ANSI-SPARC-Architektur
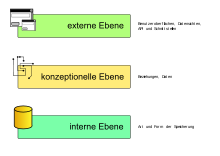
Die ANSI-SPARC-Architektur (auch Drei-Schema-Architektur, Drei-Ebenen-Architektur oder Drei-Ebenen-Schema-Architektur) beschreibt die grundlegende Trennung verschiedener Beschreibungsebenen für Datenbankschemata.
Die Architektur wurde 1975 vom Standards Planning and Requirements Committee (SPARC) des American National Standards Institute (ANSI) entwickelt und hat das Ziel, den Benutzer einer Datenbank vor nachteiligen Auswirkungen von Änderungen in der Datenbankstruktur zu schützen.
Die drei Ebenen sind:
- Die externe Ebene, die den Benutzern und Anwendungen individuelle Benutzersichten bereitstellt. Beispiele: Formulare, Masken-Layouts, Listen, Schnittstellen.
- Die konzeptionelle Ebene, in der beschrieben wird, welche Daten in der Datenbank gespeichert sind, sowie deren Beziehungen zueinander. Designziel ist hier eine vollständige und redundanzfreie Darstellung aller zu speichernden Informationen. Hier findet die Normalisierung des relationalen Datenbankschemas statt.
- Die interne Ebene (auch physische Ebene), die die physische Sicht der Datenbank im Computer darstellt. In ihr wird beschrieben, wie und wo die Daten in der Datenbank gespeichert werden. Designziel ist hier ein effizienter Zugriff auf die gespeicherten Informationen. Das wird meistens nur durch eine bewusst in Kauf genommene Redundanz erreicht (z.B. im Index werden die gleichen Daten gespeichert, die auch schon in der Tabelle gespeichert sind).
Die Vorteile des Drei-Ebenen-Modells liegen in der
- physischen Datenunabhängigkeit, da die interne von der konzeptionellen und externen Ebene getrennt ist. Physische Änderungen, z.B. des Speichermediums oder des Datenbankprodukts, wirken sich nicht auf die konzeptionelle oder externe Ebene aus.
- logischen Datenunabhängigkeit, da die konzeptionelle und die externe Ebene getrennt sind. Dies bedeutet, dass Änderungen an der Datenbankstruktur (konzeptionelle Ebene) keine Auswirkungen auf die externe Ebene, also die Masken-Layouts, Listen und Schnittstellen haben.
Allgemein kann also von einer höheren Robustheit gegenüber Änderungen gesprochen werden.
Beispiel Data-Warehouse
Die Unterschiede zwischen den drei Ebenen können gut anhand der Data-Warehouse-Architektur erläutert werden.
In der externen Ebene sind umfangreiche Aggregationen definiert, deren Berechnung sehr zeitaufwändig ist.
Die konzeptionelle Ebene definiert die redundanzfreien Basis-Tabellen als Dimensions-, Fakten- und Lookup-Tabellen.
Auf der internen Ebene werden die Basis-Tabellen oft in denormalisierter Form erstellt, um performance-günstige Zugriffe auf die gespeicherten Daten zu ermöglichen. Zusätzlich werden oft Aggregationstabellen eingerichtet. Um die geforderten Aggregationen schnell abrufen zu können, werden in der Nacht alle performance-intensiven Aggregationen berechnet. Die Ergebnisse der nächtlichen Berechnungen werden in den Aggregations-Tabellen abgelegt. Wenn ein Anwender während des Tages eine Aggregation aufruft, dann kann das System die Ergebnisse sekundenschnell aus den Aggregations-Tabellen auslesen. Die Aggregations-Tabellen blähen das Datenvolumen der internen Ebene enorm auf. Es ist im Durchschnitt sechsmal größer als das Volumen der Basis-Tabellen. Zusätzlich wird oft eine Staging-Area eingerichtet, in der alle aus Zuliefersystemen importierten Daten zunächst zwischengespeichert werden, bevor sie mit weiteren Informationen angereichert werden und schließlich in die Dimensions- und Fakten-Tabellen eingefügt oder ergänzt werden.
Literatur
- Gunter Saake, Kai-Uwe Sattler, Andreas Heuer: Datenbanken: Implementierungstechniken. mitp Professional, Frechen 2011, ISBN 3-8266-9156-3.
- Theo Härder: Datenbanksysteme. Springer, Berlin 2001, ISBN 3-540-42133-5.


© biancahoegel.de
Datum der letzten Änderung: Jena, den: 15.05. 2020