkürzungen gibt es international keine Einigkeit. Die natürliche deutsche Abkürzung für die Residuenquadratsumme bzw. die Summe der (Abweichungs-)Quadrate der Restabweichungen (oder: „Residuen“), ist SAQRest, oder SQR. Die englische Abkürzung SSR ist vieldeutig und führt zu anhaltenden Verwechslungen: Sowohl Sum of Squared Residuals (Residuenquadratsumme) als auch Sum of Squares due to Regression (Regressionsquadratsumme) werden als SSR abgekürzt. Allerdings wird die Regressionsquadratsumme oft auch als erklärte Quadratsumme (Sum of Squares Explained) bezeichnet, deren natürliche englische Abkürzung SSE ist. Die Abkürzungsproblematik wird dadurch verschärft, dass die Residuenquadratsumme oft auch als Fehlerquadratsumme (Sum of Squares Error) bezeichnet wird, deren natürliche englische Abkürzung ebenfalls SSE ist (diese Bezeichnung ist besonders irreführend, da die Fehler und die Residuen unterschiedliche Größen sind). Des Weiteren findet sich für Residuenquadratsumme ebenfalls die englische Abkürzung RSS, statt der Abkürzung SSR, da statt der Bezeichnung Sum of Squared Residuals, oft auch die Bezeichnung Residual Sum of Squares verwendet wird. Auch diese englische Abkürzung kann mit der Regressionsquadratsumme verwechselt werden, die im Englischen auch als Regression Sum of Squares bezeichnet, deren natürliche englische Abkürzung auch hier RSS ist.
Definition
Die Residuenquadratsumme ist definiert durch die Summe der Quadrate der Restabweichungen bzw. Residuen:
 .
.
Die zweite Gleichheit gilt, da  .
.
Einfache lineare Regression
In der einfachen linearen Regression (Modell mit nur einer erklärenden Variablen) lässt sich die Residuenquadratsumme auch wie folgt ausdrücken:

Hierbei stellen die  die Residuen dar und
die Residuen dar und  ist die Schätzung des Absolutglieds
und
ist die Schätzung des Absolutglieds
und  die Schätzung des Steigungsparameters. Die Methode der
kleinsten Quadrate versucht hier die Residuenquadratsumme zu minimieren
(vgl. Minimierung
der Summe der Fehlerquadrate). Ein spezielleres Konzept ist die PRESS-Statistik, auch
prädiktive Residuenquadratsumme (englisch
predictive residual sum of squares) genannt.
die Schätzung des Steigungsparameters. Die Methode der
kleinsten Quadrate versucht hier die Residuenquadratsumme zu minimieren
(vgl. Minimierung
der Summe der Fehlerquadrate). Ein spezielleres Konzept ist die PRESS-Statistik, auch
prädiktive Residuenquadratsumme (englisch
predictive residual sum of squares) genannt.
Es lässt sich zeigen, dass in der einfachen linearen Regression die Residuenquadratsumme wie folgt angegeben werden kann (für einen Beweis, siehe Erklärte Quadratsumme#Einfache lineare Regression)
 ,
,
wobei  die totale Quadratsumme und
die totale Quadratsumme und  den Bravais-Pearson-Korrelationskoeffizienten
darstellt.
den Bravais-Pearson-Korrelationskoeffizienten
darstellt.
Multiple lineare Regression
Die gewöhnlichen Residuen, die durch die Kleinste-Quadrate-Schätzung gewonnen werden, sind in der multiplen linearen Regression gegeben durch
 ,
,
wobei  der Kleinste-Quadrate-Schätzvektor ist. Die Residuenquadratsumme ergibt sich
also aus dem Produkt zwischen dem transponierten Residualvektor
der Kleinste-Quadrate-Schätzvektor ist. Die Residuenquadratsumme ergibt sich
also aus dem Produkt zwischen dem transponierten Residualvektor  und dem nicht-transponierten Residualvektor
und dem nicht-transponierten Residualvektor 
 .
.
Alternativ lässt sie sich auch schreiben als:

Die Residuenquadratsumme lässt sich mittels der residuenerzeugenden Matrix auch darstellen als:
 .
.
Dies zeigt, dass die Residuenquadratsumme eine quadratische Form der theoretischen Störgrößen ist. Eine alternative Darstellung als eine quadratische Form der y-Werte ist
 .
.
Rechenbeispiel
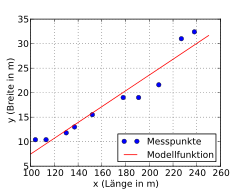
Folgendes Beispiel soll die Berechnung der Residuenquadratsumme zeigen. Es wurden zufällig zehn Kriegsschiffe ausgewählt und bezüglich ihrer Länge und Breite (in Metern) analysiert. Es soll untersucht werden, ob die Breite eines Kriegsschiffs möglicherweise in einem festen Bezug zur Länge steht.
Das Streudiagramm
lässt einen linearen Zusammenhang zwischen Länge und Breite eines Schiffs
vermuten. Eine mittels der Kleinste-Quadrate-Schätzung
durchgeführte einfache lineare Regression ergibt für das Absolutglied  und die Steigung
und die Steigung  (für die Berechnung der Regressionsparameter siehe Beispiel
mit einer Ausgleichsgeraden). Die geschätzte Regressionsgerade lautet somit
(für die Berechnung der Regressionsparameter siehe Beispiel
mit einer Ausgleichsgeraden). Die geschätzte Regressionsgerade lautet somit
 .
.
Die Gleichung stellt die geschätzte Breite  als Funktion der Länge
als Funktion der Länge  dar. Die Funktion zeigt, dass die Breite der ausgewählten Kriegsschiffe grob
einem Sechstel ihrer Länge entspricht.
dar. Die Funktion zeigt, dass die Breite der ausgewählten Kriegsschiffe grob
einem Sechstel ihrer Länge entspricht.
| Kriegsschiff | Länge (m) | Breite (m) | 
|

|

|

|

|
|---|---|---|---|---|---|---|---|

|

|

|

|

|

|

|

|
| 1 | 208 | 21,6 | 3,19 | 10,1761 | 24,8916 | −3,2916 | 10,8347 |
| 2 | 152 | 15,5 | −2,91 | 8,4681 | 15,8625 | −0,3625 | 0,1314 |
| 3 | 113 | 10,4 | −8,01 | 64,1601 | 9,5744 | 0,8256 | 0,6817 |
| 4 | 227 | 31,0 | 12,59 | 158,5081 | 27,9550 | 3,045 | 9,2720 |
| 5 | 137 | 13,0 | −5,41 | 29,2681 | 13,4440 | −0,4440 | 0,1971 |
| 6 | 238 | 32,4 | 13,99 | 195,7201 | 29,7286 | 2,6714 | 7,1362 |
| 7 | 178 | 19,0 | 0,59 | 0,3481 | 20,0546 | −1,0546 | 1,1122 |
| 8 | 104 | 10,4 | −8,01 | 64,1601 | 8,1233 | 2,2767 | 5,1835 |
| 9 | 191 | 19,0 | 0,59 | 0,3481 | 22,1506 | −3,1506 | 9,9265 |
| 10 | 130 | 11,8 | −6,61 | 43,6921 | 12,3154 | −0,5154 | 0,2656 |
| Σ | 1678 | 184,1 | 574,8490 | 0,0000 | 44,7405 | ||
| Σ/n | 167,8 | 18,41 | 57,48490 | 0,0000 | 4,47405 |
Aus der Tabelle lässt neben der totalen
Quadratsumme der Messwerte  auch die Residuenquadratsumme (letzte Spalte)
auch die Residuenquadratsumme (letzte Spalte)  ablesen. Auf diesen beiden Größen aufbauend lässt sich ebenfalls das Bestimmtheitsmaß
berechnen (siehe auch Bestimmtheitsmaß#Rechenbeispiel).
ablesen. Auf diesen beiden Größen aufbauend lässt sich ebenfalls das Bestimmtheitsmaß
berechnen (siehe auch Bestimmtheitsmaß#Rechenbeispiel).
Eigenschaften der Residuenquadratsumme
Verteilung der Residuenquadratsumme
Wenn die Beobachtungen mehrdimensional
normalverteilt sind, dann gilt für den Quotienten aus der
Residuenquadratsumme  und der Störgrößenvarianz
und der Störgrößenvarianz  ,
dass er einer Chi-Quadrat-Verteilung
mit
,
dass er einer Chi-Quadrat-Verteilung
mit  (mit
(mit  )
Freiheitsgraden folgt:
)
Freiheitsgraden folgt:
 ,
,
wobei  die erwartungstreue
Schätzung der Varianz der Störgrößen darstellt.
die erwartungstreue
Schätzung der Varianz der Störgrößen darstellt.
Erwartungswert der Residuenquadratsumme
Man kann zeigen, dass der Erwartungswert der Residuenquadratsumme  ergibt
ergibt
 ,
,
wobei  die Anzahl der Freiheitsgrade
der Residuenquadratsumme und
die Störgrößenvarianz ist. Daraus lässt sich schließen, dass der erwartungstreue
Schätzer für die unbekannte skalare Störgrößenvarianz gegeben sein muss durch
die Anzahl der Freiheitsgrade
der Residuenquadratsumme und
die Störgrößenvarianz ist. Daraus lässt sich schließen, dass der erwartungstreue
Schätzer für die unbekannte skalare Störgrößenvarianz gegeben sein muss durch
 .
.
Mittleres Residuenquadrat
Wenn man die Residuenquadratsumme durch die Anzahl der Freiheitsgrade dividiert, dann erhält man als mittleres Abweichungsquadrat das „mittlere Residuenquadrat“ (Mittleres Quadrat der Residuen, kurz: MQR)
 .
.
Die Quadratwurzel des mittleren Residuenquadrats ist der Standardfehler der Regression. In der linearen Einfachregression, die den Zusammenhang zwischen der Einfluss- und der Zielgröße mithilfe von zwei Regressionsparametern herstellt ist das mittlere Residuenquadrat gegeben durch
 .
.
Gewichtete Residuenquadratsumme
In der verallgemeinerten Kleinste-Quadrate-Schätzung und anderen Anwendungen wird oft eine gewichtete Version der Residuenquadratsumme verwendet
 ,
,
wobei  die Gewichtsmatrix
darstellt.
die Gewichtsmatrix
darstellt.
Penalisierte Residuenquadratsumme
Im Kontext von penalisierten Splines (kurz: P-Splines) wird eine sogenannte penalisierte Residuenquadratsumme verwendet, die approximativ der gewöhnlichen Residuenquadratsumme entspricht.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 03.02. 2022